 Привет, друзья. Первая часть заголовка подсказывает, что ниже будет инструкция из разряда — для дилетантов, которым использование кавычек, минуса или восклицательного знака будет казаться взломом поисковой системы или как минимум секретными операторами. Я, и правда, планировал перечислить несколько базовых операторов, известных большинству seo-специалистов, но в процессе обнаружился ряд интересных особенностей, когда операторы работали не так, как предполагалось, либо модификации и сочетание простых операторов выдавали совсем необычные результаты. Так что, работая над данным постом, я получил интересный опыт и открыл несколько вещей, о которых прежде не догадывался.
Привет, друзья. Первая часть заголовка подсказывает, что ниже будет инструкция из разряда — для дилетантов, которым использование кавычек, минуса или восклицательного знака будет казаться взломом поисковой системы или как минимум секретными операторами. Я, и правда, планировал перечислить несколько базовых операторов, известных большинству seo-специалистов, но в процессе обнаружился ряд интересных особенностей, когда операторы работали не так, как предполагалось, либо модификации и сочетание простых операторов выдавали совсем необычные результаты. Так что, работая над данным постом, я получил интересный опыт и открыл несколько вещей, о которых прежде не догадывался.
Даже если кажется, что вам известны все поисковые операторы и их свойства, рекомендую ознакомиться с постом.
Кроме этого, вторая половина поста состоит из рассмотрения ряда прикладных задач, которые доводилось решать мне и моим коллегам в процессе работы над клиентскими сайтами. Уверен, вы найдете для себя много полезного.
В SEO есть список ключевых операторов ПС, которые необходимо знать наизусть, так как они используются постоянно и позволяют мгновенно проверять возникающие гипотезы.
Также есть операторы, которые редко используются, но знать об их существовании важно, чтобы в случае необходимости вспомнить, что вопрос решается элементарно, стоит лишь использовать нужный запрос.
Основная сложность заключается в приобретении навыка умелого сочетания простых элементов между собой с целью решения неочевидных на первый взгляд задач.
Поисковый запрос проходит через сервис исправления опечаток, по результатам которого и формируется выдача. Учитывается статистика по запросу, статистика совместной встречаемости слов, вероятность ошибки – и в итоге имеем то, что имеем.
Общие операторы для Яндекс и Google
Оператор + (плюс) и - (минус)
С помощью этих операторов происходит поиск документов, которые обязательно содержат (или не содержат) указанное слово (или слова). Однако же на практике есть отличия от теории.
Оператор «минус» отрабатывает при любых условиях – «заминусованное» слово никогда не попадет в выдачу.
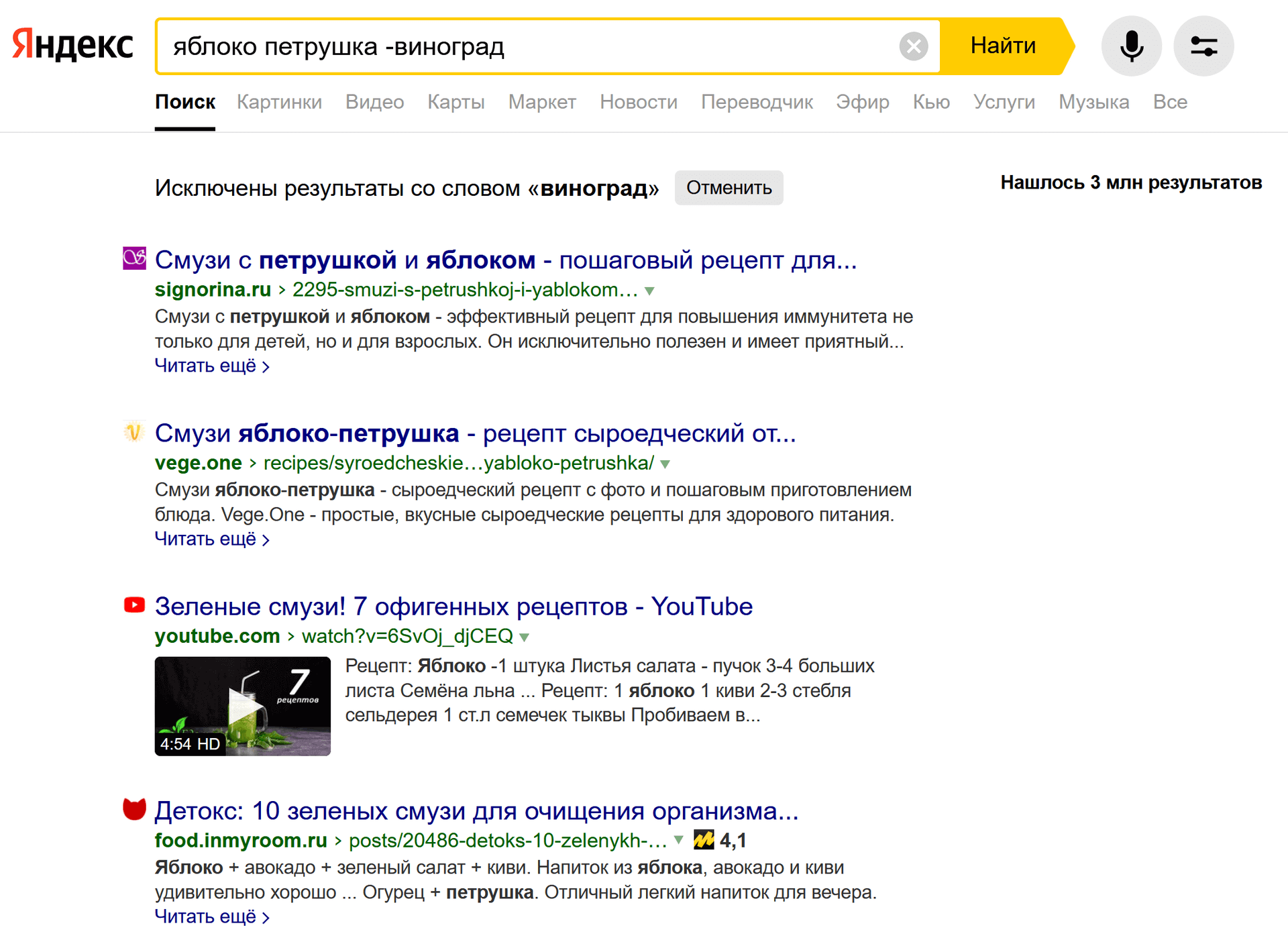
Что касается оператора «плюс», сегодня у меня сложилось впечатление, что он просто не работает.
С одной стороны логично: если ты указал какое-то слово в поисковом запросе — ты хочешь его найти, и нет нужды что-то дополнительно отмечать плюсом. С другой стороны, если мы отмечаем одно слово в многословном запросе плюсом, можно было бы придавать ему максимальное значение при ранжировании, но мои попытки заметить хоть какую-то закономерность не увенчались успехом.
Например, поисковиками игнорируются союзы и предлоги из запроса, но можно было их «вернуть» как раз плюсом. Это работает в вордстате – сравните результат для вариантов «продвижение» и «продвижение +в». При этом, если во втором варианте вы уберете плюс перед «в», получите результат такой, как будто «в» вообще отсутствует.
Так же это работало и в обычном поиске, но, похоже, что-то изменилось.
Оператор " " (кавычки)
При использовании кавычек поисковая система будет искать точное совпадение фразы.
Можно использовать кавычки несколько раз в одном запросе и даже добавить «минус» перед одним из запросов.
Этот оператор тоже сложно назвать полезным, так как не понятно, как он работает на практике. Вот вам пример:
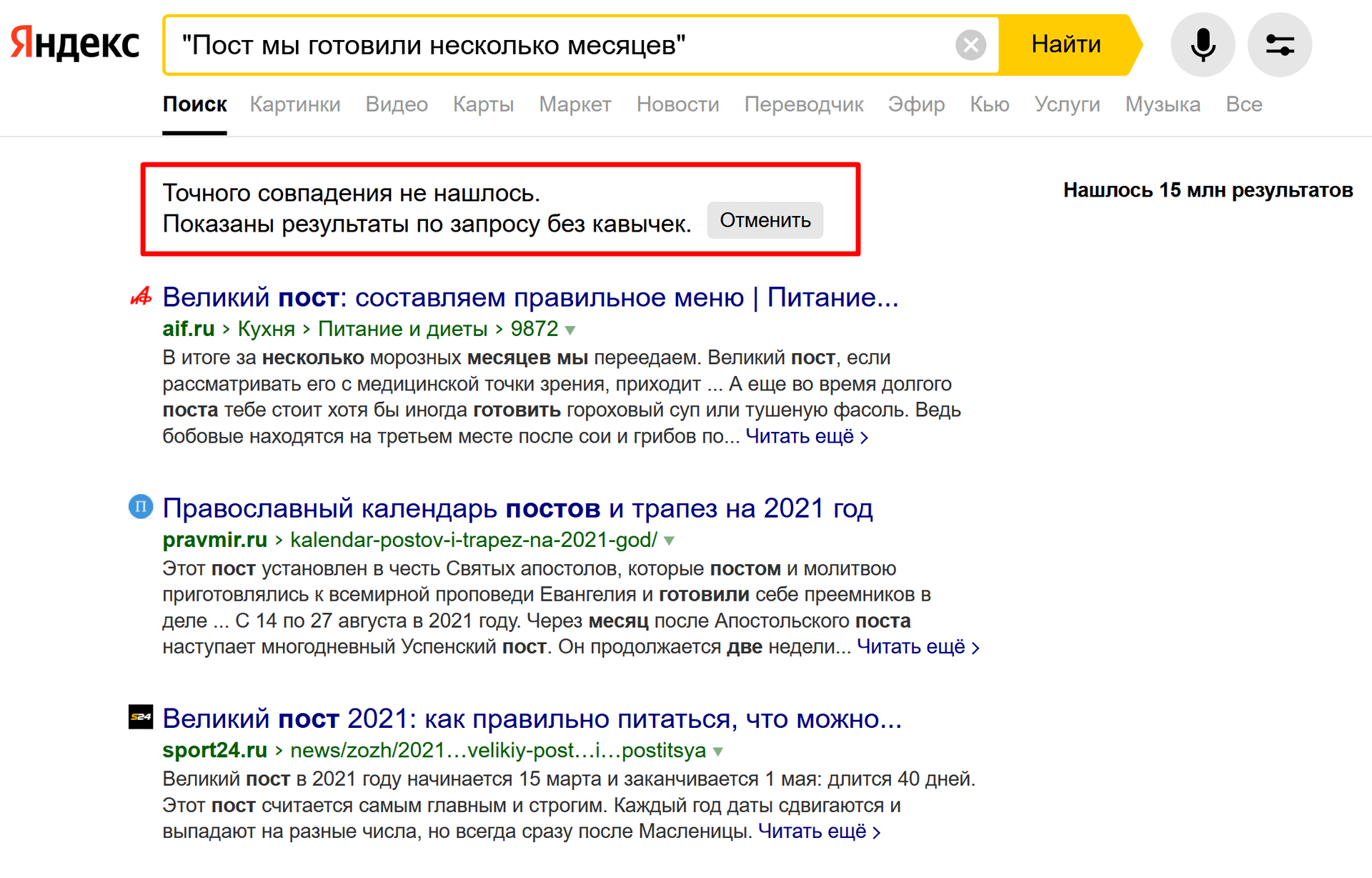
Яндекс говорит: «Точного совпадения не нашлось. Показаны результаты по запросу без кавычек.»
Фраза содержится в одном из последних постов на моем блоге, который точно в индексе, что подтверждается поиском по соседнему с искомой фразой предложению:

Обратите внимание, что в сниппете есть та самая фраза, которую мы изначально искали, но не нашли. Как это работает — одному Яндексу известно, так что я бы не стал полагаться на данный оператор.
Зачем я рассказываю о как бы нерабочих операторах? А затем, что знание особенностей (а точнее того, что операторы не всегда работают так, как заявлено) очень важно, чтобы однажды не наделать ложных выводов.
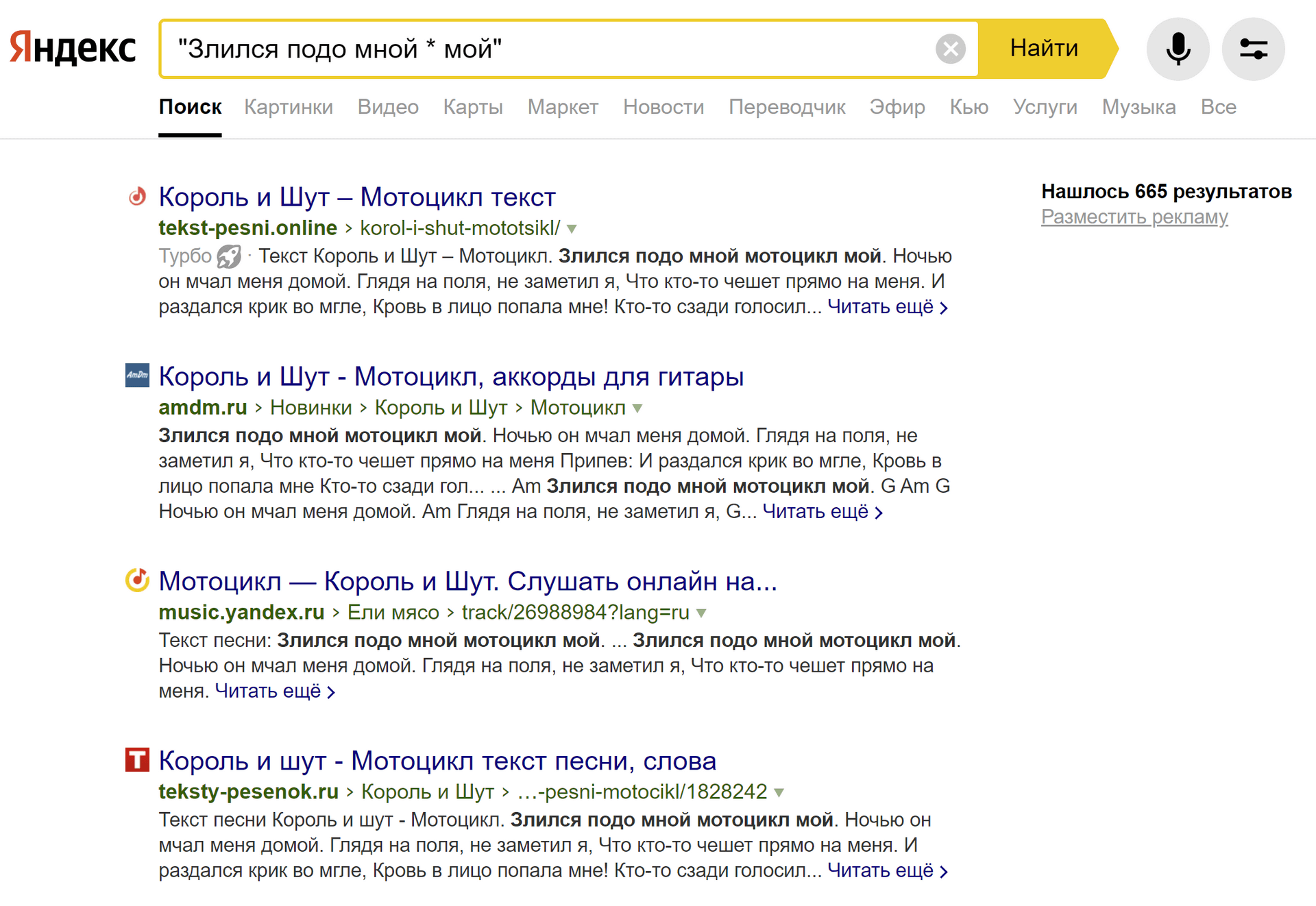
Оператор * (звёздочка)
В Яндексе используется для указания пропущенного слова в цитате.
Одна звездочка – одно слово. Применяется только с оператором " " (кавычки).
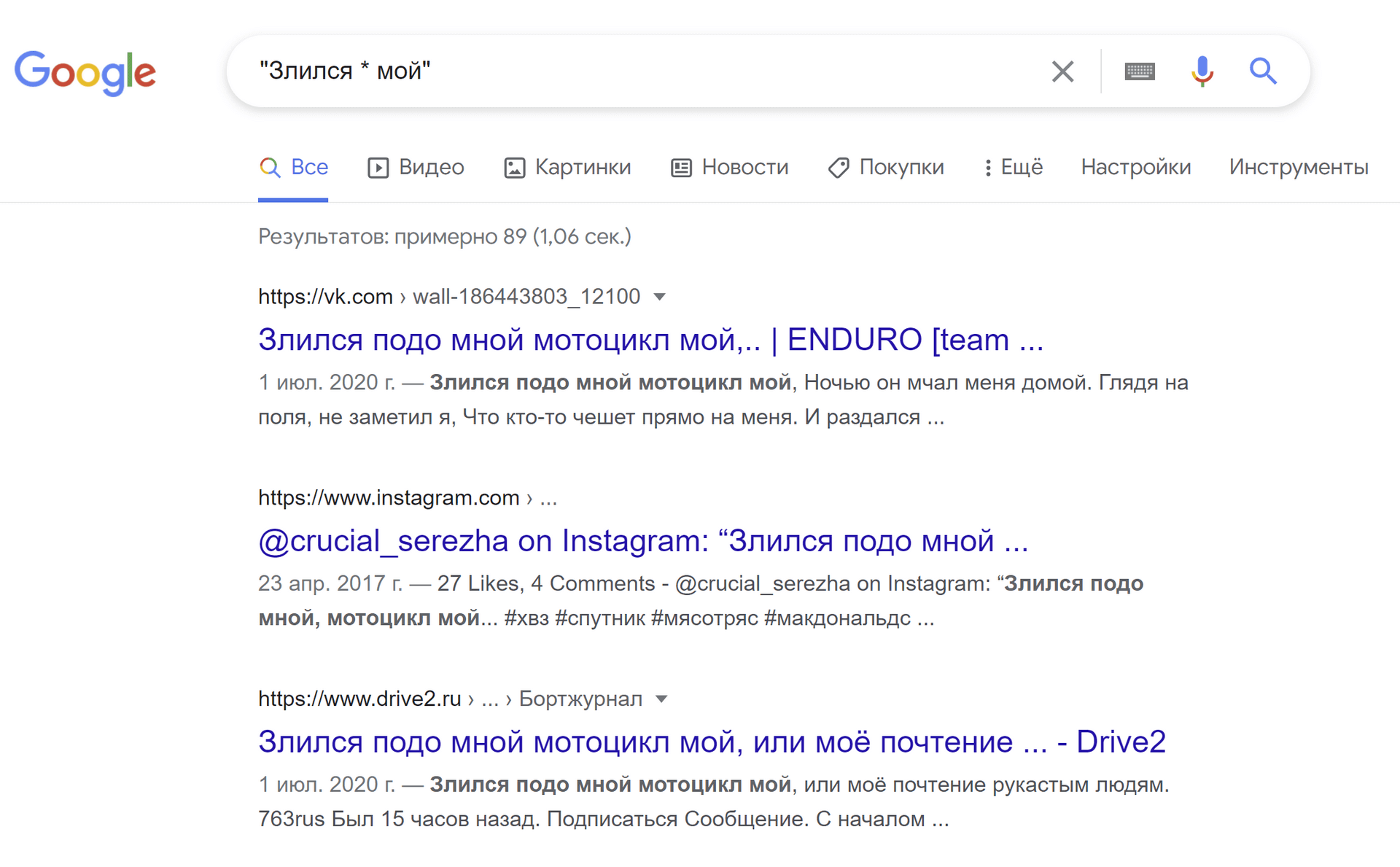
В Гугле используется для указания пропущенных слов в запросе. В справке указано, что одного слова, но на практике – любое количество слов.
Оператор ! (восклицательный знак)
Осуществляет поиск документов, где слово содержится строго в заданной форме. В Гугле все четко:

В Яндексе это так не работает и, кажется, он считает накопленную статистику о том, как правильно задавать запросы, приоритетной перед поисковыми операторами.
То есть, согласно статистике, человек ошибся, написав «билет в москвА», вместо «билет в москвУ». Чуть лучше это работает с запросами «"купить !айфон"» и «"купить !iphone"», но тоже не так четко, как ожидаешь.
Оператор site:
Осуществляет поиск только по указанному домену и его поддоменам (в отличии от оператора url:, который ограничивает поиск только страницами указанного сайта).
формат: [фраза] site:[example.com]
пример: сайт site:narod.ru
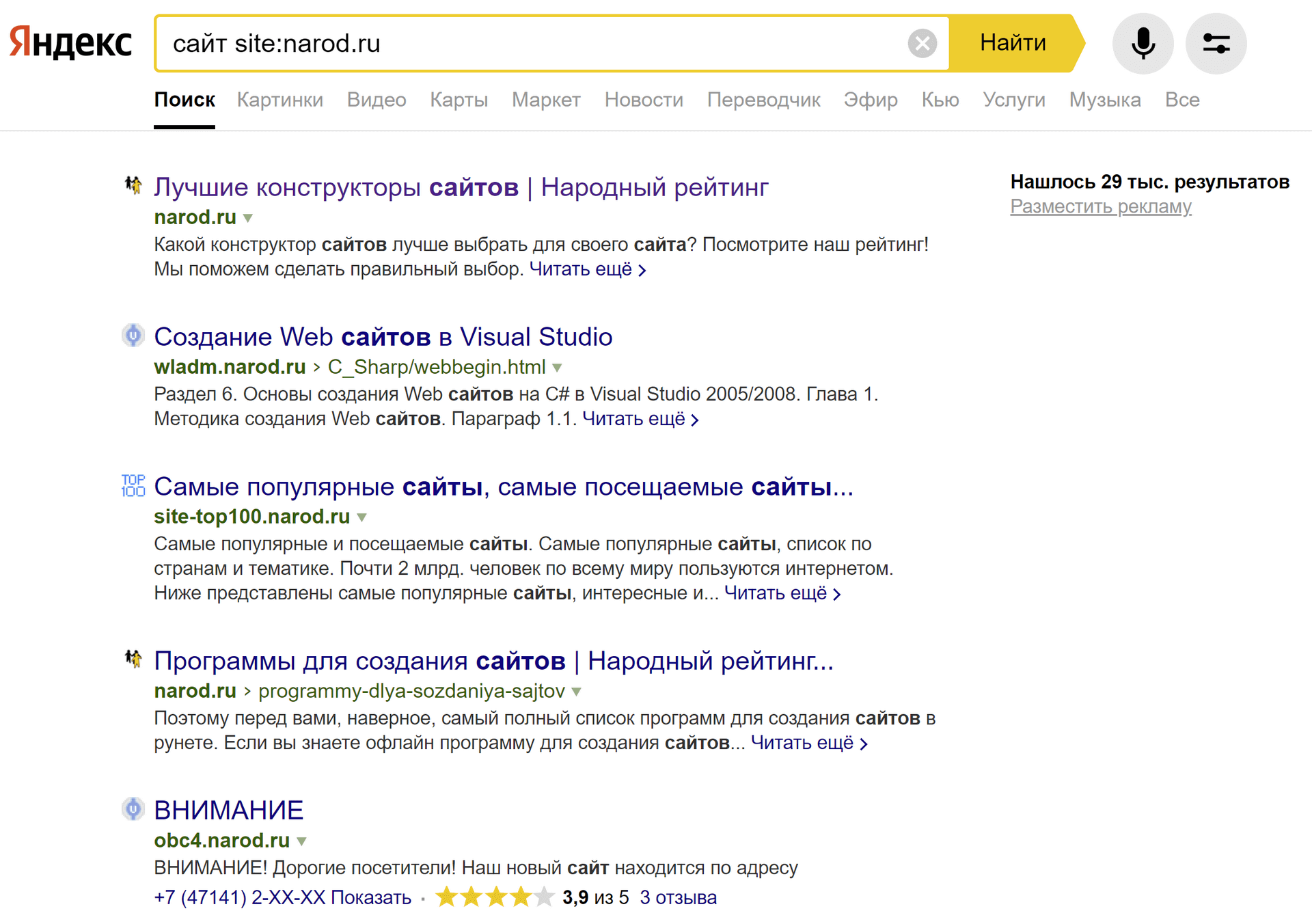
В Гугле все работает по аналогии.
формат: [фраза] site:[example.com]
пример: тлен site:alaev.info
Далее мы рассмотрим некоторые операторы, уникальные для каждой поисковой системы, либо похожие с виду, но работающие по-разному.
Операторы поиска для Яндекса
Большая часть перечисленных ниже операторов не задокументированы в справке Яндекса. Какие-то действительно полезные, а для каких-то найти практическое применение довольно сложно. Так что все на ваше усмотрение, а можете сразу пролистать на 10 страниц вниз до заголовка про решение прикладных задач.
Оператор & (амперсанд) и && (двойной амперсанд)
формат: [слово] & [слово]
Первый оператор & позволяет искать документы, где слова, связанные оператором, находятся в одном предложении. А второй оператор && позволяет искать слова в пределах одного документа.
Но понять, насколько корректно работают эти операторы, сложно, так как по запросам с операторами и без них результат очень схожий.
Оператор << (двойной знак меньше)
формат: [слово] << [слово]
Поиск слов в пределах документа, но релевантность (она влияет на положение в результатах поиска) рассчитывается только по первому слову (которое до оператора). Выражение после << ищется, но не участвует в ранжировании.
Оператор ~ (тильда) и ~~ (двойная тильда)
формат: [слово] ~ [слово]
пример: сериал ~ метод
Оператор ~ исключает из результатов поиска страницы, содержащие в одной фразе ключевое слово, идущее после тильды. Сравните обычную выдачу:
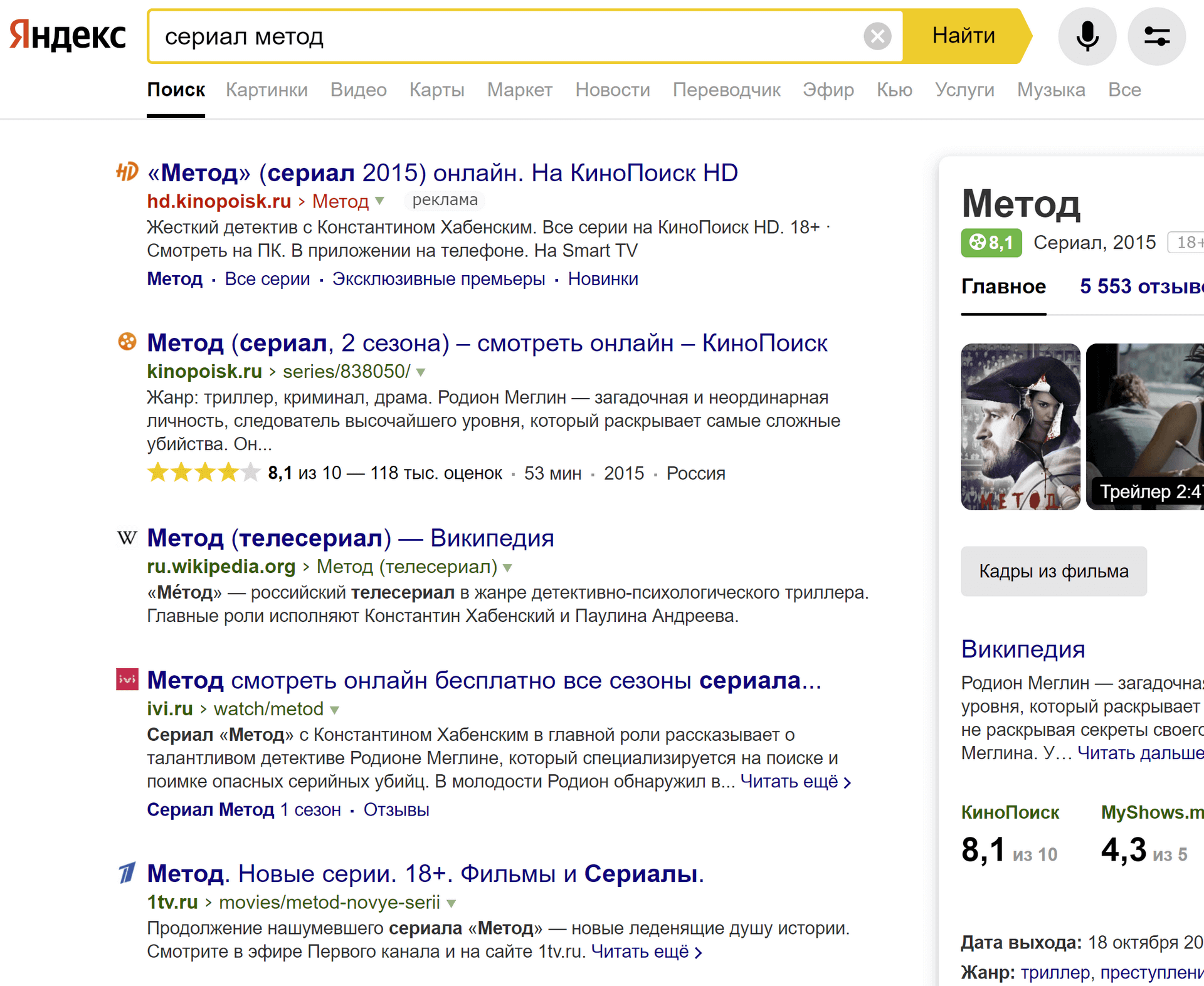
И выдачу, где есть «сериал», но нет «метод»:

Двойная тильда ~~ исключает из результатов страницы, где встречается ключевое слово до оператора и отсутствует слово, идущее после оператора.
На практике различие между операторами ~ и ~~ сложно заметить. Однако этот оператор используется в одном из методов определения аффилиатов сайтов.
Оператор host:
Исключает из выдачи поддомены указанного сайта (в отличии от оператора site:), то есть поиск будет осуществляться только по указанному домену.
формат: [слово] host:[example.com]
пример: сайт host:narod.ru

Оператор rhost:
Позволяет искать исключительно по поддоменам указанного сайта.
формат: [слово] rhost:[com.example.*]
пример: сайт rhost:ru.narod.*
Обратите внимание на формат указания сайта – в обратном порядке.

Оператор domain:
Позволяет искать по сайтам, расположенным в определенной доменной зоне.
формат: [слово] domain:[доменная зона]
пример: сайт domain:co
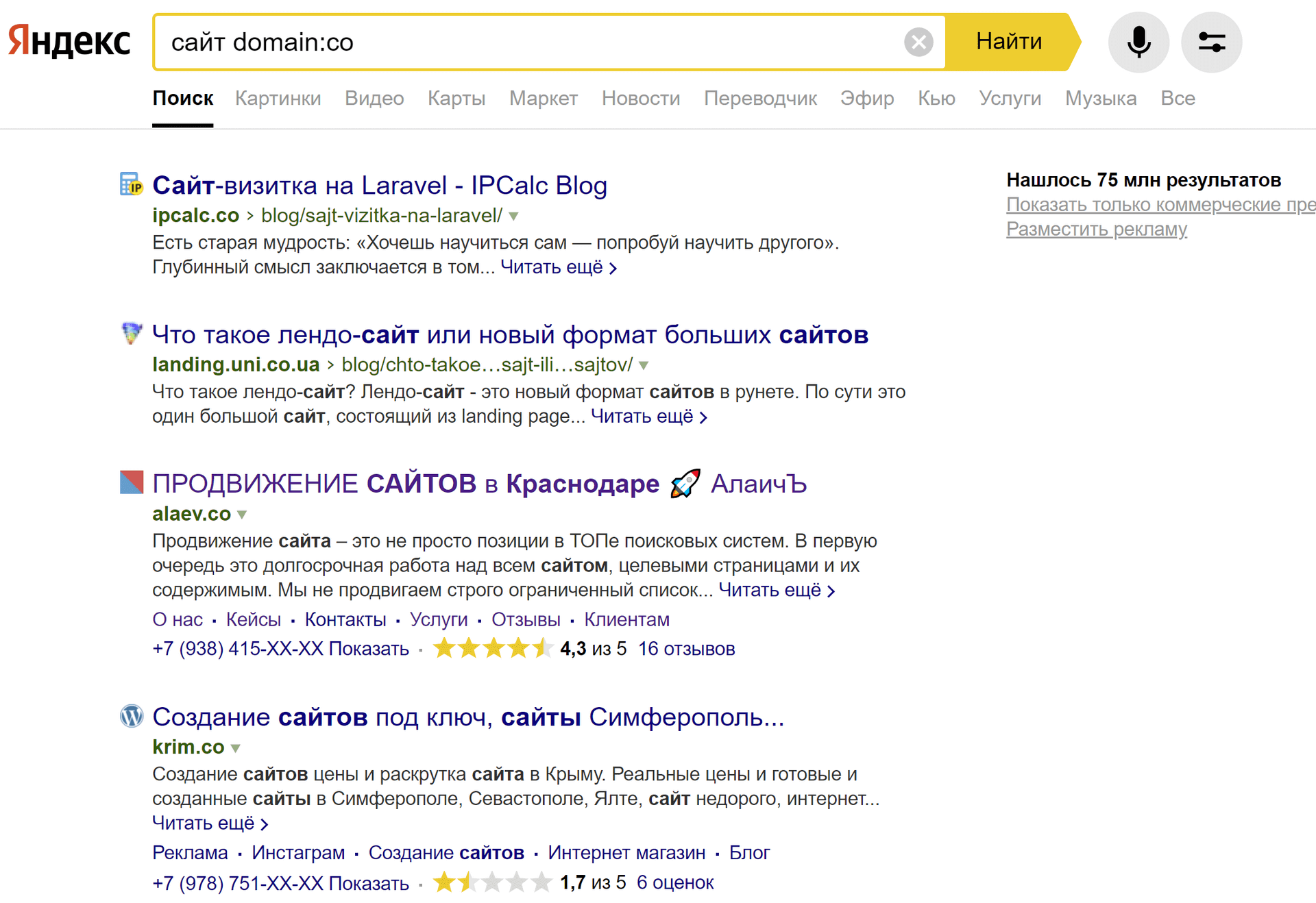
Как видите, указанная доменная зона не обязательно одиночная (.co), но может быть и такой: .co.ua. Чего только не обнаружишь, тестируя различные варианты ?
Оператор url:
Позволяет искать слово или фразу только на странице с указанным адресом.
формат: [фраза] url:[адрес страницы]
пример: полпути url:https://alaev.info
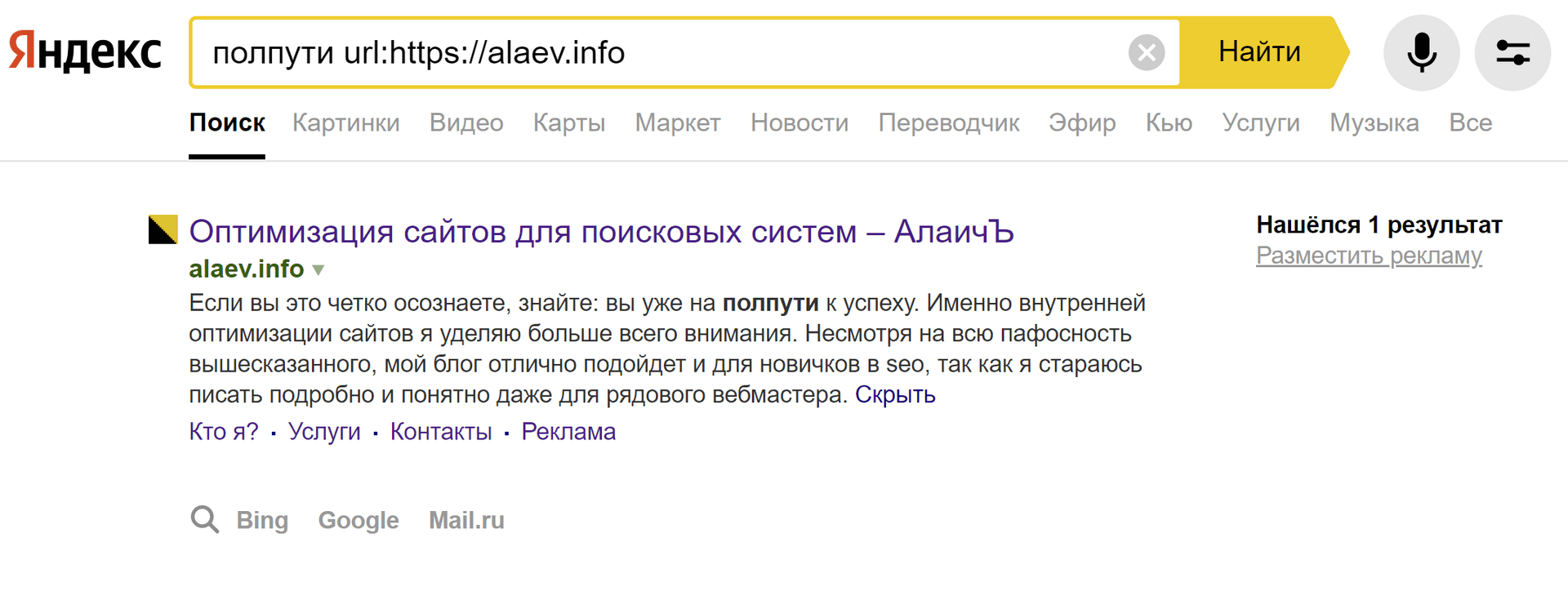
Поиск нашел нужное мне ключевое слово на обозначенной странице.
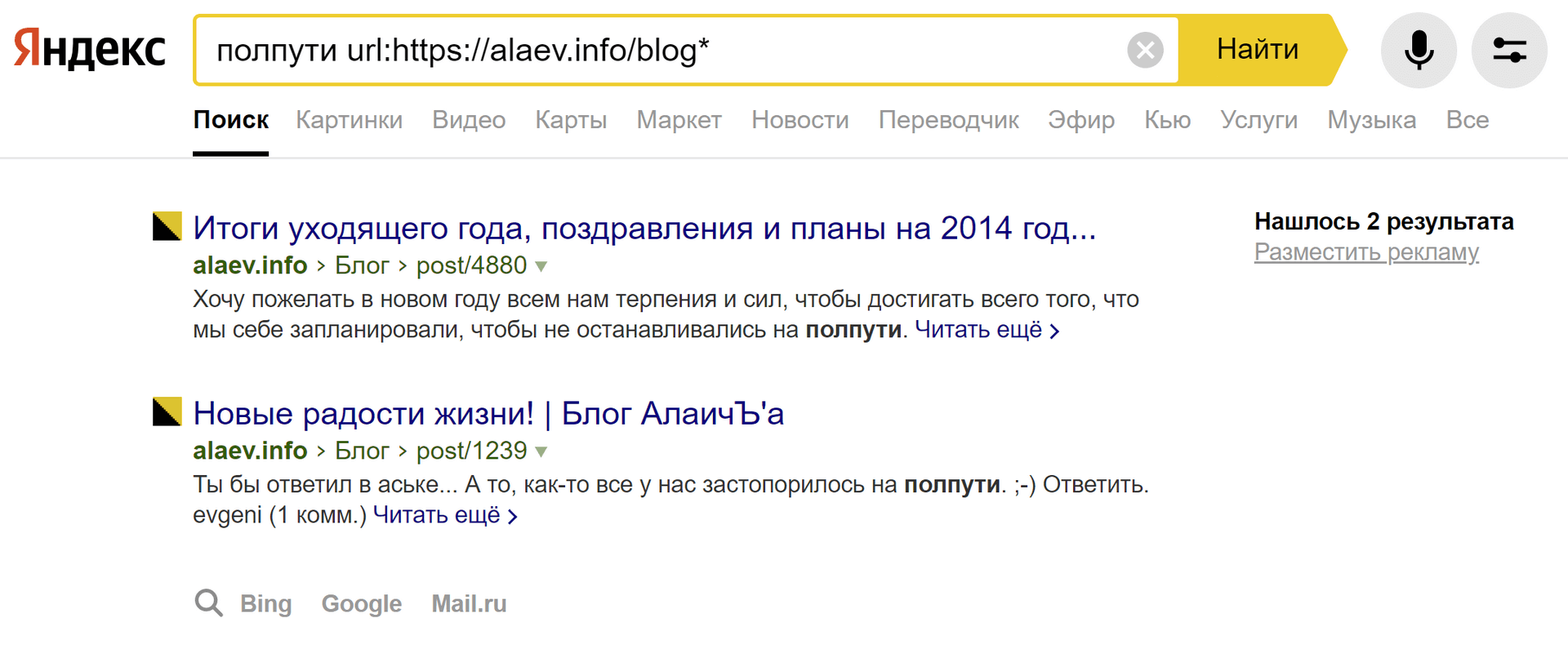
Еще вы можете использовать звездочку, чтобы найти все документы, адреса которых начинаются с указанного.
пример: полпути url:https://alaev.info/blog*
Оператор inurl:
Поиск ограничивается группой страниц, адреса которых содержат заданный фрагмент.
формат: [слово] inurl:[фрагмент адреса]
пример: сайт inurl:web
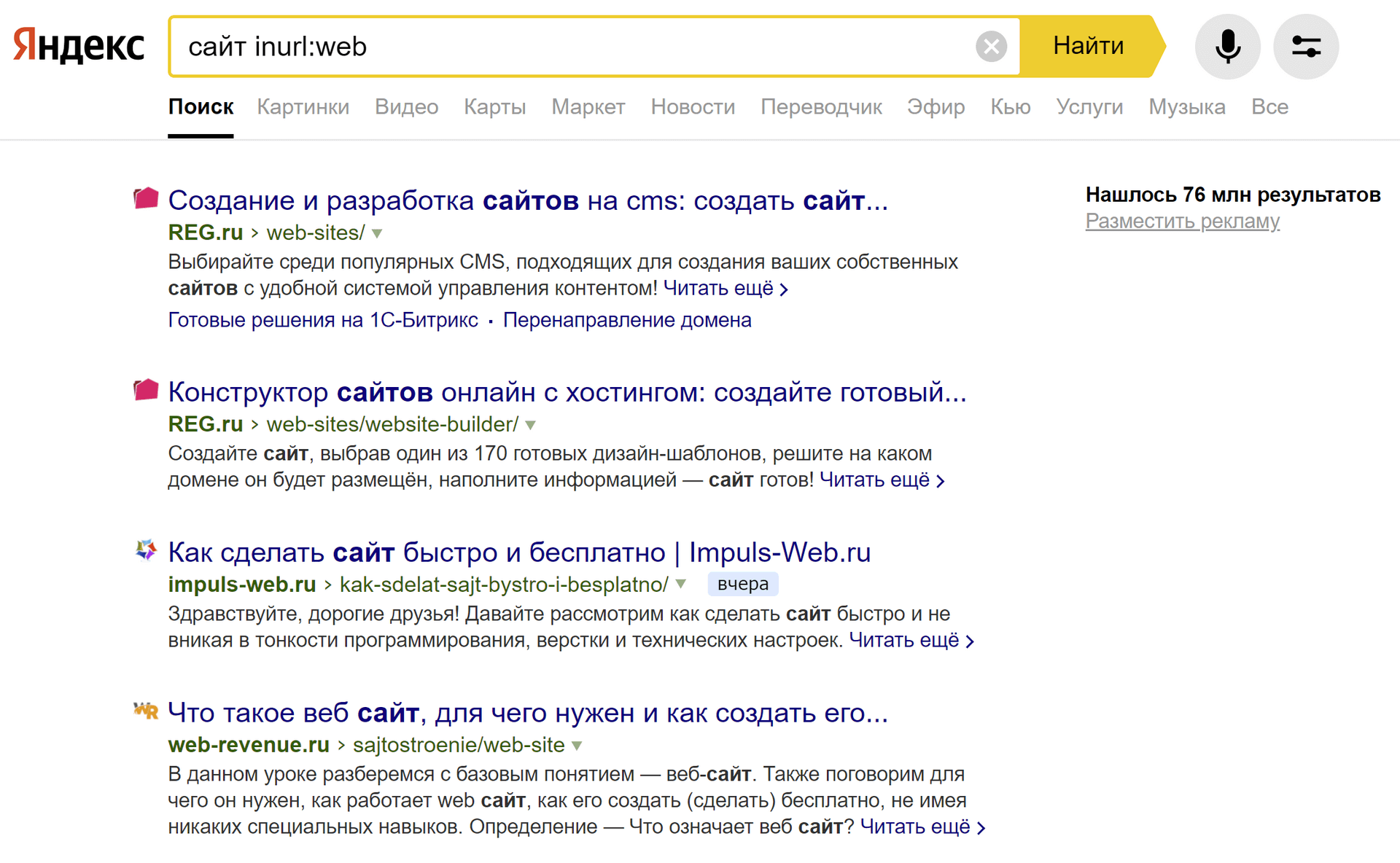
Обратите внимание, что часть адреса может содержаться как в названии домена, так и в адресе страницы.
Оператор title:
Позволяет искать только по заголовкам страниц (по тегу title).
формат: title:[фраза]
пример: title:жирный таракан
К сожалению, практика показывает, что не «только», так как сразу же встречаются результаты, не содержащие часть фразы не только в title, но и в тексте:
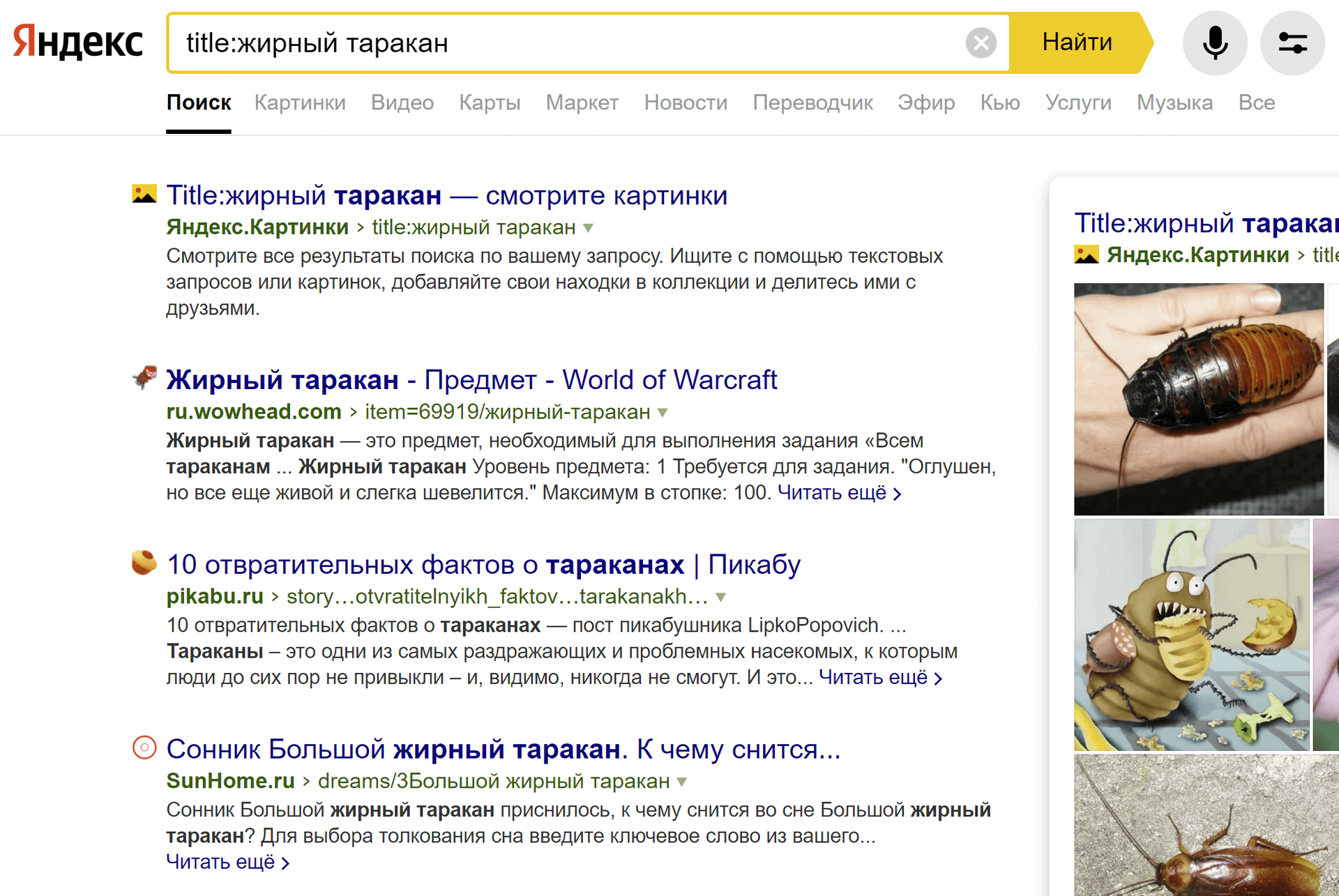
Странно, что Яндекс учитывает операторы таким образом – не как строгое правило, а, скорее, как рекомендацию, которую чаще всего игнорирует. В отличии от Гугла, где все четко и предсказуемо.
Оператор mime:
Позволяет искать по документам и файлам, указанного расширения и типа.
формат: [слово] mime:[тип файла]
пример: коммерческое mime:doc*
В справке Яндекса заявлены следующие типы файлов: pdf, xls, ods, rtf, ppt, odp, swf, odt, odg, doc.
Посмотрев на этот список, я сразу подумал, что тут явно чего-то не хватает, например docx, ныне более распространенного, чем doc.
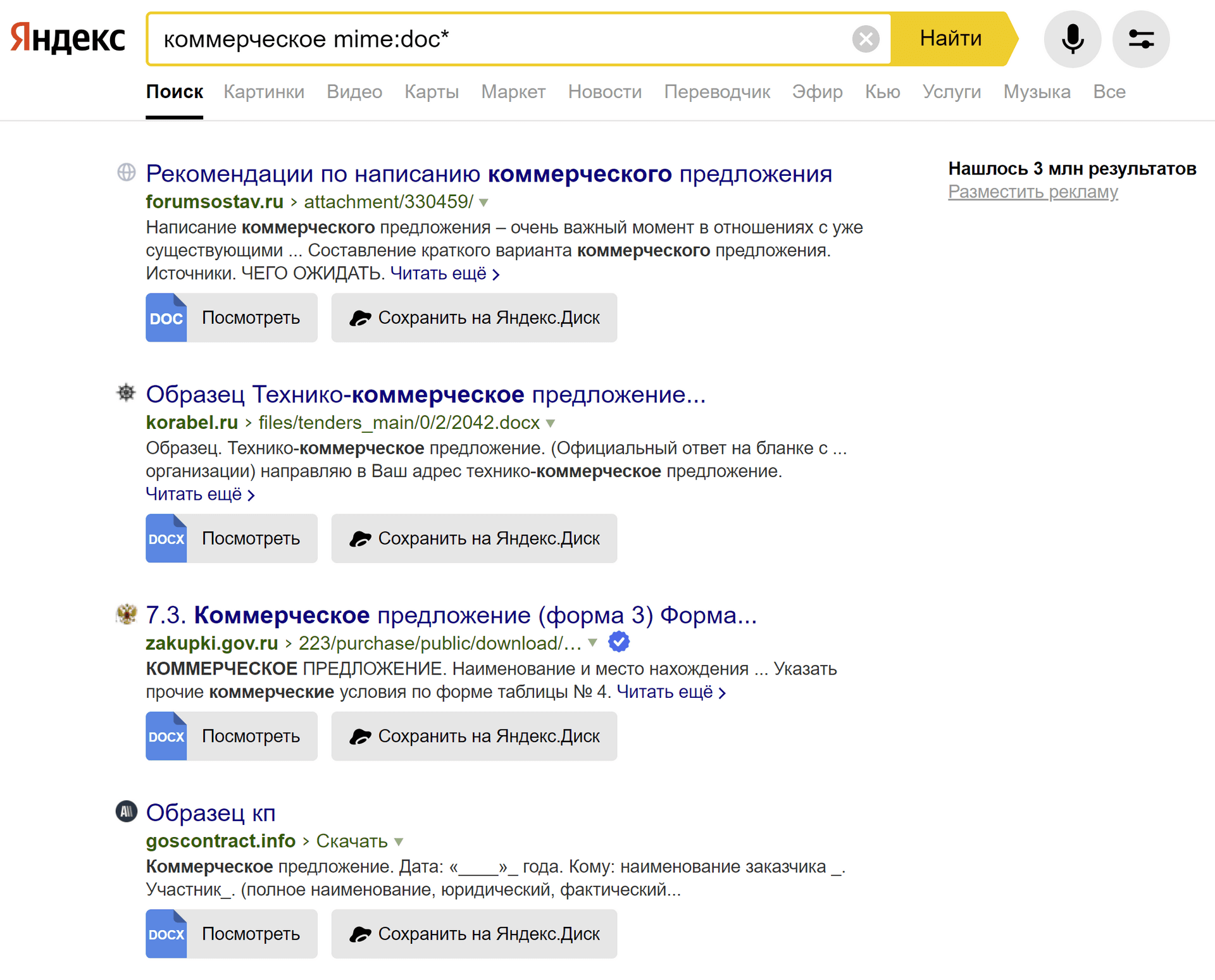
И я подумал, что можно искать одновременно и .doc и .docx, используя звездочку, как показано на скриншоте.
А потом пошел дальше. Захотелось мне .txt файлы поискать, ведь если они не заявлены в списке, то это не значит, что их нельзя искать. Но оказалось и правда нельзя. Зато помня про звездочку…
Вбил запрос 1 mime:t* и нашел txt, m3u, trf и еще всяких интересных вещей. Работает непредсказуемо и ищет не только файлы с расширением, начинающимся с буквы t. Таким образом можно перехитрить поиск!
Сочетая различные операторы между собой, можно найти много интересного, только я вам об этом, конечно же, ничего не говорил :)
Оператор date:
Ограничивает поиск документами по дате их последнего изменения.
Год указывается обязательно, а месяц и день можно заменить символом *.
формат: [фраза] date:[yyyymmdd]
пример: продвижение сайтов date:202001*
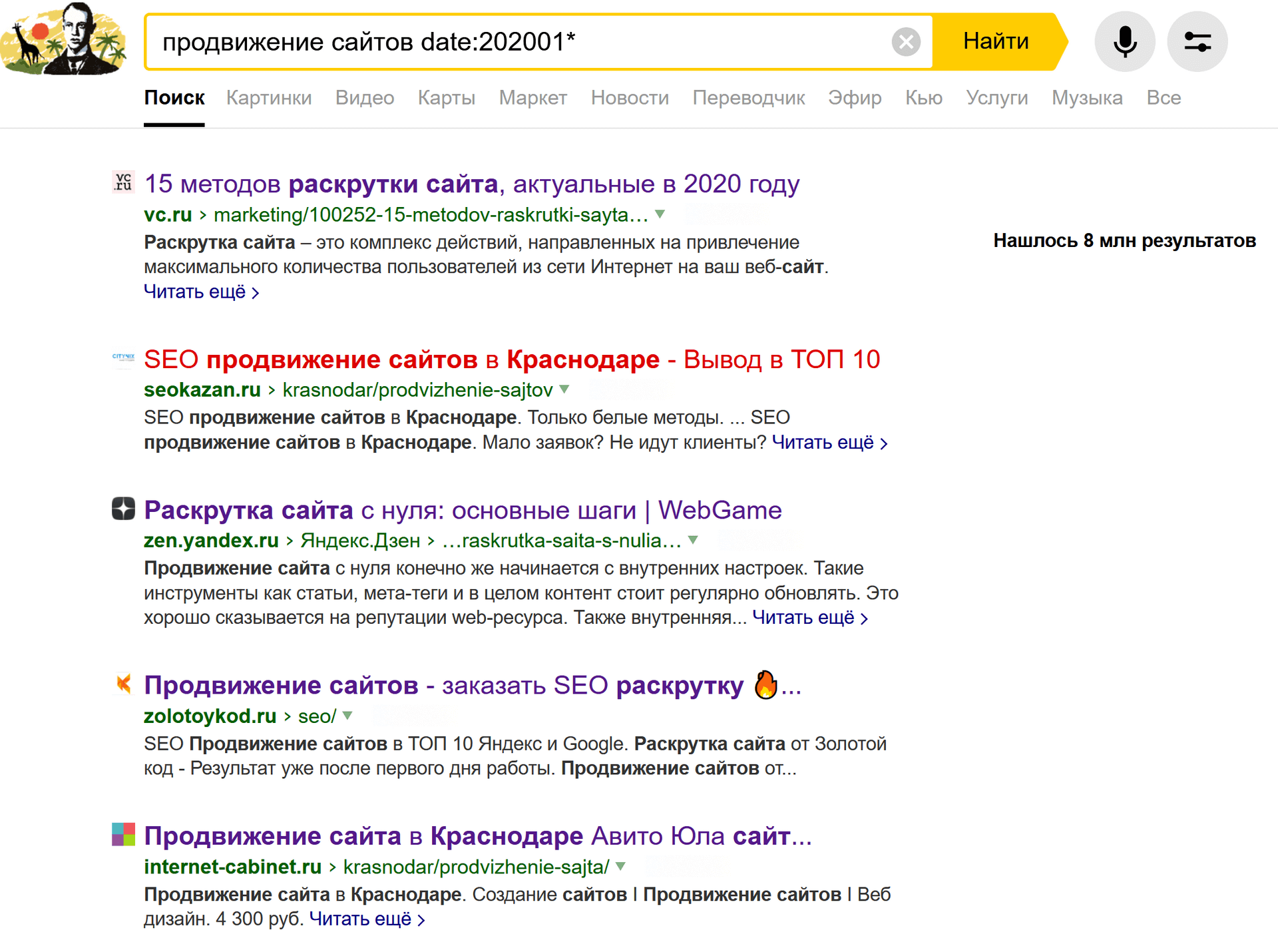
В данном случае показаны страницы и сайты про продвижение сайтов, созданные (а точнее — проиндексированные) в январе 2020 года.
И вот тут есть нюанс и некоторое несоответствие с описанием, предоставленным Яндексом. В справке говорится «по дате последнего изменения», но что такое изменение? Дата переиндексации или дата, когда при посещении роботом было замечено, что контент изменился относительно его прошлой копии?
Не то, и не другое. Я сначала было решил, что оператор date: делает выборку дате первой индексации страницы. Например, потому что я завел блог в конце 2009 года:

С тех пор контент много раз менялся на всех страницах, я три раза менял дизайн глобально. Вряд ли поисковик не заметил каких-либо изменений. Я был уверен, что это работает именно так. Тогда почему нет еще нескольких страниц, появившихся в 2009 году?
Я начал копать дальше и обнаружил в апреле 2019 года большое количество результатов:
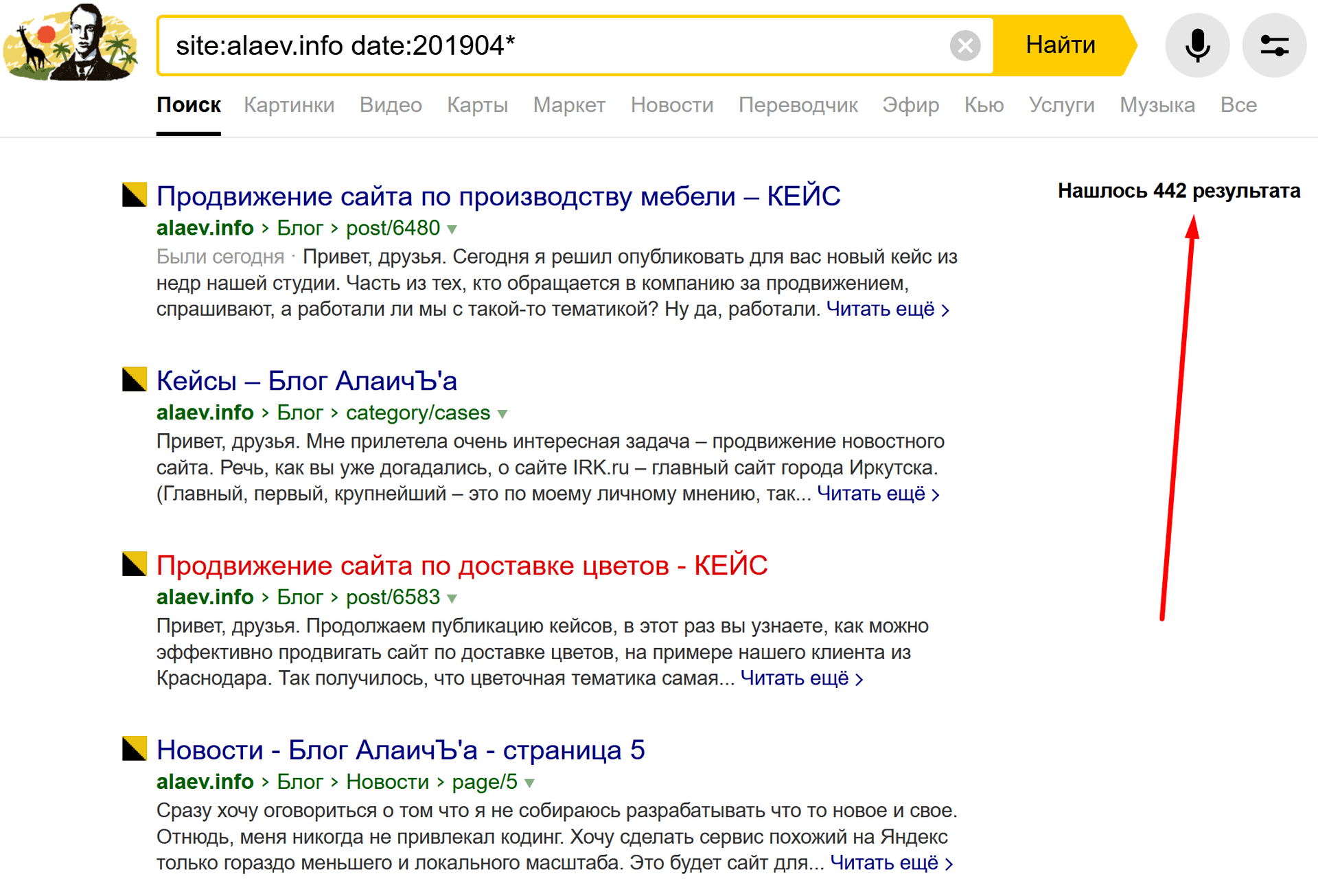
А как раз в апреле я переезжал с http на https. Соответственно, старые страницы как бы пропали, а новые появились и проиндексировались. В каком-то смысле их дата первой индексации сбросилась. Но тогда почему же главная страница блога, которая тоже переехала на https до сих пор болтается в 2009 году?
По определенным запросам я подтверждаю теорию о том, что оператор выбирает дату индексации, а не изменения – например: нашествие фестиваль date:2008*. А потом по схожему запросу нашествие фестиваль date:2018* убеждаюсь, что выдаются страницы, которые были созданы задолго до 2018 года.
Даже если посмотреть на примеры, которые приводит сам Яндекс:
- соответствует 10.10.2018: [фестиваль date:20201010];
- позднее 10.10.2018: [фестиваль date:>20181010];
- находится в интервале между 10.10.2018 и 10.11.2018 включительно: [фестиваль date:20181010..20181110];
- соответствует октябрю 2018 года: [фестиваль date:201810*];
- соответствует 2018 году: [фестиваль date:2018*].
Можно найти там недостоверные данные:
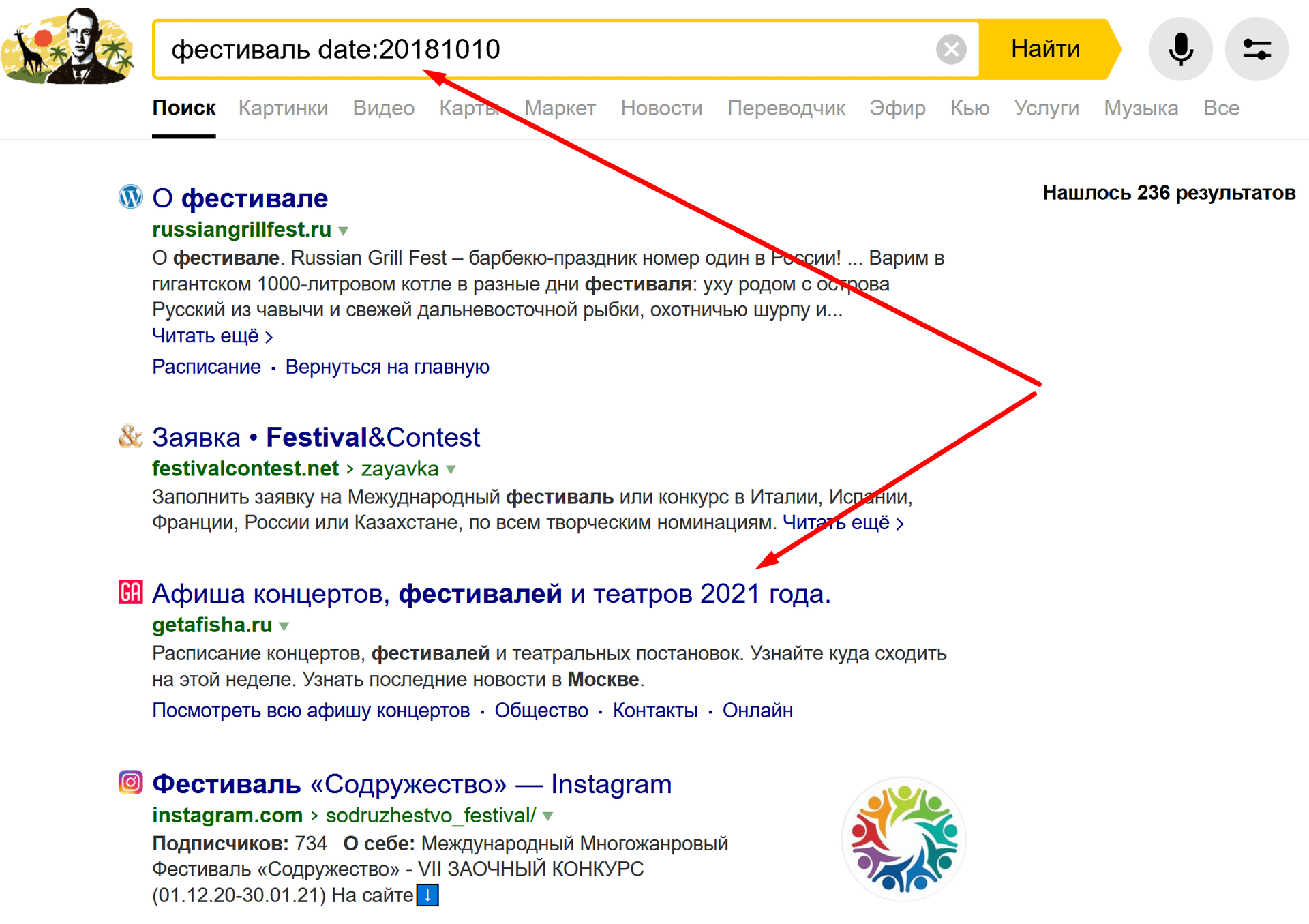
Короче, мы просто не знаем, что считает изменением сам Яндекс и в этом заключается недостоверность описанного метода.
Вообще в справке Яндекса есть целый раздел о том, как искать в Яндексе и как уточнить поиск, однако там приведены не все операторы, которые мы рассмотрели. По всей видимости, Яндекс не считает их столь уж необходимыми простым людям, но мы же сеошники ?
Кстати, основные операторы используются не только непосредственно в поиске, но и в других сервисах, например, в Яндекс Вордстате – у меня есть подробный обзор операторов и сочетаемости друг с другом. Хотя бы там операторы работают так, как ожидается и без всяких приколов.
Операторы поиска для Google
Оператор cache:
Возвращает последнюю кэшированную версию веб-страницы (при условии, что страница проиндексирована, конечно) вместе с датой и точным временем, когда снимок был сделан.
формат: cache:[example.com]
пример: cache:microsoft.com
Оператор filetype:
Ограничивает результаты поиска файлами определённого формата, например: pdf, docx, txt, ppt и т.д.
формат: [фраза] filetype:[тип файла]
пример: seo filetype:txt
У данного оператора есть аналог ext: — работает аналогично, включая особенности.
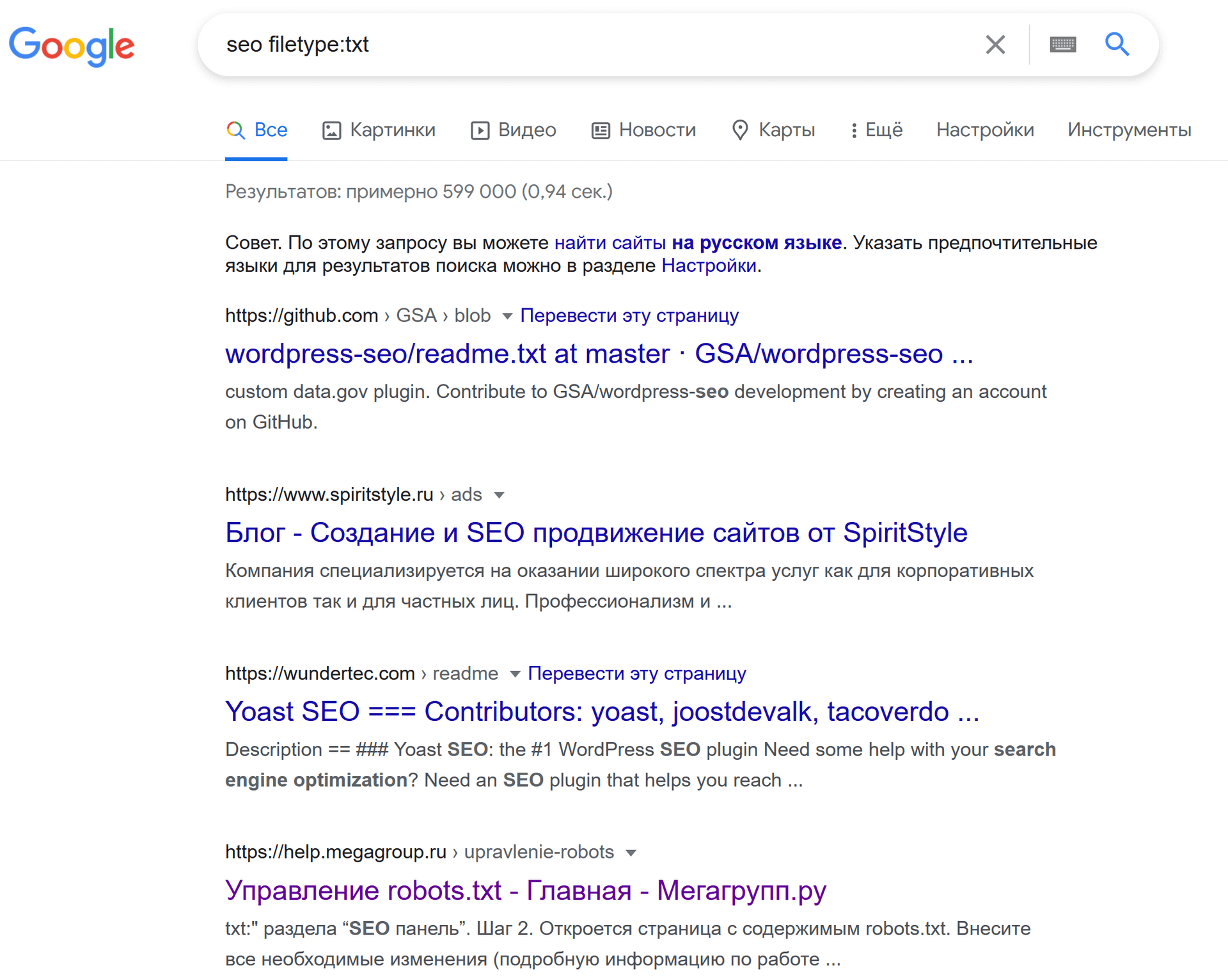
Конечно, я сразу захотел проверить будет ли работать поиск по файлам txt, которые не ищет Яндекс.
Но вместо этого я обнаружил другую особенность работы данного оператора: он ищет не конкретно файлы, а url-адреса, которые оканчиваются на указанное расширение, в моем случае это .txt. То есть это могут быть и обычные страницы сайта, которые имеют искомое окончание. По этой причине на четвертом месте нашелся вот такой url: https://help.megagroup.ru/upravlenie-robots.txt. Неожиданно ?
Стоит добавить, что filetype: или ext: сочетаются, например, с операторами inurl: и intext:, что расширяет наши возможности по поиску «нужных» файлов!
Оператор inurl:
Осуществляет поиск фразы по страницам сайтов, содержащих в своем адресе одно или несколько слов, идущих после оператора.
формат: [фраза] inurl:[фрагмент url]
пример: протест inurl:в москве
При этом вы не обязаны указывать искомую фразу, можно указывать только часть адреса.
формат: inurl:[фрагмент url]
пример: inurl:в москве
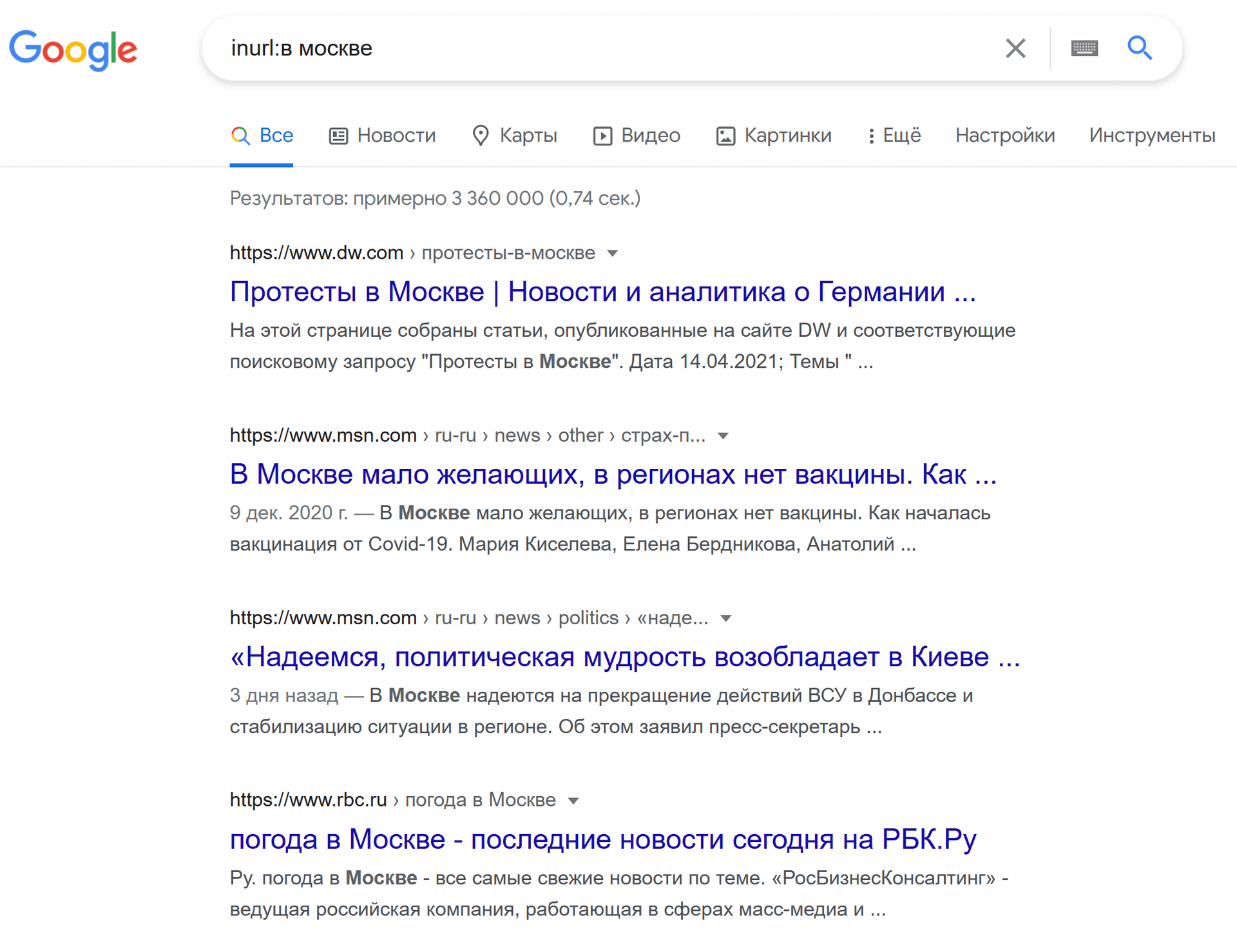
В этом случае в выдачу попали абсолютно все известные поиску страницы, содержащие в своем адресе «в» или «москве».
Обратите внимание, что я использовал исключительно кириллические слова в качестве части url, и поиск меня понял.
Оператор allinurl:
Думаю, вы уже догадались на примере предыдущих описаний, что оператор allinurl: должен возвратить нам все страницы, адрес которых в обязательном порядке содержит все слова из фразы в указанной словоформе.
формат: allinurl:[фрагмент url]
пример: allinurl:seo bomzh

По моему запросу я и не ожидал найти много результатов, и это показывает нам, что оператор работает четко и не позволяет себе вольностей, как это бывает в Яндексе.
И есть одно важное отличие оператора allinurl: от inurl: — он не сочетается с каким-нибудь поисковым запросом. При попытке искать слово «alaev» по страницам, содержащим в адресе «seo» при помощи оператора: alaev allinurl:seo мы получаем результаты аналогичные поиску по трехсловной фразе «alaev allinurl seo».
Оператор inanchor:
Ищет адреса страниц, на которые есть ссылки с указанным в запросе текстом. То есть мы можем искать страницы, на которые стоят внутренние или внешние ссылки с текстовым анкором, в котором встречаются слова из искомой фразы.
формат: inanchor:[фраза]
пример: inanchor:таракан тапочках
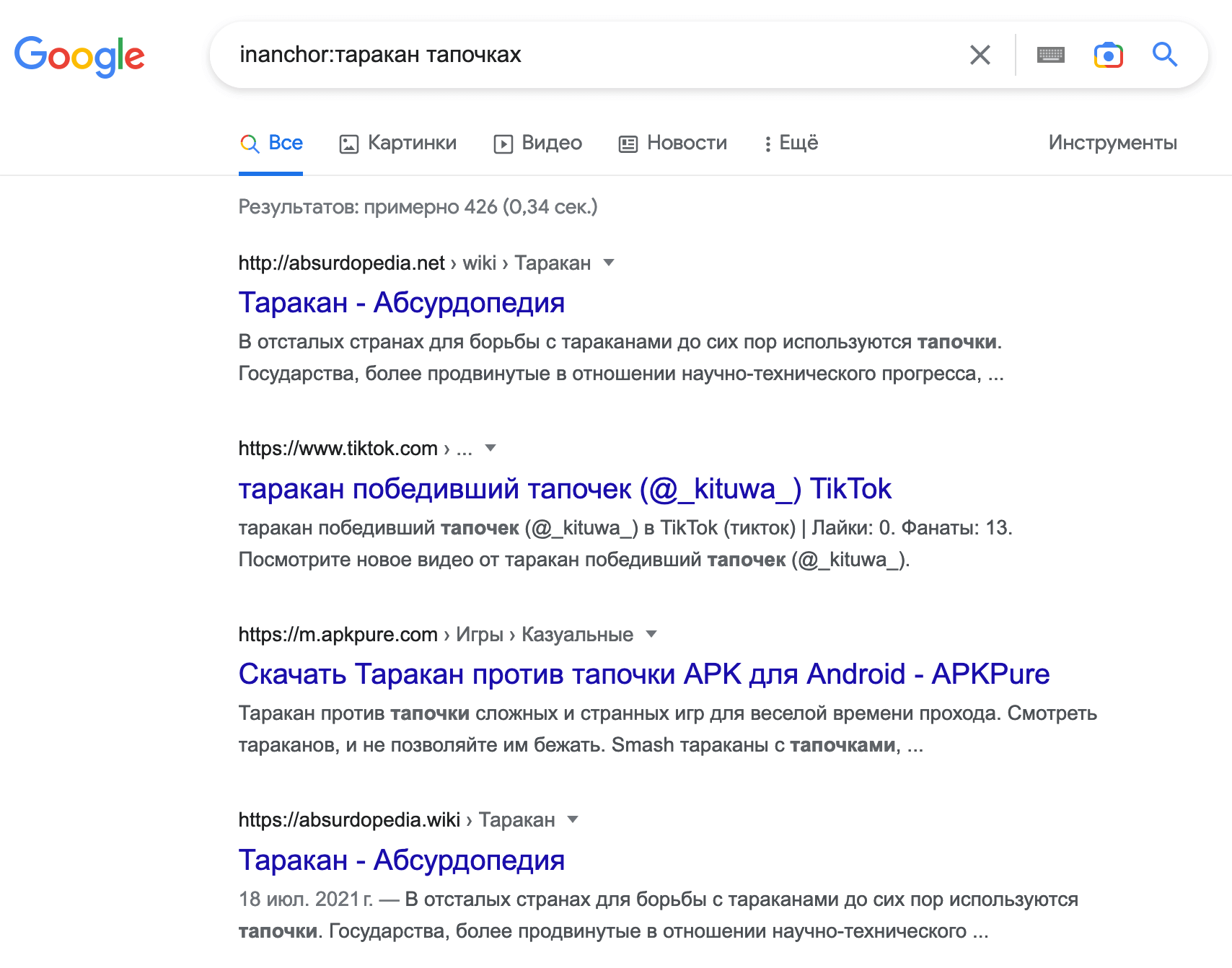
В выдаче мы увидим все страницы, на которые есть ссылки, в анкорах которых содержится любое из слов: «таракан» или «тапочках».
Проверить это довольно сложно, так как учитываются и внутренние, и внешние ссылки, соответственно, показываются сами по себе релевантные страницы. Но в следующем примере я покажу вам, что это действительно работает.
Оператор allinanchor:
Работает как и inanchor:, но обязательно ищет в анкоре ссылки все слова из искомой фразы в указанной словоформе.
формат: allinanchor:[фраза]
пример: allinanchor:общемировую статистику
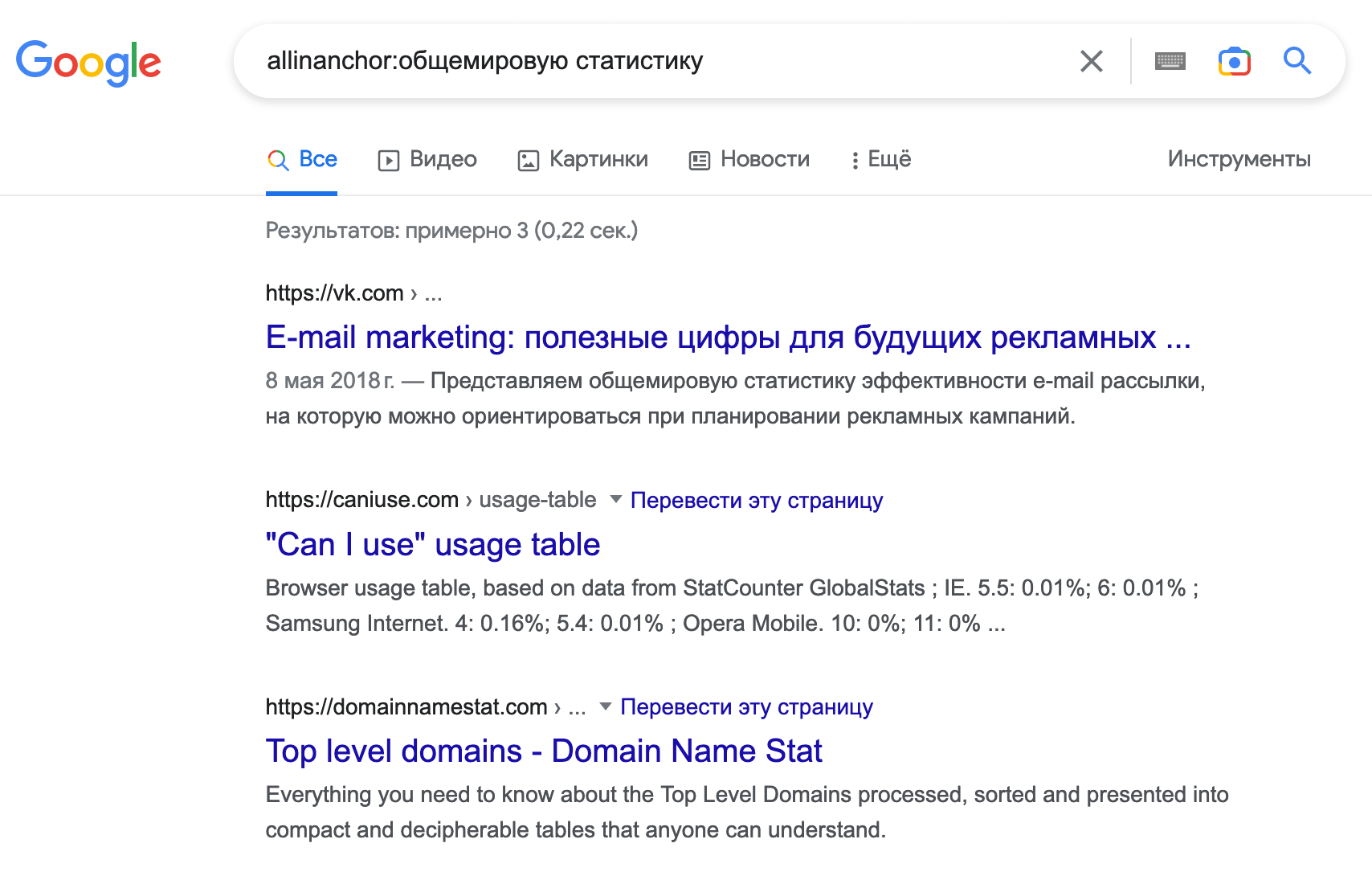
В данном случае для проверки работы оператора я взял анкор ссылки из поста про выбор доменного имени, где я ссылаюсь на страницу https://domainnamestat.com/statistics/tld/others, не содержащую ни одного слова на русском и тем более, не содержащую искомую фразу «общемировую статистику». Так что поиск по анкору работает!
Оператор intitle:
Ищет слова только по содержимому заголовков title страниц.
формат: intitle:[фраза]
пример: intitle:seo бомж

Оператор allintitle:
Работает по аналогии с вышеописанным intitle:, но обязательно в title должны содержаться все слова из искомой фразы и, как я в очередной раз убедился, обязательно в указанной словоформе.
формат: allintitle:[фраза]
пример: allintitle:seo бомж
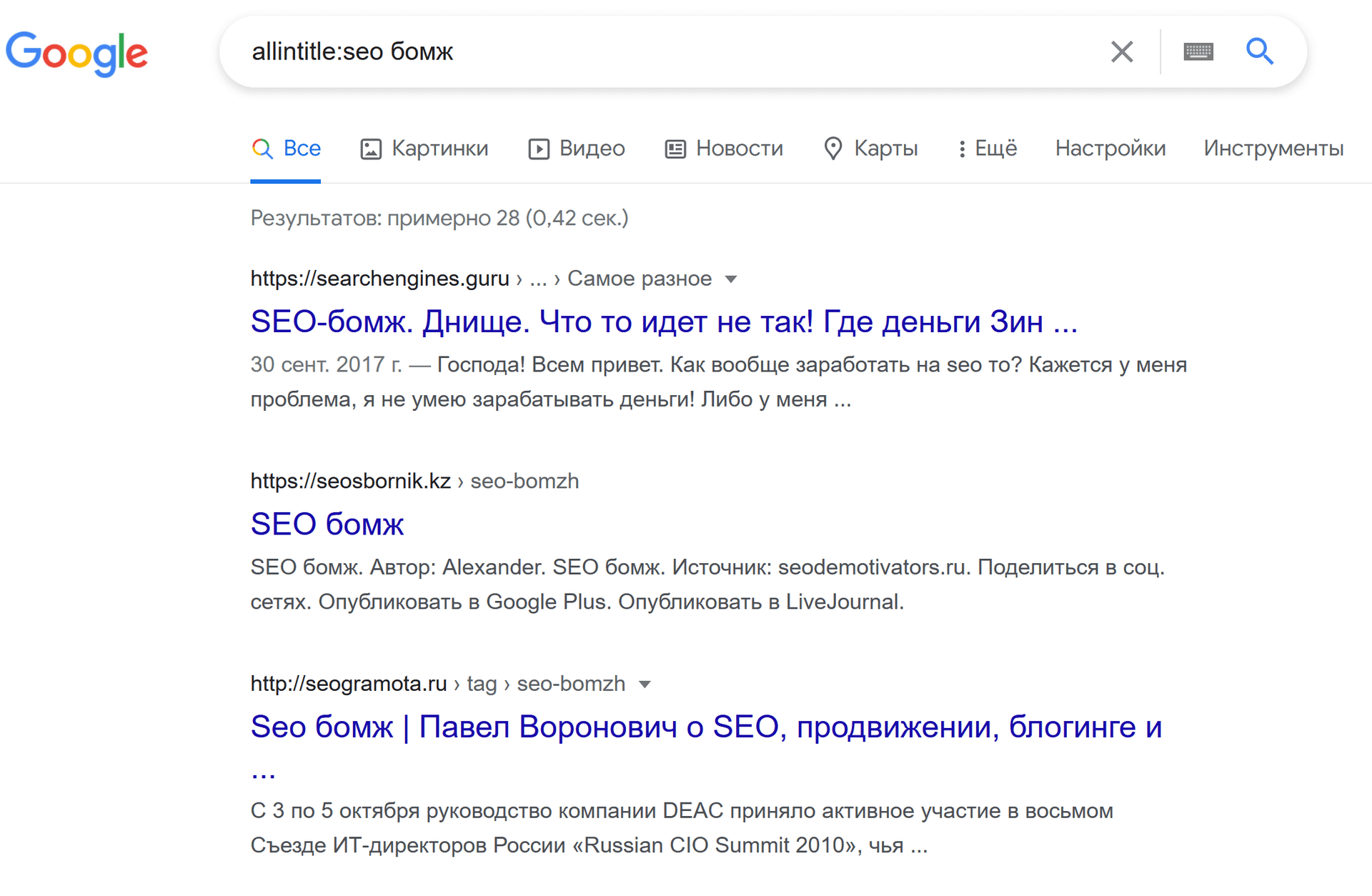
Для примера я взял для обоих операторов один и тот же запрос «seo бомж». Но отличия для этих запросов не столь радикальное, как если вы введете поочередно: allintitle: в москву, allintitle:в москве, allintitle:в москва или даже allintitle:в москвой. Вот при этих запросах видно, как Гугл бескомпромиссно следует своим же правилам (операторам).
Если вы хотите еще ужесточить запрос, чтобы слова фразы шли в определённом порядке, берем фразу в кавычки.
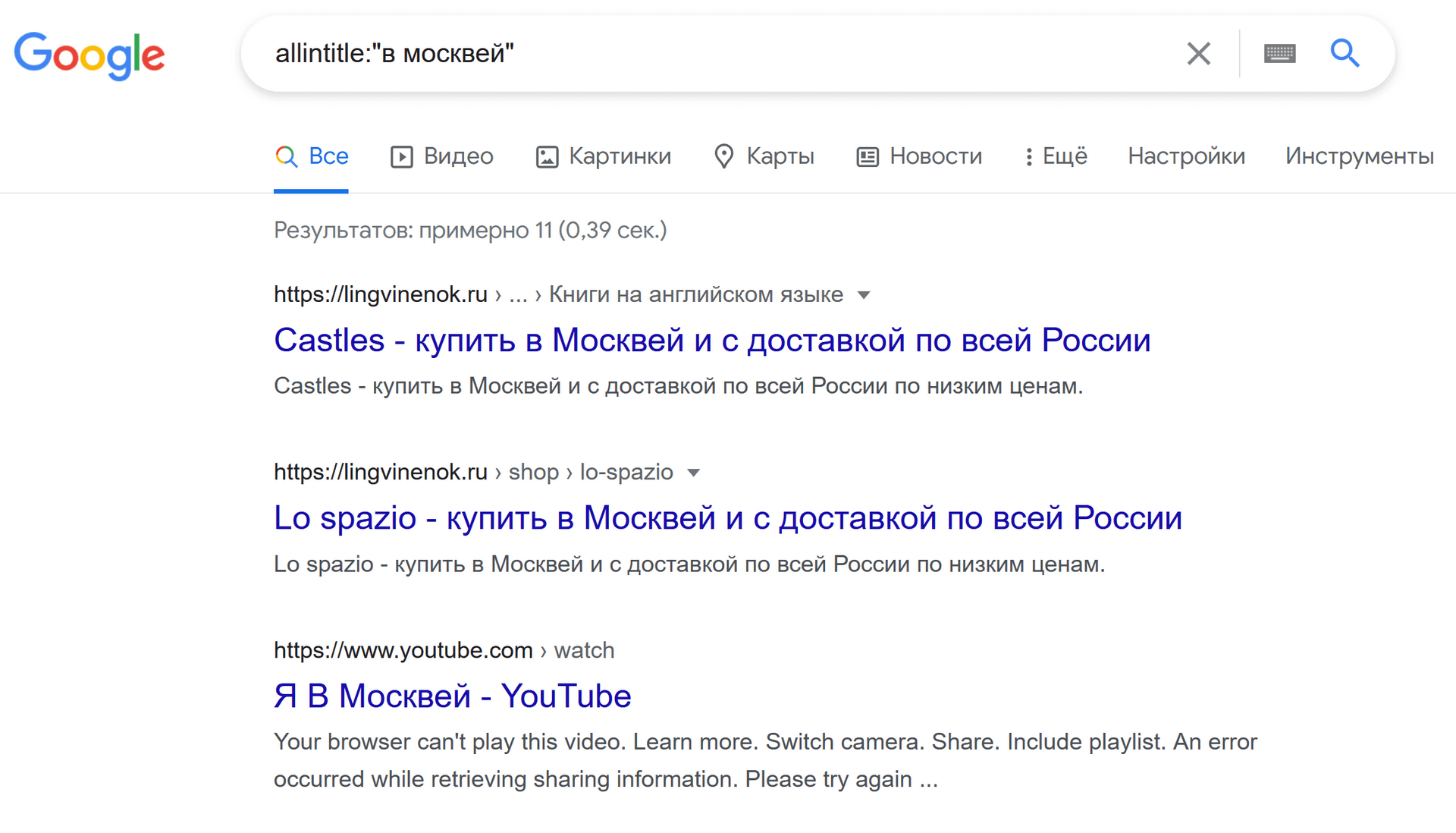
формат: allintitle:"[фраза]"
пример: allintitle:"в москвей"
Оператор intext:
Позволяет искать страницы, содержащие обязательно в тексте искомое слово или слова. Ну и что тут такого и зачем вообще нам нужен такой оператор, когда поисковик и так всегда ранжирует по вхождениям в текст (сайты, которые содержат фразу только в title и не содержат в тексте обычно ранжируются ниже и до них надо долго пролистывать, так что условно их можно игнорировать).
Но я придумал интересный вариант использования:
формат: intext:[фраза]
пример: intext:кондибобир

Вы можете использовать данный оператор для поиска какой-нибудь дичи, целенаправленно неверно написанных слов или чего-то другого, что вам в голову придет. При этом поисковик не будет говорить вам: «Возможно, вы имели в виду: …» и показывать результаты, где искомое слово встречается в транслите. Используя данный оператор, вы всегда найдете именно то и в том виде, в котором ищете.
Оператор allintext:
Будет искать обязательно все слова, указанные в запросе.
формат: allintext:[фраза]
пример: allintext:алаичъ плащ
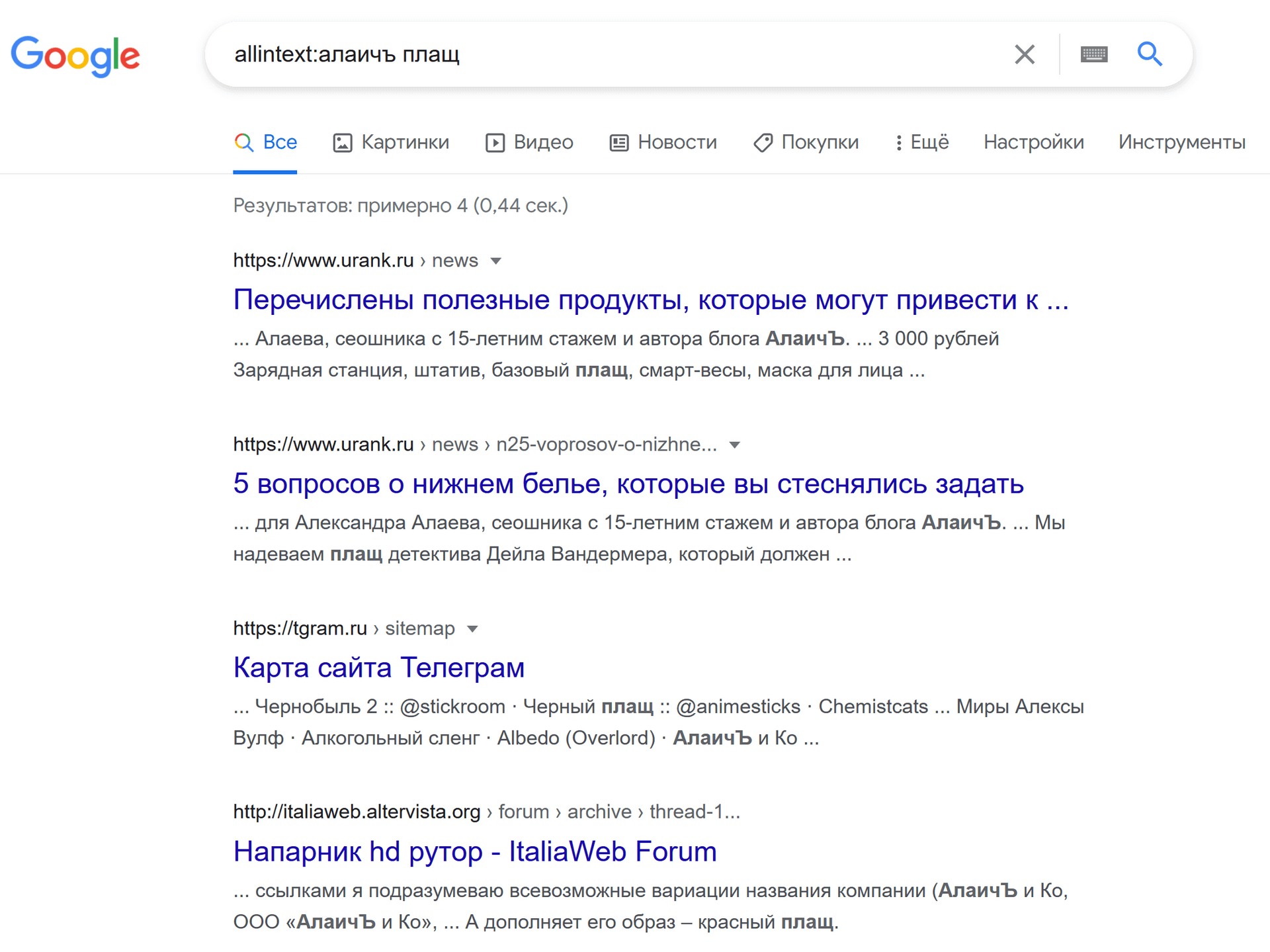
Для оператора allintext: также можно использовать кавычки в запросе, чтобы искать нужные слова в определенной последовательности.
И еще я обнаружил интересную особенность, что allintext: ищет не только в тексте, но в том числе и в заголовке title (я встречал в выдаче документы, которые содержат искомую фразу только в title, а в тексте – нет).
Оператор related:
Согласно теории, данный оператор предназначен для поиска сайтов с похожим контентом.
формат: related:[example.com]
пример: related:ya.ru

Забавно, что если я запрошу related:yandex.ru, то получу ответ «По запросу related:yandex.ru ничего не найдено.» И при запросе related:google.ru в выдаче будет показываться именно ya.ru, а не yandex.ru.
Также меня смутило, что нет никаких результатов для alaev.info и alaev.co, а по запросу related:maxitop.ru (это сайт одной из веб-студий Краснодара) показываются не веб-студии, а автомобильные сайты, техцентры, СТО и магазины автозапчастей.
Так что у меня большой вопрос к Гуглу, друг, а что учитывается при определении похожести сайтов?
На этом я закончу теорию и перейду к разбору прикладных задач, с которыми вы можете столкнуться в процессе продвижения сайтов.
И не забывайте, что у Гугла тоже есть справка о том, как уточнять поисковые запросы, но, как и в Яндексе, она содержит мало полезных нам, сеошникам, операторов.
Решение прикладных задач в SEO
Как быстро поменять регион поисковой выдачи в Яндексе: &lr=
Я считаю, это первое, что должен изучить seo-специалист, ежедневно работающий с поисковыми системами, — быстрое переключение региона.
Вот медленный способ переключения региона:
- Первый шаг – нажать на иконку, открывающую настройки.
- Второй шаг – нажать на кнопку редактирования названия региона.
- Третий шаг – ввести текстом название города (благо, там есть подсказки), выбрать его из списка и нажать «Найти» в поисковой строке.

Представьте, сколько действий надо совершить! Достичь аналогичных результатов можно всего в несколько кликов. Я привел тут этот алгоритм отнюдь не ради того, чтобы проиллюстрировать сложность, а чтобы мы могли узнать числовой код региона, который нам нужен.
Когда вы что-то ищете без всяких настроек, Яндекс будет подставлять вам тот регион (город), в котором вы находитесь (если он смог верно определить вашу геолокацию и, если она не заблокирована браузером). Я поищу «продвижение сайтов»:

Я выделил на скриншоте стрелкой параметр &lr=35, значение 35 которого показывает мой регион – Краснодар. У вас будет свой собственный код, например, 213 – Москва, 54 – Екатеринбург, 2 – СПб.
У Яндекса есть список основных городов — https://yandex.ru/dev/xml/doc/dg/reference/regions.html — но есть вероятность, что вы не найдете там город, выдачу в котором необходимо посмотреть.
Вариант первый – следуя пошаговому «сложному алгоритму», описанному выше, зайти в настройки и указать нужный вам город. Я решил выбрать Верхнюю Пышму – город-спутник Екатеринбурга, где живет 70 тысяч человек. В реальности, конечно, жители предпочтут найти исполнителя в самом ЕКБ, но моя задача показать, как это работает:
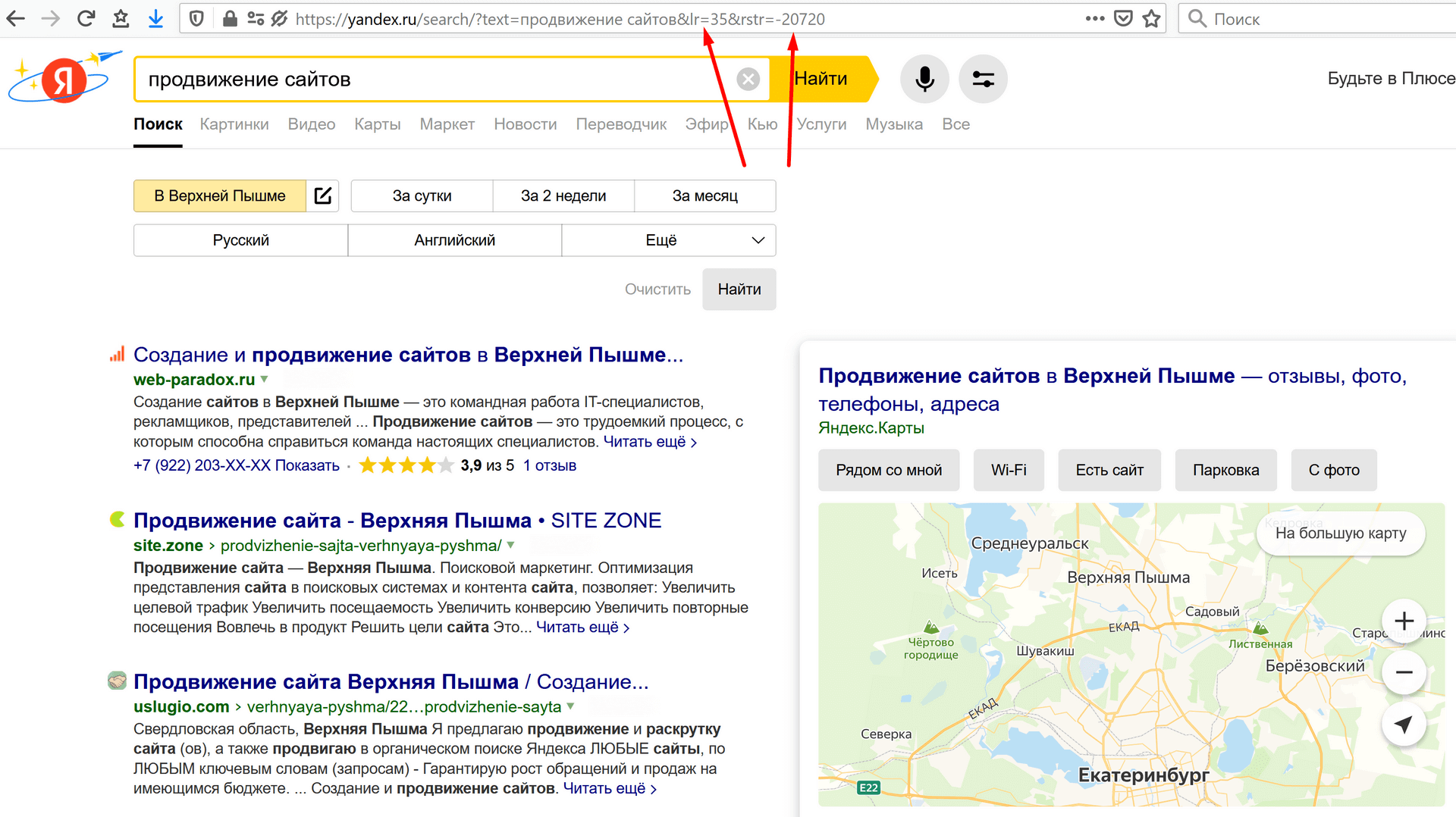
Я отметил на скриншоте два параметра &lr=35 и &rstr=-20720 – первый показывает, что я по-прежнему нахожусь в Краснодаре, а второй показывает, что я изменил регион, и значит код Верхней Пышмы – 20720.
Второй вариант – при условии, что мы знаем код нужного нам региона, то для поиска по этому региону надо будет в адресной строке просто изменить &lr= на 20720.
Так как сеошники в регионах, изучая коммерческие характеристики сайтов, смотрят не только на региональных конкурентов, но и часто на московских, имеет смысл в первую очередь запомнить параметр &lr= и код Москвы 213, это поможет вам сэкономить кучу времени!
Также существует полный список всех имеющихся регионов Яндекса отдельным файлом, который раньше лежал у Яндекса, но был удален, когда они решили закрыть свой Каталог, но добрые люди сохранили это наследство, так что я тоже залил файл к себе, чтобы он был всегда доступен, пока существует мой блог. Скачать список регионов Яндекса в .pdf
Как узнать количество страниц в индексе Яндекса для домена
Используем оператор host: с указанием домена.
формат: host:[example.com]
пример: host:alaev.info
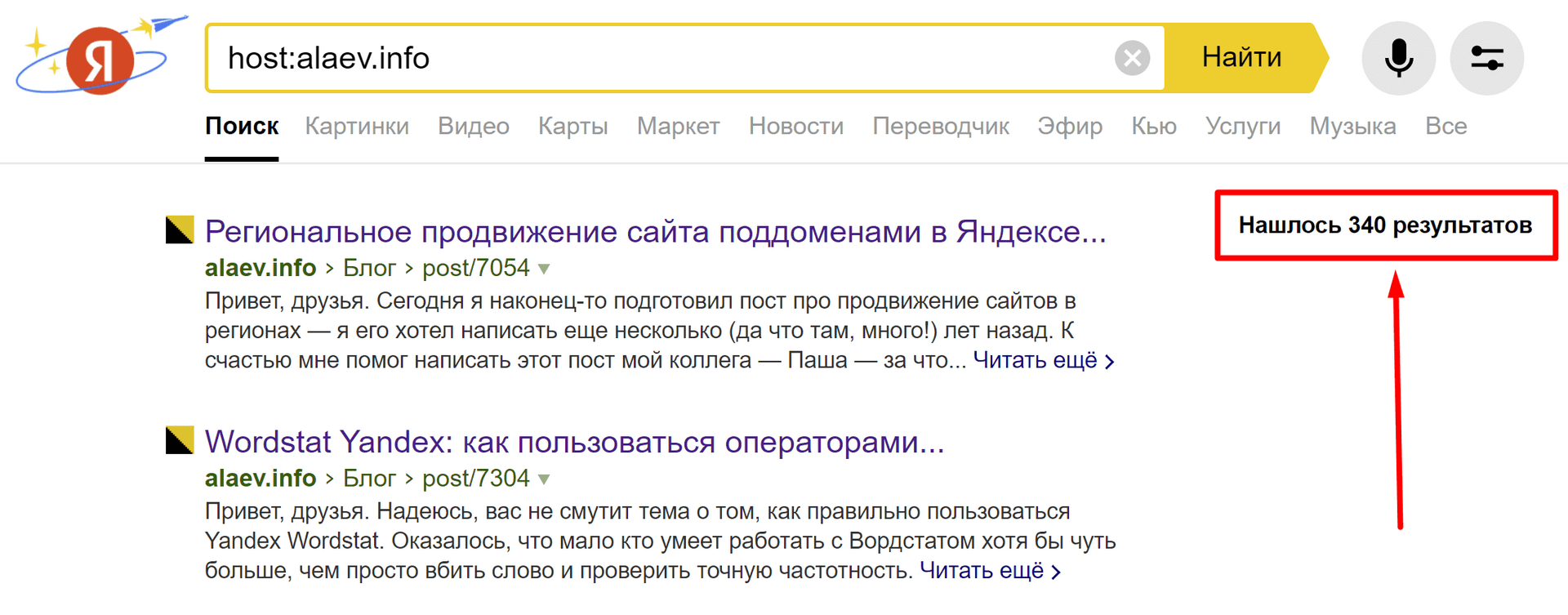
Как видите, количество проиндексированных страниц моего блога – 340.
Как узнать количество страниц в индексе Яндекса для сайта и всех его поддоменов
Используем оператор site: с указанием домена.
формат: site:[example.com]
пример: site:alaev.info

Количество страниц вместе с поддоменами составляет около двух тысяч. К сожалению, Яндекс округляет результат, потому это лишь ориентировочное число.
Чтобы вы понимали, вот реальное количество страниц в индексе на тот же самый момент времени:
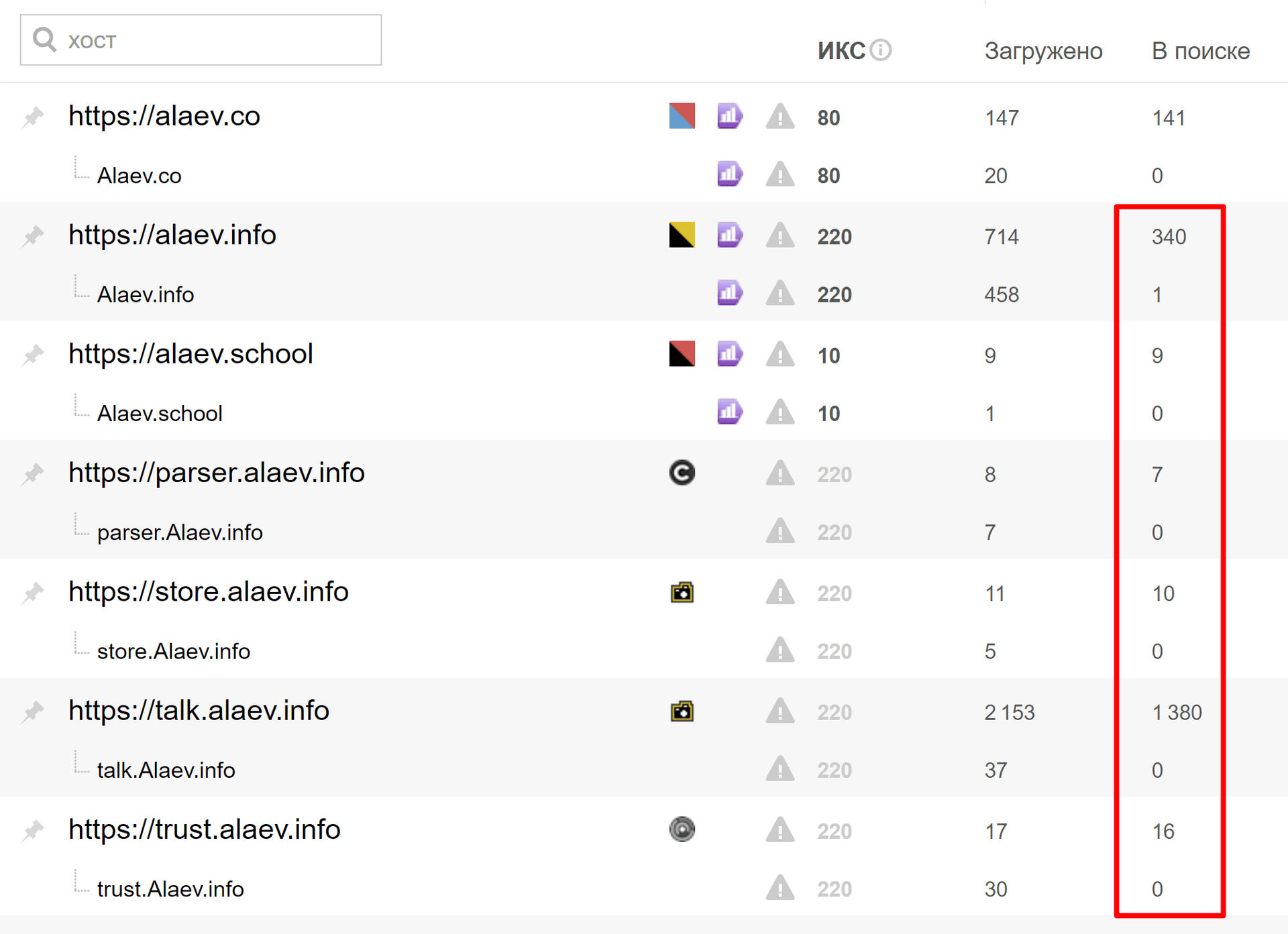
Как узнать проиндексирована ли страница в Яндексе
Используем оператор url: с указанием конкретного адреса страницы.
формат: url:[url страницы]
пример: url:https://alaev.info/blog/post/8742

Если выдача не пустая, значит страница проиндексирована. А если увидите «По вашему запросу ничего не нашлось» — значит страница не в индексе.
Как узнать сколько страниц (и каких) опубликовано на сайте за определенную дату
Используем следующие операторы:
site: – если хотим искать по основному домену и всем его поддоменам,
host: – если нужно искать только по основному домену,
date: – указываем дату появления в индексе (не забывайте, что я писал про данный оператор выше в разделе операторов Яндекса).
И еще есть замечательный оператор – * (звездочка) – с помощью которого мы можем указывать не только конкретный день, но и весь месяц или целый год.
формат: site:[example.com] date:[yyyymmdd]
пример: site:alaev.info date:2020*

На моем блоге за 2020 год появилось 5 новых постов, их появление повлекло за собой появление одной дополнительной страницы пагинации, и одна новая тема на форуме. Итого 7 штук!
А, например, в феврале 2021 года на блоге появились 2 новых поста и в одном из них я выкладывал чек-лист в форматах pdf и xlsx – они тоже проиндексировались и посчитались:

Напоминаю, что оператор date: работает не всегда так, как ожидаешь. Иногда результат совпадает, иногда нет. Чем дальше в историю (просмотр результатов за давнишние даты), тем выше вероятность получить неверный результат.
Как найти сайты, у которых в Title страницы имеется вхождение искомой фразы в Google
Например, у нас есть ключевой запрос «утюг недорого цена», и необходимо посмотреть, как реализовано вхождение этого запроса у конкурентов.
формат: allintitle:[ключевые слова]
пример: allintitle:утюг недорого цена

Пусть вас не смущает то, что в заголовке на выдаче не везде встречаются все три слова из нашего запроса. Во-первых, Гугл на свое усмотрение сокращает заголовки (в конце заголовка может поставить троеточие) и часть содержимого тега title с сайта не видна, во-вторых, Гугл на свое усмотрение может менять заголовок на более подходящий (по его мнению, разумеется). Во-вторых, если вы перейдете на сайты из выдачи, вы увидите, что в title каждого из них содержатся слова, которые мы указывали в запросе.
Как узнать, когда проиндексированы страницы в Яндексе
Чтобы отсортировать результаты поиска, необходимо в конец поисковой строки добавить &how=tm, и тогда напротив каждой страницы в выдаче появится отметка о времени индексации:

Жаль, что это не сочетается с другими операторами, например, site: или host:, а раньше это работало и можно было узнать, когда конкретно проиндексировались страницы сайта или конкретный url.
Как найти мусорные страницы по URL в Яндекс и Google
К мусорным страницам относятся, например: корзина (cart), регистрация (register, login), страницы пользователей (users), файлы (files), страницы сортировки (sort), страницы фильтров и поиска (filter, search).
Для того чтобы найти данные страницы, будем использовать оператор site: совместно с оператором inurl:, с помощью которого можно осуществлять поиск по страницам в URL которых есть заданный фрагмент.
формат: site:[example.com] inurl:[часть url]
пример: site:tatarcha.net inurl:auth
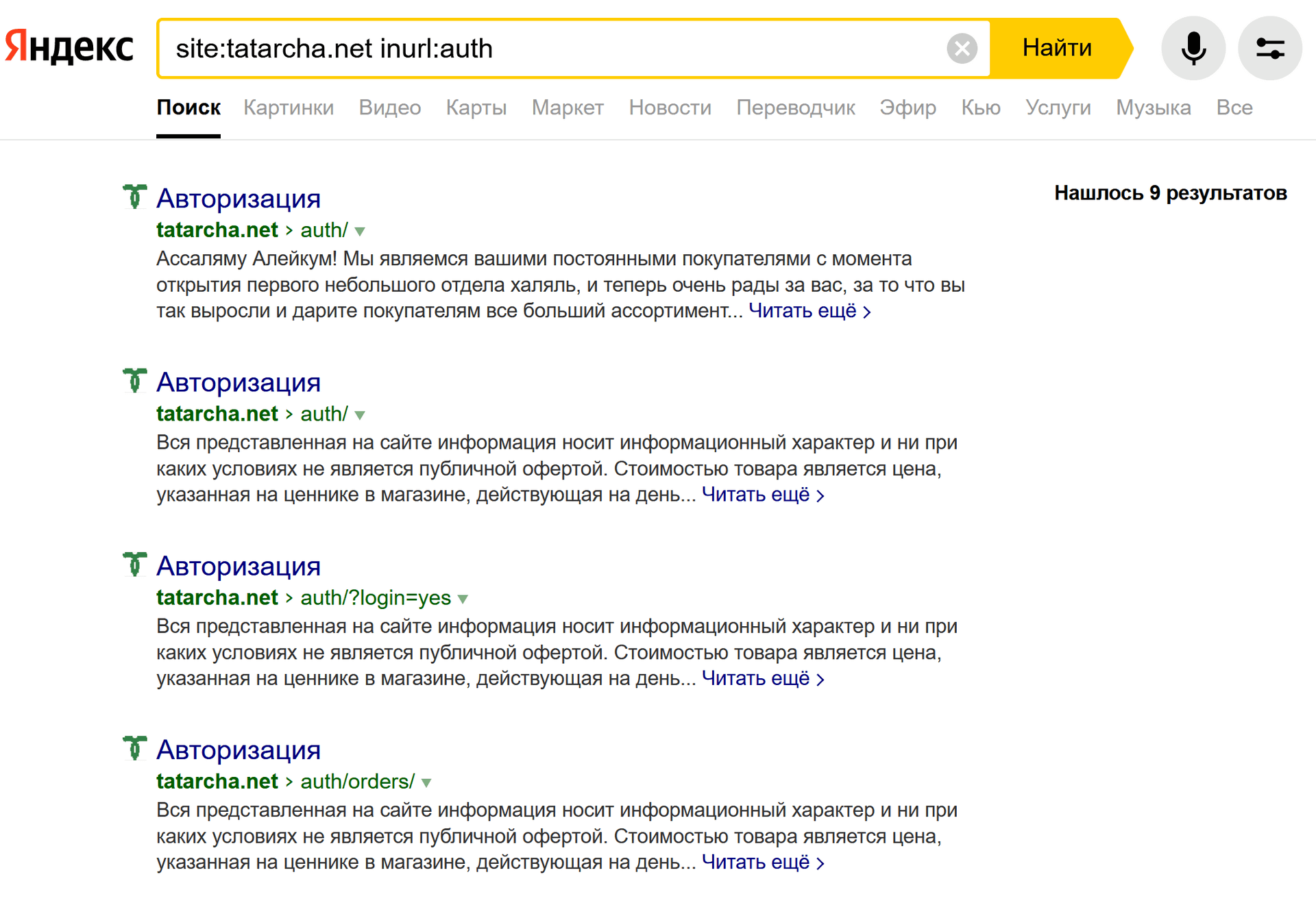
Смотрите, сколько дублирующихся ненужных страниц! Все это вредит продвижению, сами знаете.
В Google поиск осуществляется аналогичным способом. Только он предпочитает не показывать кучу одинаковых результатов.
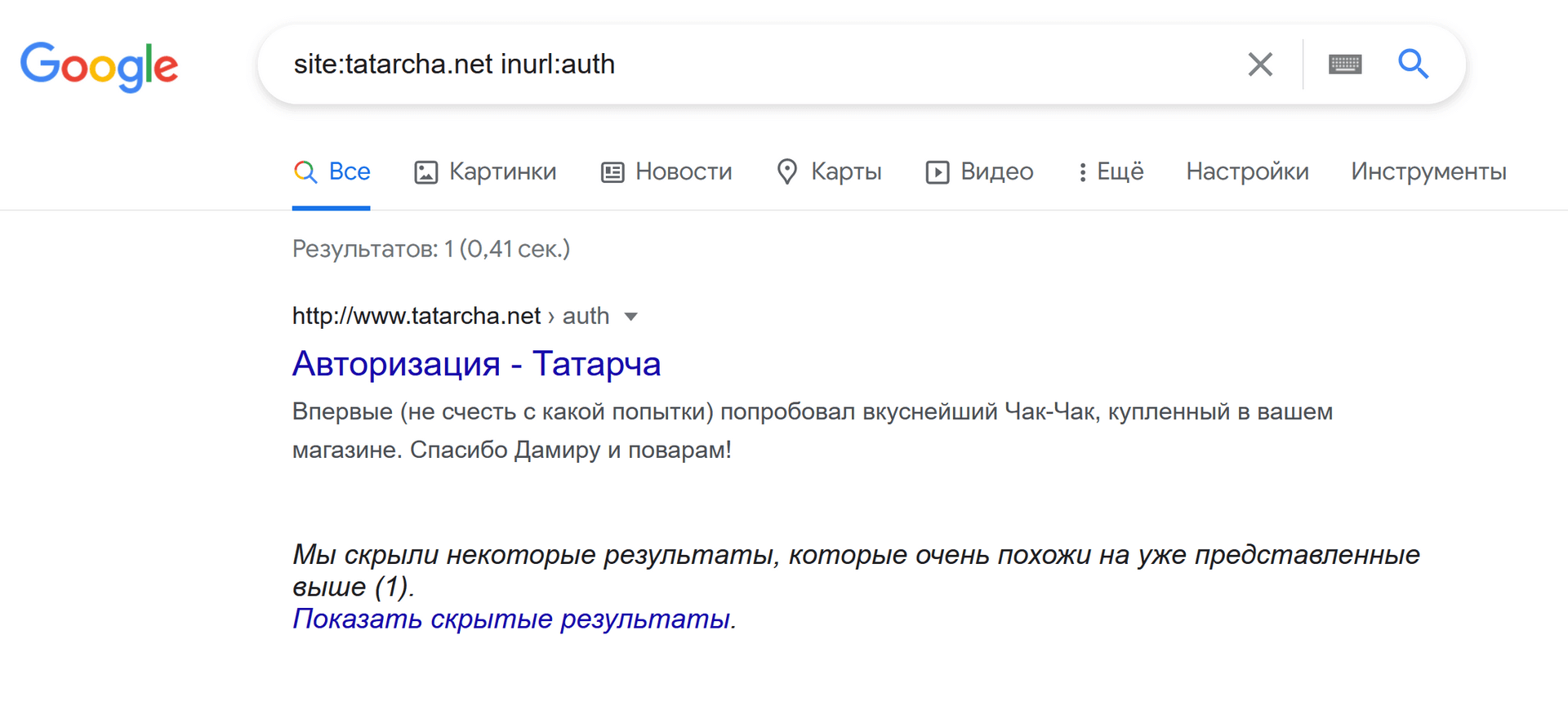
Если в url запроса добавить &filter=0, то Гугл сразу будет показывать в выдаче все скрытые результаты (вдруг пригодится).
Не забывайте, что для поиска фразы, а не одного слова, стоит использовать оператор allinurl:.
Кроме поиска мусорных страниц сочетание site: и inurl: / allinurl: можно, например, применять для поиска всех страниц конкретного раздела и определения их числа в индексе.
формат: site:[example.com] inurl:[/раздел/]
пример: site:robinzonada.ru inurl:/camps/

И тут надо сделать оговорку. Мы видим на скриншоте число 37. Но, если досмотрим до самого низа, увидим, что Гугл скрыл часть результатов.
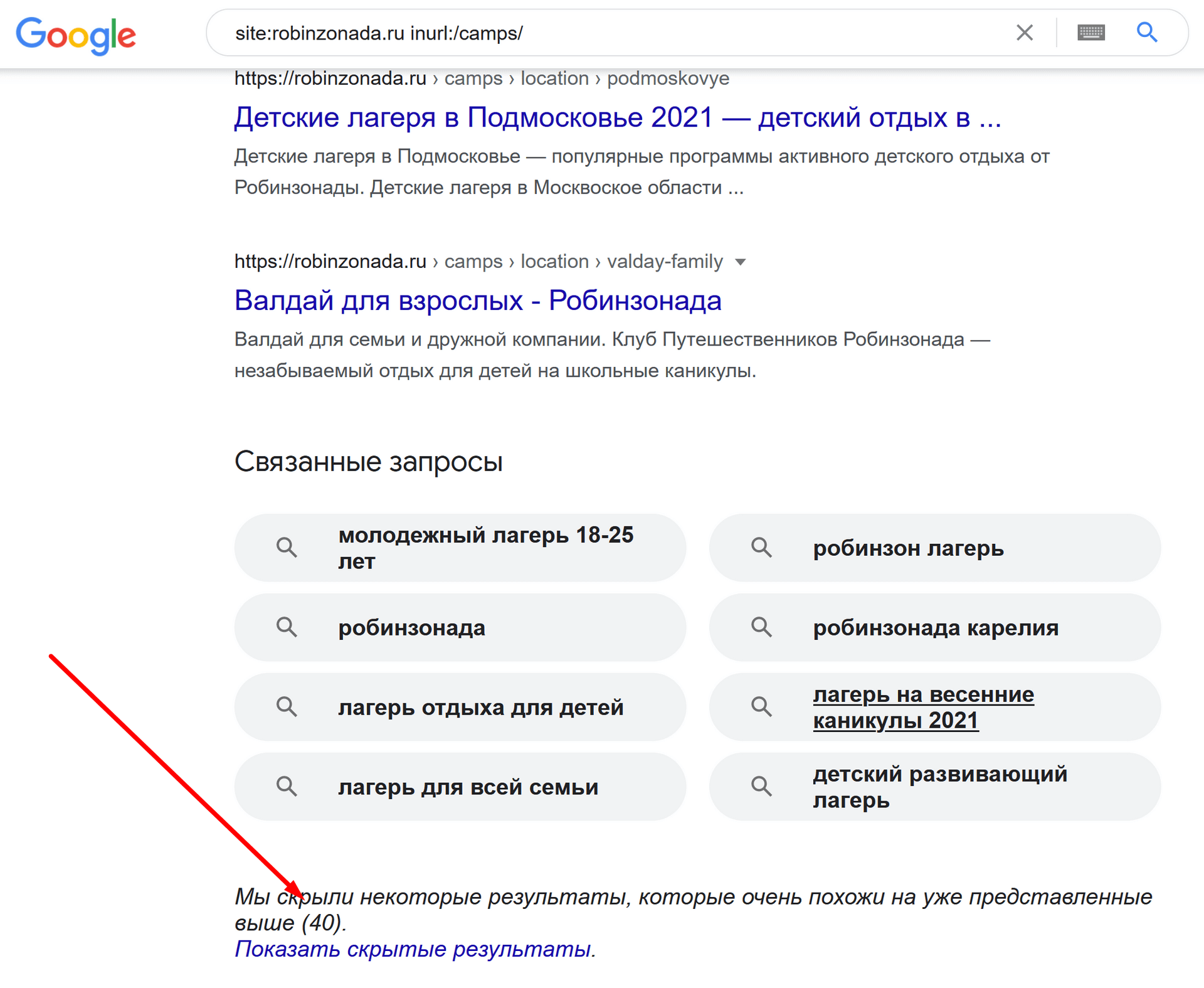
Окей, значит раз вверху было 37, а скрыто еще 40, значит страниц итого 77?
Жмем на «Показать скрытые результаты.»
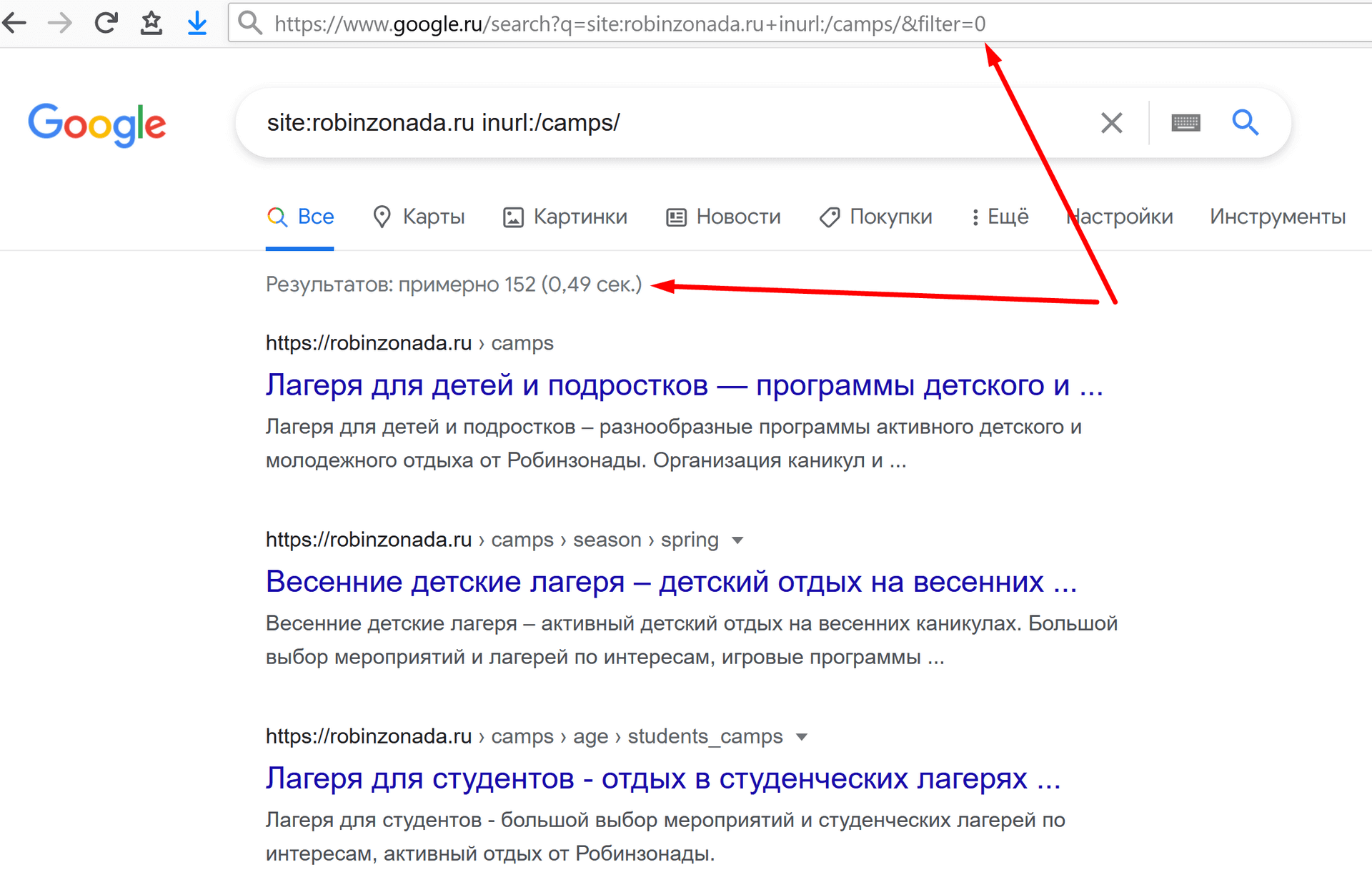
Хм… уже 152! И как это работает вообще?
Осталось только спуститься в самый низ и перейти на следующую страницу, число снова изменится.
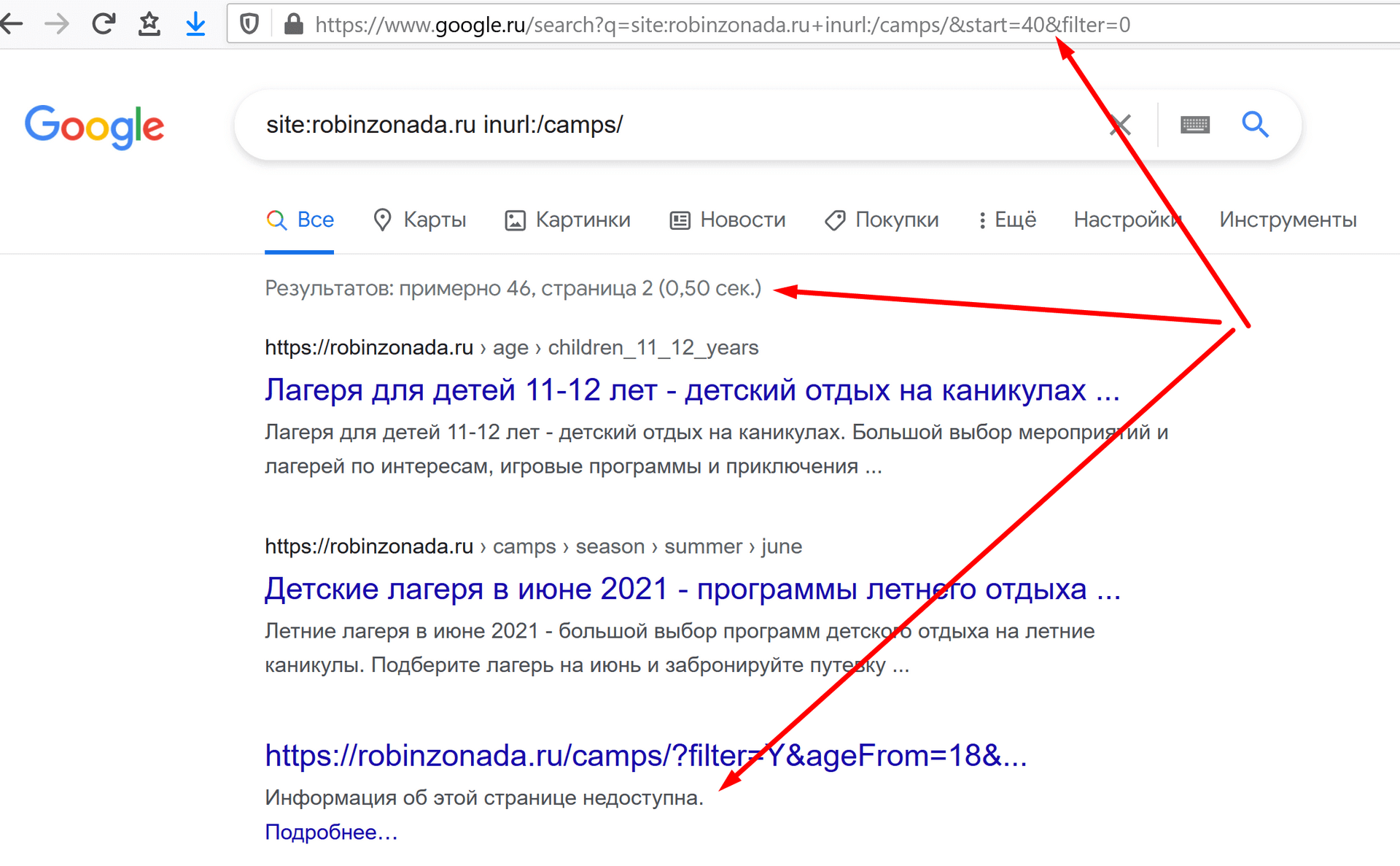
Реальное же (во всяком случае наиболее приближенное к реальному) число отобразится тогда, когда вы дойдете до последней страницы выдачи. В нашем случае наиболее точным числом оказалось 46.
Также я отметил один из результатов в сниппете которого написано «Информация об этой странице недоступна.» Это означает, что сайт не позволяет Google создать описание страницы, хотя она доступна посетителям. Проще говоря, страница закрыта в robots.txt, но ее адрес все равно индексирует робот Гугла, но саму страницу не сканирует.
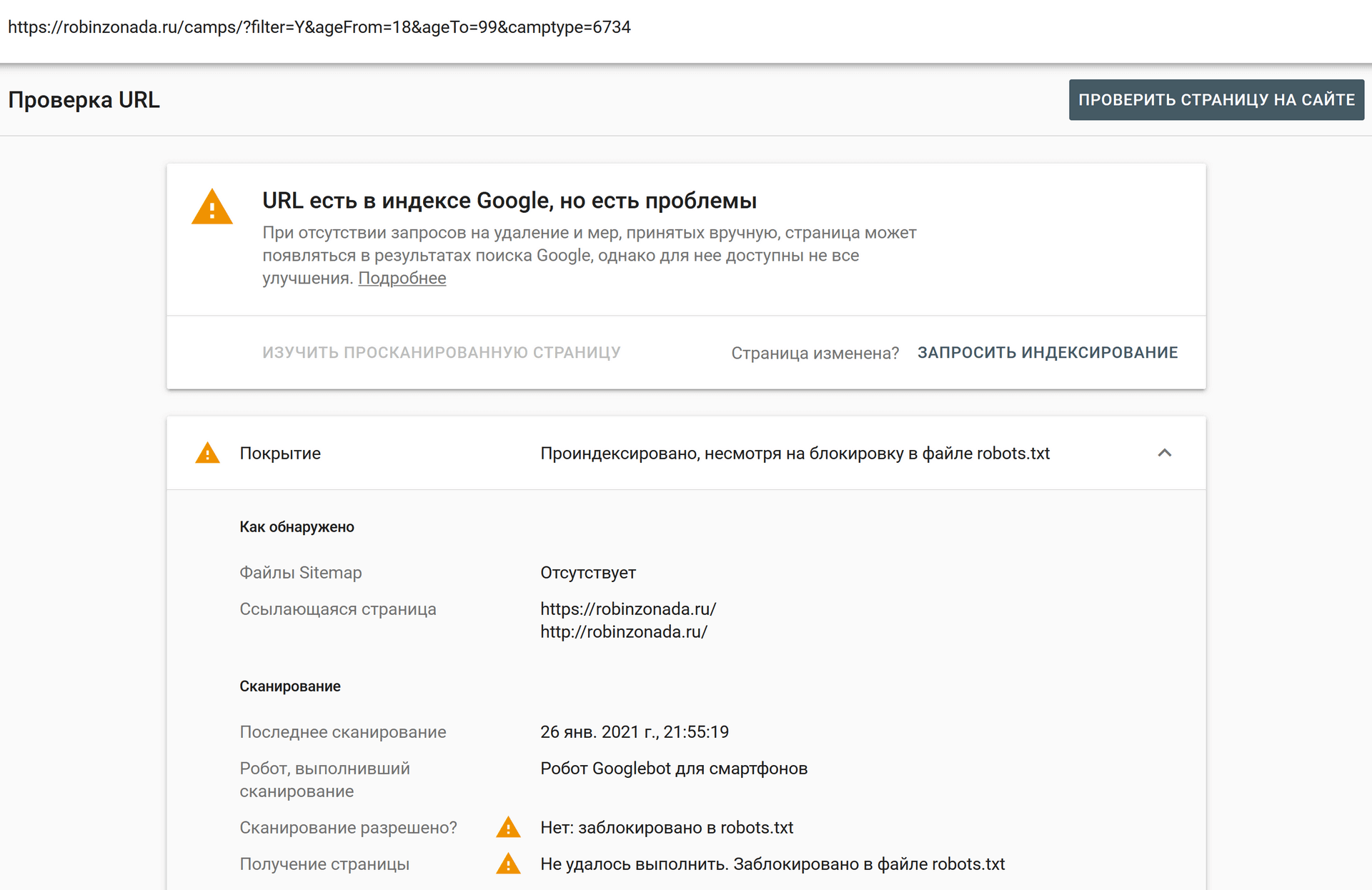
В Яндексе такого не бывает, но в Гугле всегда происходит именно так, поэтому если вы хотите, чтобы страница не индексировалась, стоит использовать запрещающий meta robots, а не robots.txt.
Поиск одинаковых товаров по фрагменту URL + их число в выдаче
Частный случай из предыдущего пункта – нужно узнать в каких категориях лежит один и тот же товар. В некоторых интернет-магазинах бывает такая ситуация, если положить один товар в несколько разных категорий и при этом ЧПУ формируется согласно иерархии, страница товара будет дублироваться столько раз, скольким категориям или подкатегориям товар принадлежит.
формат: site:[example.com] inurl:[фрагмент URL товара]
пример: site:gikom.ru inurl:metallicheskie-stellazhi-skladskie-mkf-1570
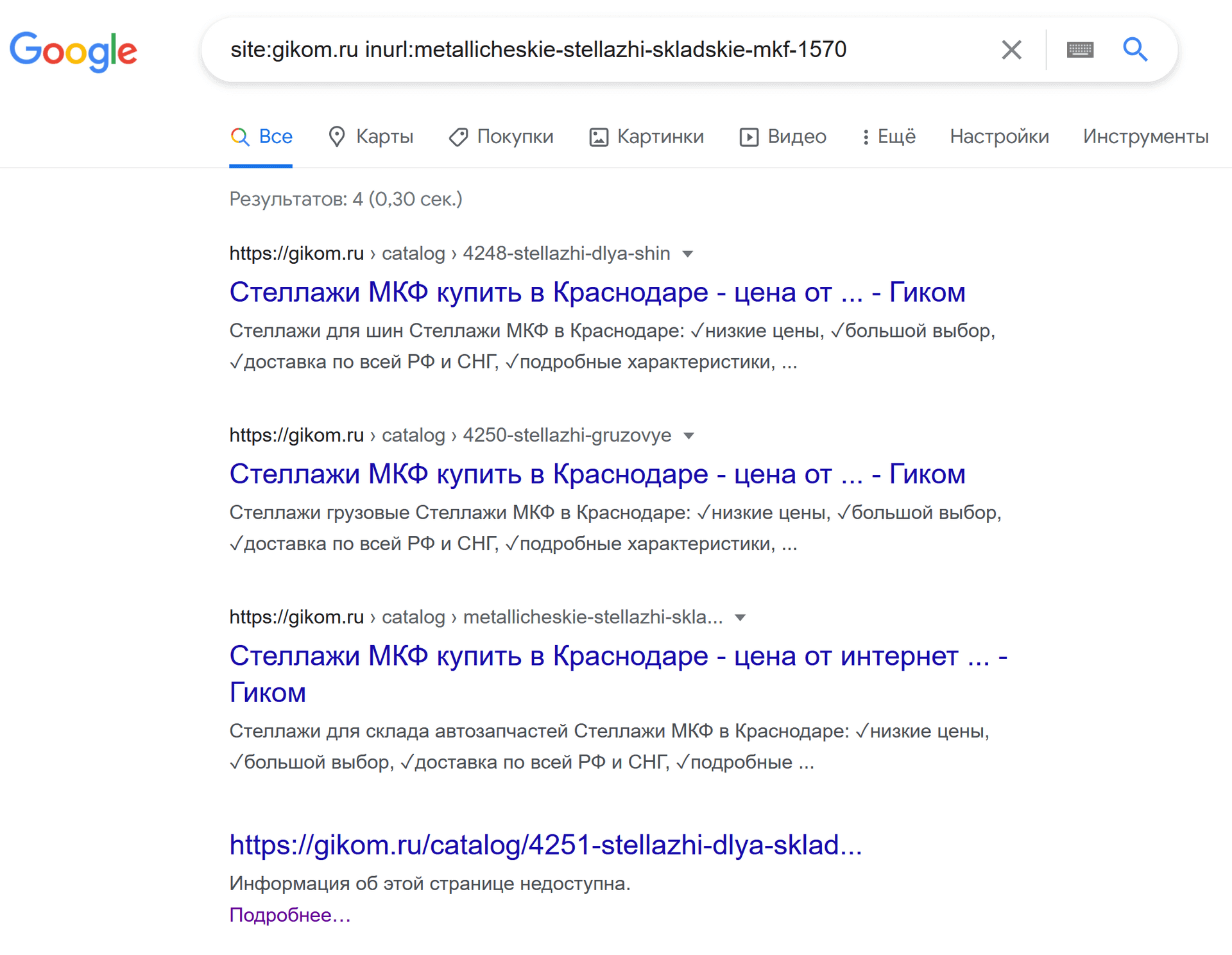
Это работает и в Гугле, и в Яндексе, только если вы хотите искать в Яндексе по указанному домену, надо использовать вместо site: оператор host:, иначе будут показываться результаты и с поддоменов:
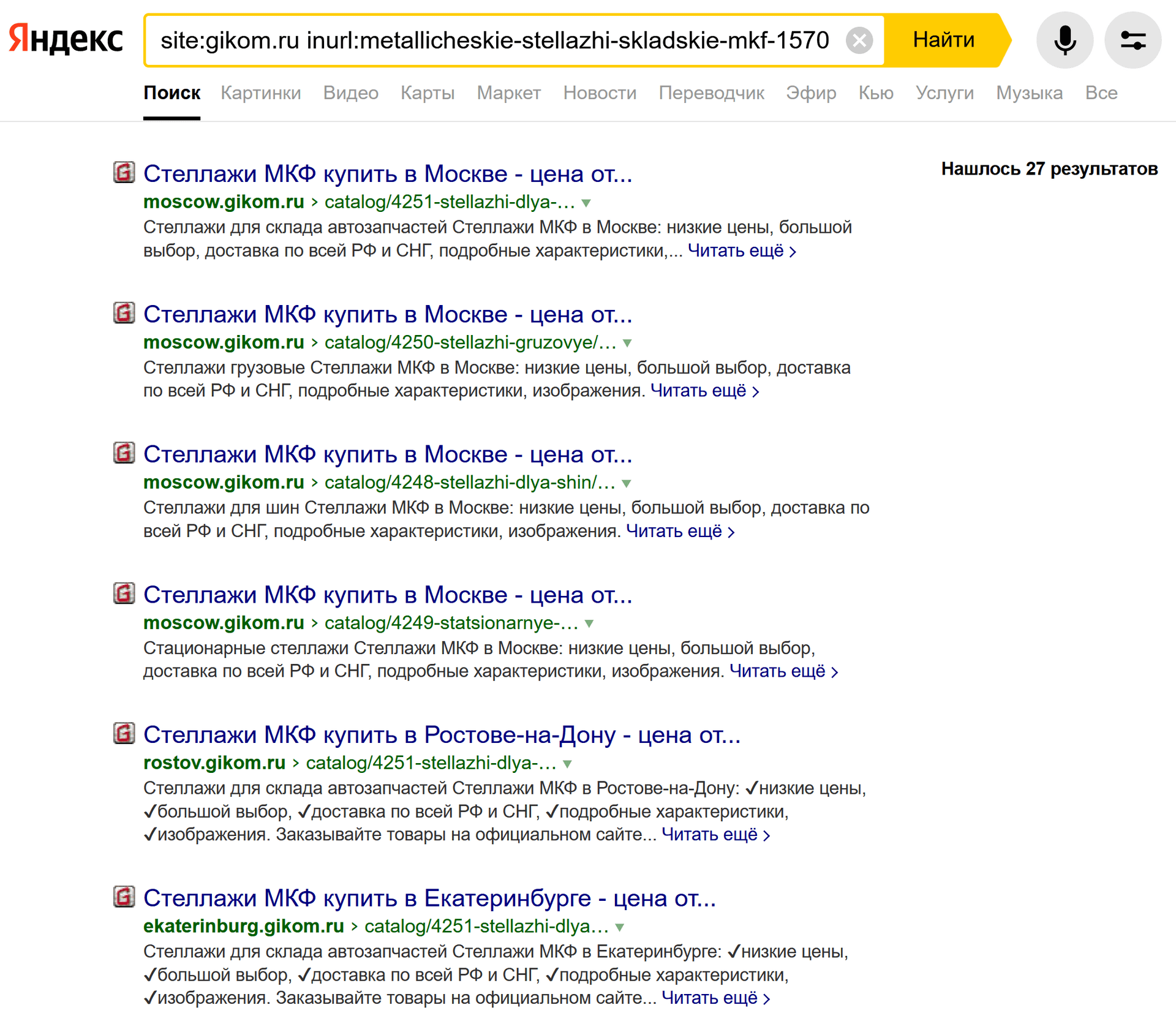
Проверка релевантности и каннибализации страниц
Если мы введем интересующий нас поисковый запрос и ограничим выдачу только страницами определенного сайта с помощью оператора site:, то поисковик выдаст нам страницы указанного сайта в порядке убывания релевантности запросу.
формат: [фраза] site:[example.com]
пример: перелинковка site:alaev.info
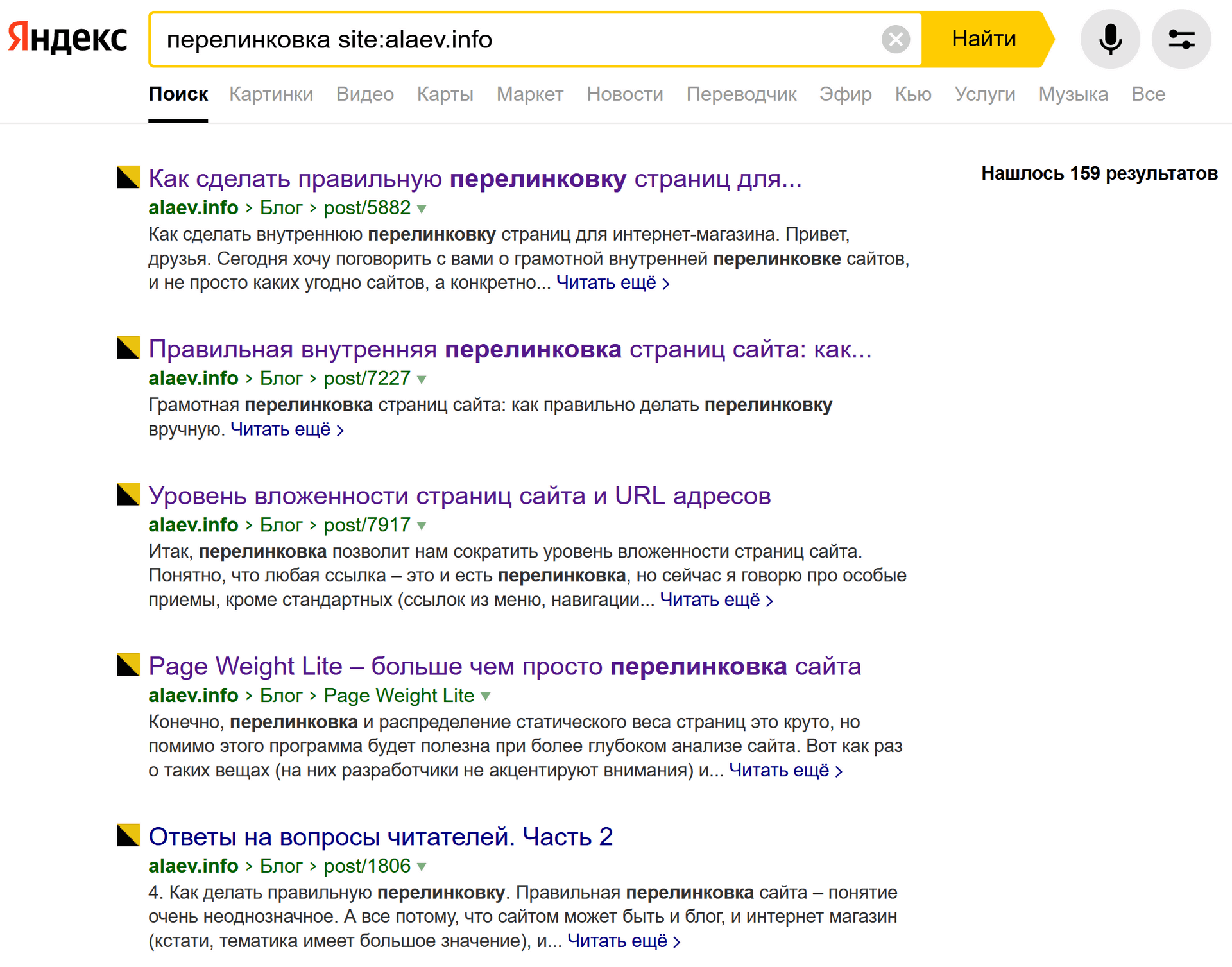
Что это нам даёт:
- Проверка страницы на фильтр переспама. Если на первом месте выдается не продвигаемая страница, а любая другая – есть вероятность, что мы имеем переспам по текстам. Необходимо проанализировать, почему наша целевая страница не является самой релевантной запросу.
- Если в топ-20 есть несколько страниц, заточенных под одинаковый ключ (мета-теги, h1, текст), – значит, есть риск получения каннибализации. Тогда велика вероятность, что поисковик будет считать релевантными разные страницы сайта, и в выдачу они будут попадать по переменке. Актуально для молодых сайтов, пока нет ссылочного профиля.
- Если на первом месте ранжируется нужная нам целевая страница, то все нижестоящие можно использовать для прокачки основной страницы за счет внутренней перелинковки, используя нужные ключевые слова. Это называется контекстная перелинковка страниц и, на мой взгляд, это самый эффективный вид перелинковки. Рекомендую ознакомиться с моим руководством по ссылке.
Поиск страниц с http в индексе Google
Наверняка вы уже перевели все свои или клиентские сайты на защищенный https протокол (если нет, читайте как перевести сайт с HTTP на HTTPS без потерь). И все же в Гугле переклейка страниц происходит довольно долго, а иногда и годы спустя в выдаче зачем-то остаются адреса страниц с http. Используя операторы site: и inurl:, мы вычитаем из поиска по домену результаты с https и получаем в остатке только http.
формат: site:[домен] -inurl:https
пример: site:www.yandex.ru -inurl:https
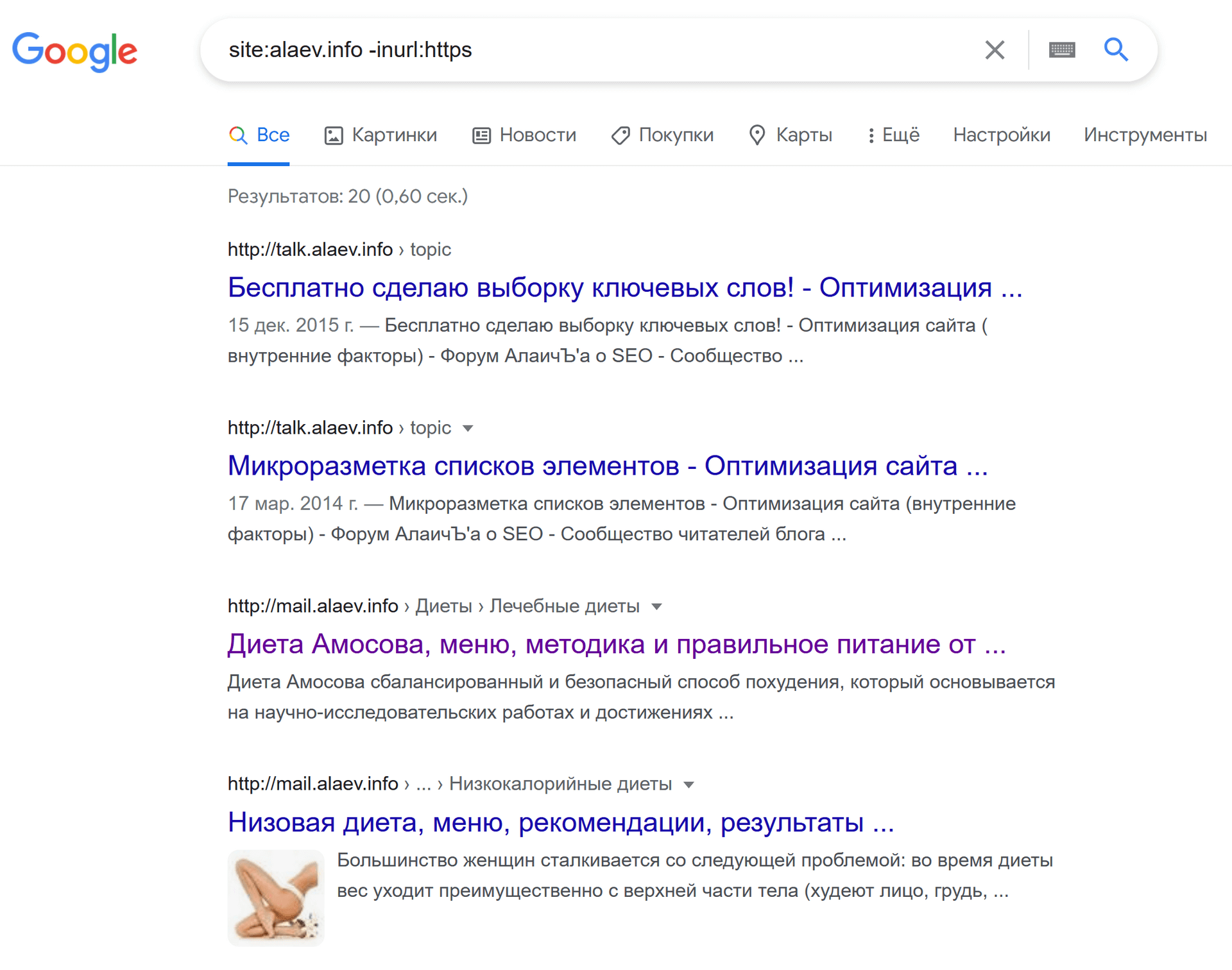
Задумка хороша, только вот реализация страдает. Гугл предпочитает в памяти хранить древние ископаемые. Начиная с того, что я уже больше двух лет назад переехал на https, а в индексе до сих пор болтается несколько http версий страниц форума. И заканчивая тем, что Гугл помнит, как в 2014 году случайно проиндексировалось зеркало моего диетного сайта на поддомене mail.alaev.info, который случайно появился при переезде на новый сервер. Я сразу же сделал 301-редирект, как только заметил это, но в индексе вот уже 7 лет болтаются эти результаты.
Так что когда будете проверять свой сайт, сначала проверьте, действительно ли проблема есть, либо это только кажется, как в моем случае.
Проверка поддоменов и числа их страниц в индексе Google
Мы можем посмотреть, какие поддомены есть в индексе Гугла, и сколько проиндексировано страниц в рамках этих поддоменов.
формат: site:*[example.com] -www
пример: site:*gikom.ru -www

В данном случае мы исключили из выдачи поддомен www, как зеркало основного сайта. Кроме того, что нам зачем-то понадобилось посмотреть количество страниц поддоменов в индексе (это актуально, когда мы только запускаем региональные поддомены и нам важно знать, как они индексируются), мы ведь можем найти то, чего не ожидаем, например, поддомены, которые мы не создавали, либо технические поддомены, на которых проиндексировалось зеркало сайта, как в предыдущем пункте про диетный сайт.
Как и говорил в самом начале, я открыл для себя несколько необычных свойств совершенно обычных операторов. А сколько интересного я не открыл?
Если вы знаете какие-то операторы, не упомянутые в посте, либо в своей работе используете определённые сочетания, о которых я не знаю, и я и все читатели блога будут вам благодарны, если вы поделитесь в комментариях.
Так что, возможно, будет продолжение :)
Спасибо за внимание, друзья! До связи!

это какой-то шикардосик!
в закладоньки
Развлекайтесь https://www.exploit-db.com/google-hacking-database
На первый взгляд интересно, фактически же — не очень. Большая часть устарела.
Но как пища для ума может быть интересным :)
Дочитал до слов взвился подо мной... Пропел. Собрался. Продолжил читать, и... Тут бац! Нашествие. Пошел вспоминать нашествие. Дочитаю в след. раз)
Круто быть на одной волне :)
Большое Вам спасибо!
Очень интересно. Буду перечитывать.
Возможно не внимательно читал, быстро.
Но у меня есть один вопрос, и я не совсем понял ответ.
Где правда?
В веб-мастере страниц в индексе гораздо больше, чем по оператору site:
Нашёл статью, где интересующемуся как я, ответил Яндекс и сказал, что оператор site: показывает более достоверную информацию.
Подскажите, пожалуйста.
А в вебмастере смотрите поле "В поиске", а не "Загружено"? Я как раз показывал пример выше, где заголовок: Как узнать количество страниц в индексе Яндекса для сайта и всех его поддоменов.
Также напоминаю, что оператор site: показывает данные для домена и всех его поддоменов, а оператор host: только для конкретного домена.
Здравствуйте! Огромное спасибо, свела в табличку все операторы, буду пользоваться и вносить замечания.
Половины из описанного не знал, — спасибо большое! Вижу огромное поле для анализа конкурентов, наиболее часто встречающихся в топе. Мне всегда было интересно именно в ТОП3 делать настолько подробный анализ. Остальные 7 мест в выдаче можно и по шаблону проанализировать (особенно полезными вижу операторы для поисмка по определенным словам и файлам,)
Огромная благодарность, Вам за столь полезную информацию! Теперь есть готовая инструкция для наших начинающих специалистов)
Приветствую. Оператор host работает некорректно.
Пример сайт озон по Google (оператор site) 13.5 млн в индекса, в Яндексе (оператор host) 68 тыс. И так почти по всем сайтам более 10к страниц.
Работает как работает, что тут поделаешь. По словам представителей поисковых систем, точные данные только в панелях вебмастера можно увидеть. А без этих доступов довольствуемся там, что дают :)