 Привет, друзья. Надеюсь, вас не смутит тема о том, как правильно пользоваться Yandex Wordstat. Оказалось, что мало кто умеет работать с Вордстатом хотя бы чуть больше, чем просто вбить слово и проверить точную частотность. А ведь зная несколько нехитрых операторов можно сэкономить время и повысить свою эффективность просто в разы. И такой пост просто обязан быть на моем блоге по нескольким причинам.
Привет, друзья. Надеюсь, вас не смутит тема о том, как правильно пользоваться Yandex Wordstat. Оказалось, что мало кто умеет работать с Вордстатом хотя бы чуть больше, чем просто вбить слово и проверить точную частотность. А ведь зная несколько нехитрых операторов можно сэкономить время и повысить свою эффективность просто в разы. И такой пост просто обязан быть на моем блоге по нескольким причинам.
Во-первых, это руководство для наших стажеров в «АлаичЪ и Ко», во-вторых, это пригодится ученикам из моей seo-школы. А в-третьих, это подробная инструкция для всех новичков, которые посещают мой блог, который как раз наполовину и состоит из таких инструкций. Однажды из моего блога можно будет собрать полноценную книгу для изучения всех тонкостей SEO :) Я это почти серьезно.
Еще мои коллеги написали подробный обзор плагинов для автоматизации работы с вордстатом для Firefox и Chrome: плагины и расширения для работы с Yandex Wordstat: Assistant, Helper, Keywords Add и WordStater.
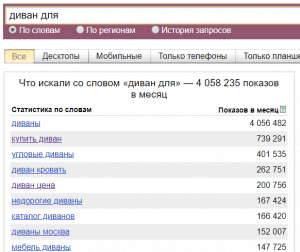
Wordstat Yandex — это сервис со статистикой показов слов или фраз, которые пользователи вводят в поиск Яндекса, с возможностью уточнения региона пользователей и просмотром данных по месячным и недельным срезам, а также с уточнением устройства пользователя: ПК или мобильные устройства. Сервис содержит подробную статистику запросов к Яндексу за последние 30 дней от даты обновления (дата показывается при просмотре статистики под кнопкой «Подобрать»):

Сервис нужен для:
- подбора ключевиков для контекста, SEO и т. д.;
- анализа сезонности того или иного ключевика;
- оценки спроса в конкретных регионах.
Но мы с коллегами написали специальное расширение для браузеров, которое, кроме остальных полезных для seo-специалиста фишек, возвращает поиск и выбор всех регионов.
Подробности тут: Из Яндекс Вордстат пропали регионы, но я их вернул!
Как пользоваться Вордстатом?
Для просмотра статистики по фазе или отдельно взятому слову его необходимо ввести в поле (1) и нажать кнопку «Подобрать» (4). Обратите внимание, что статистика в сервисе по умолчанию отображается по словам (2) и показывается сразу по всем регионам (3).
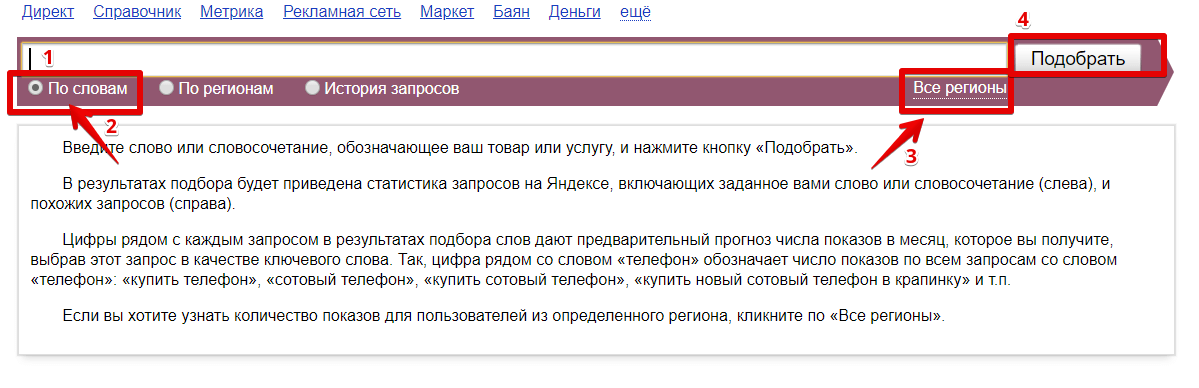
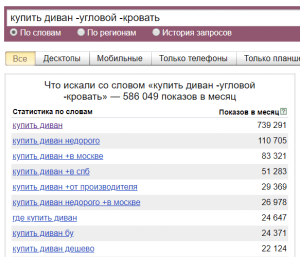
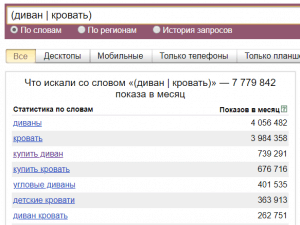
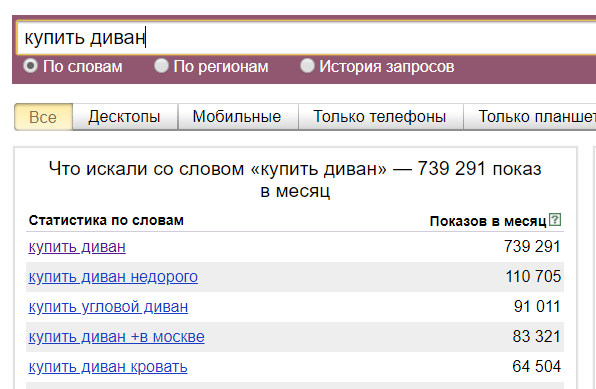
Рассмотрим конкретный пример: мы хотим узнать сколько человек ежемесячно вводит фразу «купить диван»:
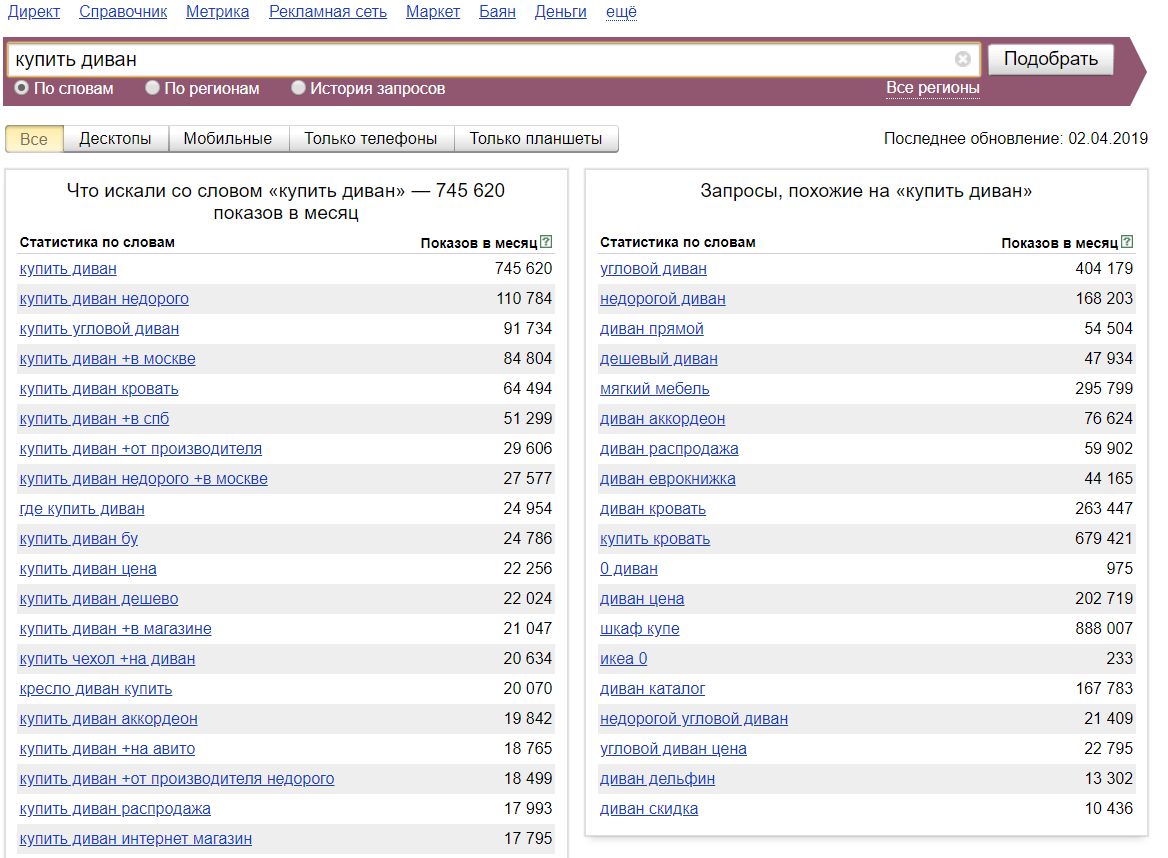
Мы видим 745 620 «показов в месяц», что это значит? Показы — это суммарное число всех поисковых запросов к Яндексу за последний месяц, которые содержат в себе введенные нами слова «купить» и «диван» одновременно.
Ниже можно увидеть две колонки с данными: в левой находятся сами фразы, в которых содержатся наши искомые слова «купить» и «диван», а в правой колонке Яндекс автоматически формирует список похожих запросов.
В левой колонке все фразы отсортированы по частотности запроса от большей к меньшей, в правой отсортированы по степени схожести, причем эту степень определяет сам Яндекс, и пользователь никак не может повлиять на формирование этого списка. Например, если вы захотите убрать ненужные фразы и посмотреть следующие похожие фразы, то сделать это никак не получится.
Виды частотностей Wordstat
Что такое «показы» (или как ее еще называют — «общая частота») мы выяснили выше — это совокупность всех ключевых запросов к Яндексу, содержащих одновременно все слова, которые мы указали в Вордстате.
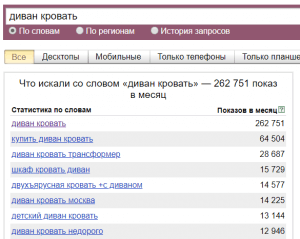
Есть еще «частота в кавычках», ее еще называют «фразовая частотность» — это количество запросов к Яндексу, которые содержат ТОЛЬКО те слова, которые мы указали в Вордстате. Чтобы ее увидеть необходимо в Вордстате заключить все слова в кавычки, отсюда и название.
Пример: "купить угловой диван"
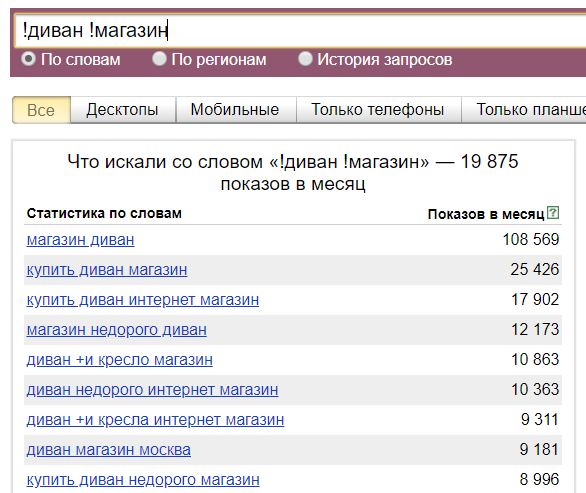
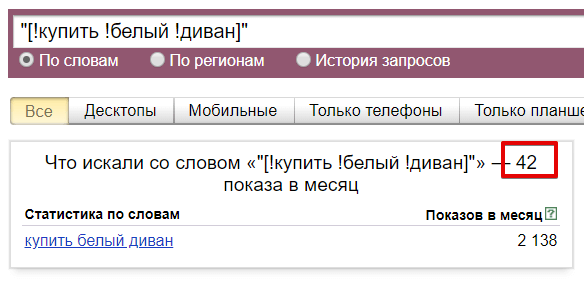
Для тех, кто хочет получить статистику по точным запросам существует такое понятие как «точная частотность» — это количество всех запросов к Яндексу, в которых присутствуют только те слова, которые мы указываем в вордстате и только в указанной словоформе. Для того, чтобы посмотреть такую статистику необходимо в Вордстате заключить все слова (все, а не каждое) в кавычки и перед каждым словом поставить восклицательный знак.
Пример: "!купить !угловой !диван"
Ну а кому и этого недостаточно, то можно еще задать уточнение по порядку слов в запросе, чтобы учитывалась статистика только тех фраз, в которых слова расположены только в заданном порядке. Для этого нужно проделать все, как в пункте выше, но дополнительно заключить весь запрос в квадратные скобки, при этом кавычки должны быть снаружи скобок, а не наоборот, иначе Вордстат выдаст ошибку.
Пример: "[!купить !угловой !диван]"
Ниже мы все это еще раз разберем с примерами и скриншотами.
Операторы Яндекс Wordstat
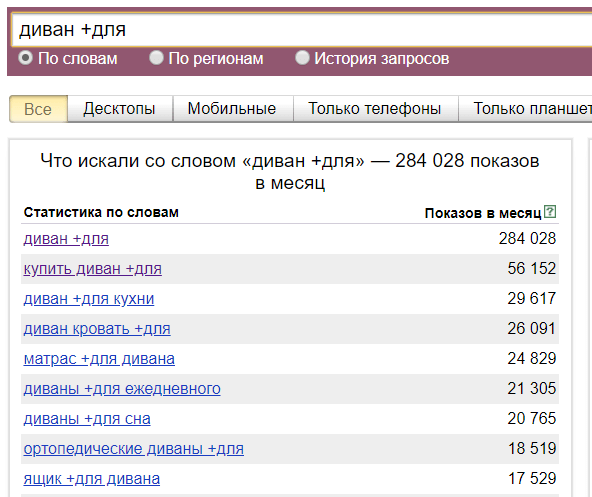
Все данные напротив фраз по умолчанию отображаются в виде общего числа показов т. е. как было сказано выше: для фразы «купить диван» при подсчете частотности показов будут учтены все фразы в которых есть эти слова, например «купить кожаный диван», «купить белый диван» и т. д. Поэтому, при сборе семантики, почти всегда необходимо пользоваться дополнительными операторами вордстата, которые помогают задавать различные уточнения к запросам. Рассмотрим эти операторы:
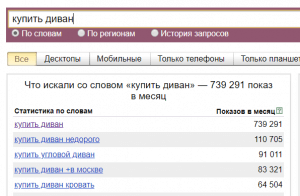
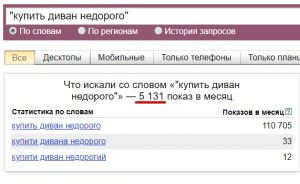
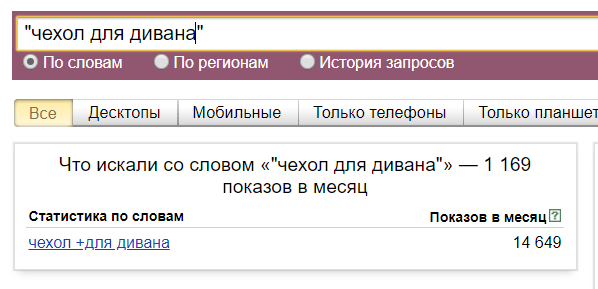
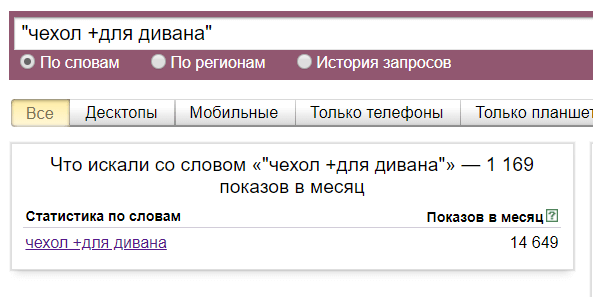
- Оператор «» (кавычки). Кавычки позволяют ограничить статистику только по заданным словам. На скриншоте ниже у фразы «купить диван недорого» общее число показов 110 705 раз в месяц, но запрос только из этих трех слов вводят всего 5 131 раз в месяц. Кавычки ограничивают статистику только по словам, но порядок расположения слов и их окончания не учитываются.
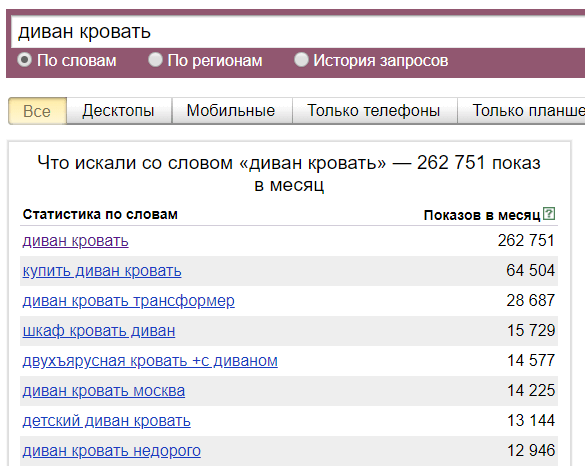
- Оператор «!» (знак восклицания). Позволяет зафиксировать словоформу. При использовании этого оператора в статистике будут учитываться фразы только с заданным окончанием слов, однако порядок слов в запросе учитываться не будет.
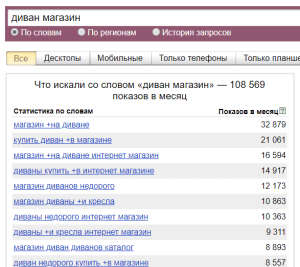
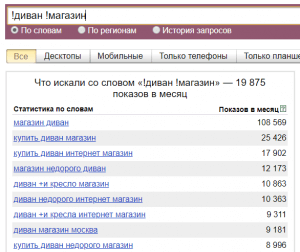
- Оператор «[ ]» (квадратные скобки). Позволяет задать нужный порядок слов в запросе. Оператор не ограничивает запрос указанными словами и не фиксирует словоформу.
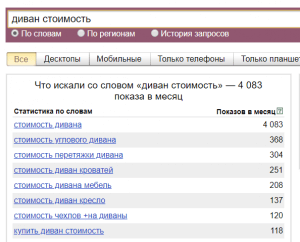
![Статистика по фразе [диван стоимость]](https://alaev.info/wp-content/uploads/2019/04/wordstat-9-300x277.png)
![Статистика по фразе [диван стоимость]](data:image/svg+xml,%3Csvg%20xmlns=%22http://www.w3.org/2000/svg%22%20viewBox=%220%200%20300%20277%22%3E%3C/svg%3E)
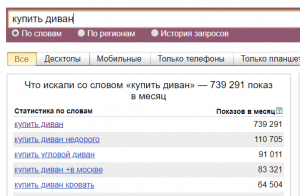
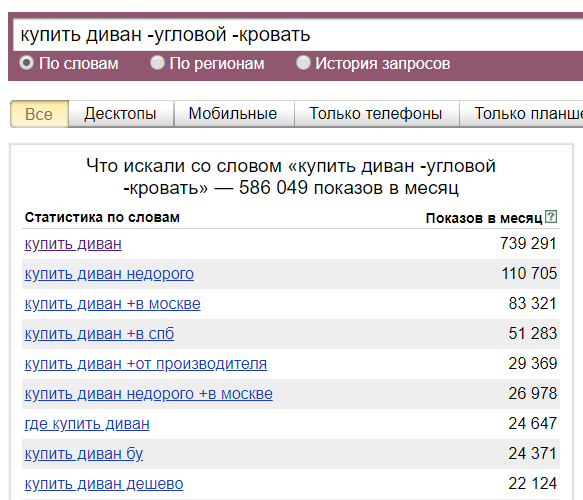
- Оператор «-» (минус). С помощью него можно задать минус-слова, которые будут исключены из статистики показов. Минусовка проставляется перед каждым словом, которое должно быть удалено из статистики, без пробела.


- Оператор «+» (плюс). Нужен для учета стоп-слов, таких как союзы или предлоги (в сервисе Яндекс Вордстат они изначально не учитываются).

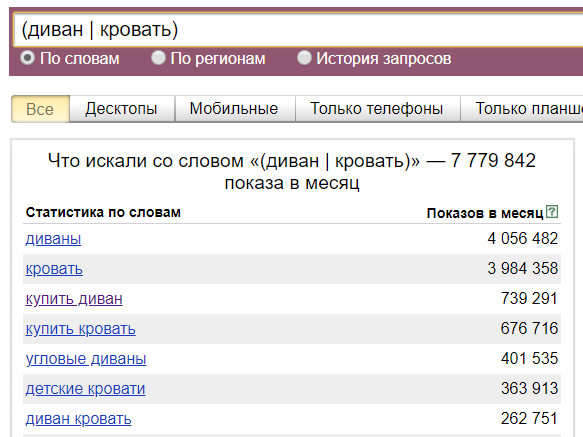
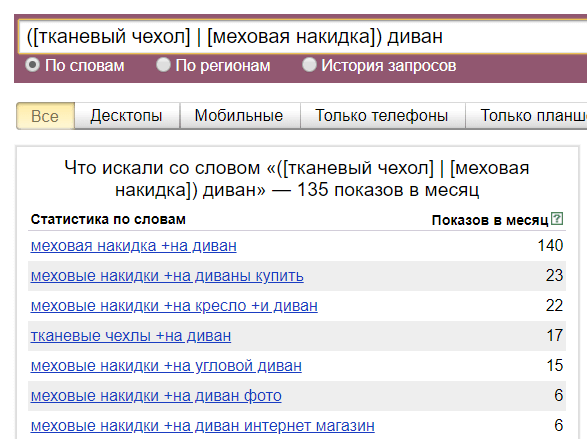
- Оператор «( | )» (логическое «или»). Используется вместе со скобками. Оператор позволяет отобразить статистику сразу по нескольким условиям.



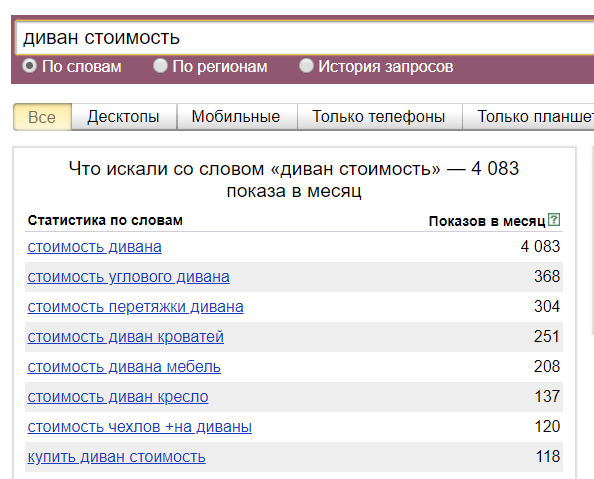
![Статистика по фразе [диван стоимость]](https://alaev.info/wp-content/uploads/2019/04/wordstat-9.png)
Использование нескольких операторов и лайфхаки
Выше мы разобрали основную теорию касательно операторов в Вордстате, однако одного знания теории мало, нужны практические примеры их использования! В этом блоке как раз поговорим о том, как и для чего можно использовать различные связки операторов в запросе.
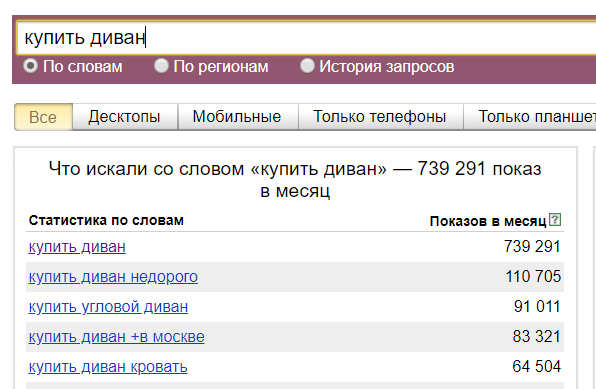
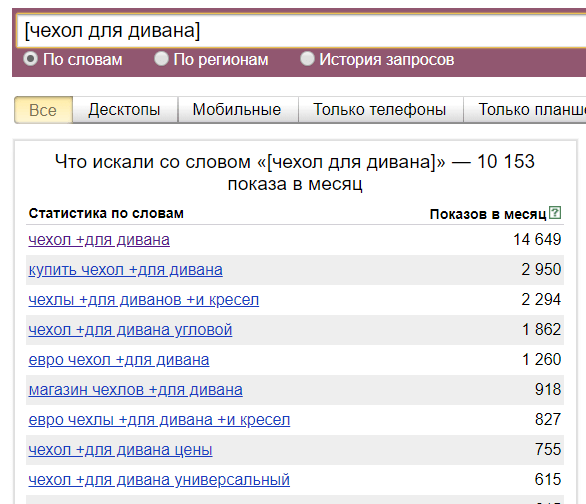
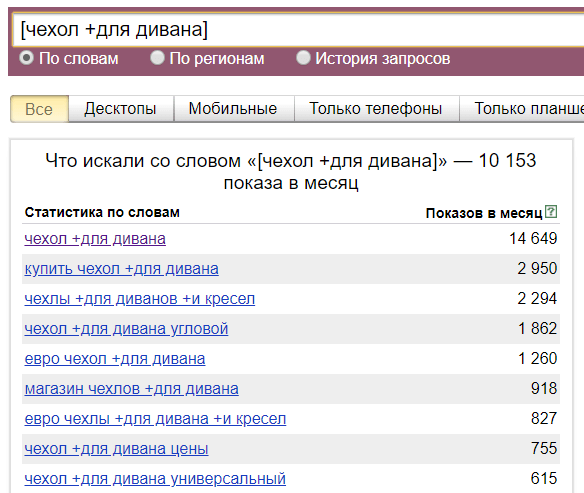
- Допустим, нам нужно понять сколько трафика мы можем получить по единичному запросу «купить белый диван» с учетом словоформы и порядка слов.
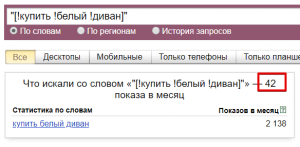

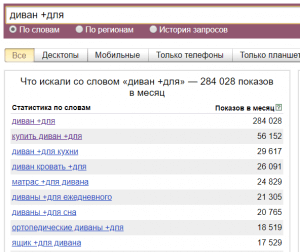
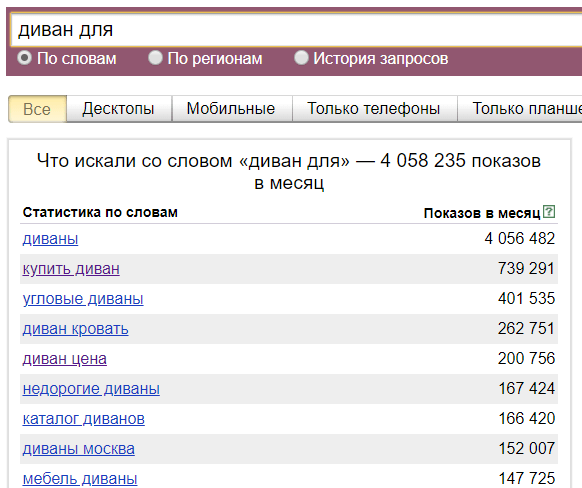
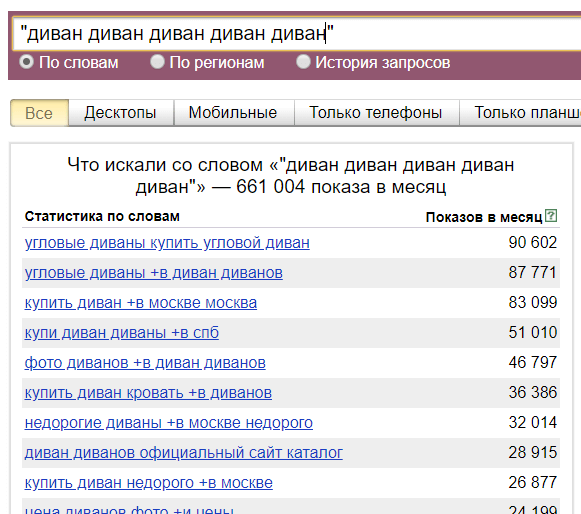
(Разумеется, данная цифра не показывает количество трафика, который мы получим, ведь надо учитывать регион, позицию сайта в поиске и её CTR, количество объявлений в Яндекс.Директ и много еще чего.) - Если мы хотим увидеть все 5-словные запросы, содержащие слово «диван» достаточно указать слово диван 5 раз и взять в кавычки:
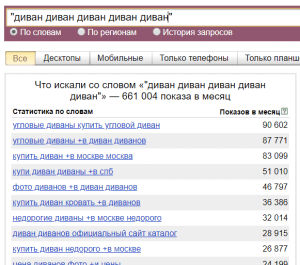

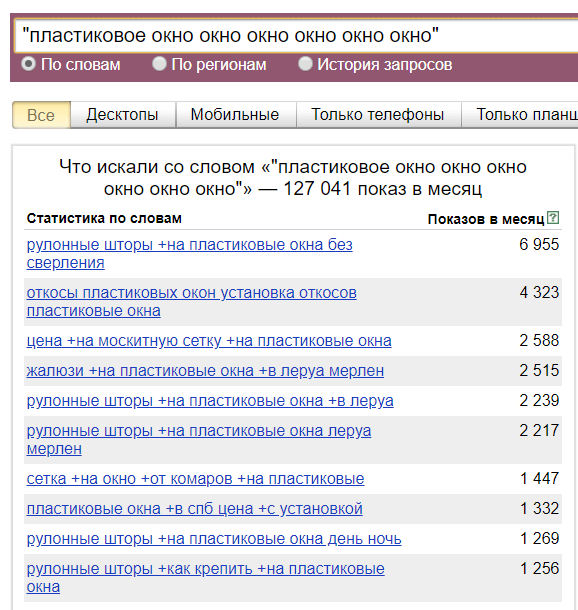
С помощью этого лайфхака можно получать список очень длинных запросов, которые, как правило, сложно получить другими способами.- Но что делать, если нам нужно получить, скажем, все семисловные запросы по пластиковым окнам? Если мы укажем 7 раз слово окно, то не факт, что все запросы будут именно про пластиковые окна и наоборот — если укажем 7 раз слово пластиковое, то не факт, что запросы будут про окна. В таких случаях нужно вписать в кавычки все обязательные слова, которые должны быть в статистике и повторить любое из этих слов нужное количество раз, смотря сколько слов мы хотим получить в запросе:
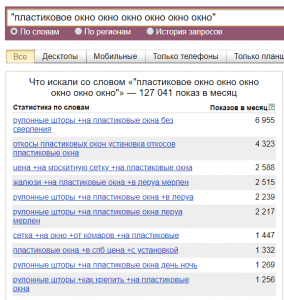

- Но что делать, если нам нужно получить, скажем, все семисловные запросы по пластиковым окнам? Если мы укажем 7 раз слово окно, то не факт, что все запросы будут именно про пластиковые окна и наоборот — если укажем 7 раз слово пластиковое, то не факт, что запросы будут про окна. В таких случаях нужно вписать в кавычки все обязательные слова, которые должны быть в статистике и повторить любое из этих слов нужное количество раз, смотря сколько слов мы хотим получить в запросе:
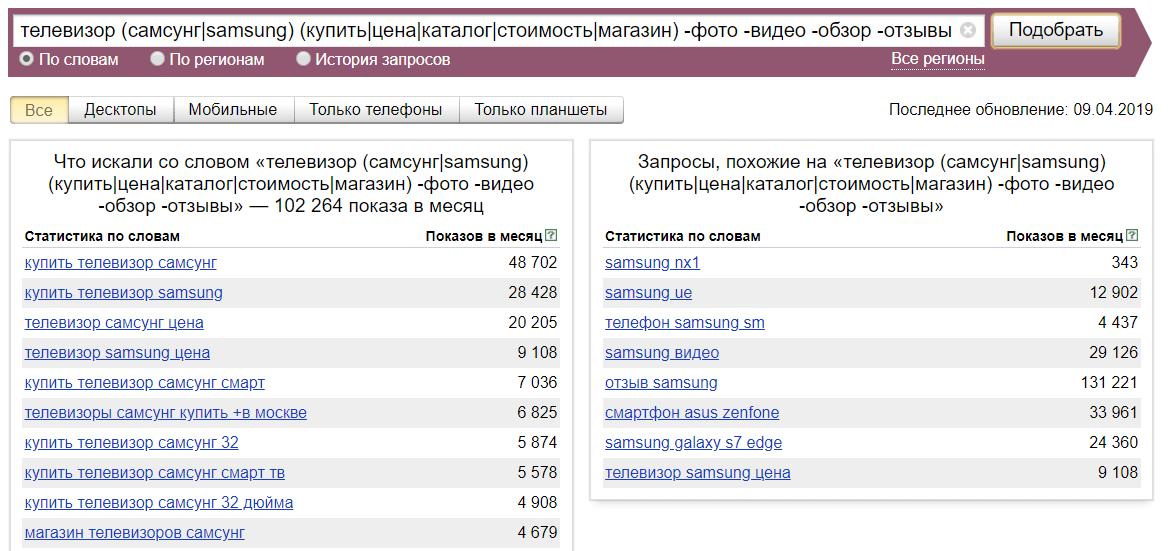
- Случаются ситуации, когда нужно подобрать только коммерческие ключевые фразы для брендовой продукции, например, телевизоры Samsung, при этом учесть написание бренда на латинице и кириллице и дополнительно — убрать из статистики информационные запросы. Не проблема — используем связку операторов «скобки», «логическое или» и «минус»:
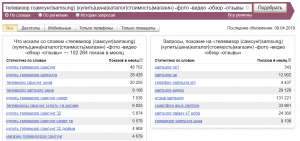

Особенности в работе Wordstat операторов
Выше мы рассмотрели примеры использования операторов, но у них есть свои ограничения и особенности, например: если вы задаете запрос в квадратных скобках или кавычках, то по умолчанию учитываются все слова в запросе, в том числе предлоги с союзами, поэтому нет необходимости ставить перед ними плюс:
 |  |
 |  |
Внутри операторов «кавычки» или «квадратные скобки» не получится использовать операторы «-», «|», «()»:
 |  |
 |  |
Хотя использовать квадратные скобки внутри круглых допустимо:
Оператор «кавычки» нельзя применить только к части запроса:

Правила Вордстата по учету словоформ
Для начала стоит понять, какие слова Wordstat воспринимает как словоформы:
- Склонение по числительным и падежам (диван, диваны, диванами, диванов);
- Глаголы, их спряжения, причастия и деепричастия (прочитать, прочел, прочитавший, прочитанный);
- Слова с использованием буквы «е» или «ё» (ерш, ёрш);
- Степень и форма прилагательных, падежи, числа (сильный, сильнее, сильнейший).
А в каких случаях фразы не будут считаться словоформами:
- Опечатки (апрель, опрель);
- Транслит, написание на латинице или кириллице (вордстат, wordstat);
- Жаргон/сленг (учительница, училка);
- Составные слова (бензопила, бензо пила);
- Изменение слов за счет приставок (шел, пришел, зашел);
- Уменьшительно-ласкательные слова (куртка, курточка);
- Числительные с разным написанием, но одним значением (5, пять).
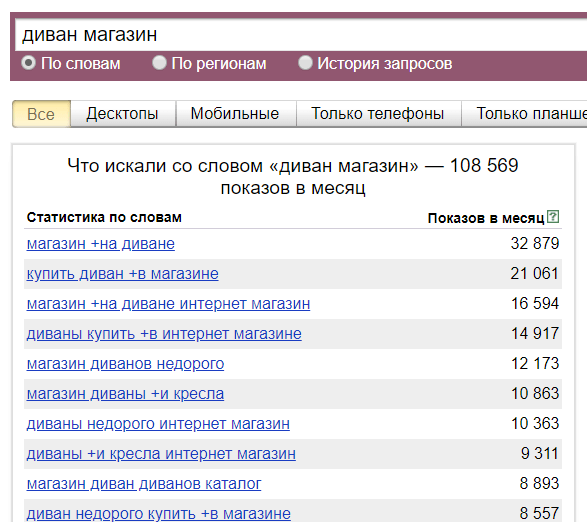
Использование фильтров в Вордстате
Тип устройств и регион
Любые данные в Вордстате можно посмотреть в разрезе по типам устройств. Это может быть полезно при сборе фраз под рекламу мобильного приложения, либо если для ПК- и мобильной аудитории ведется отдельная аналитика с построением разных прогнозов по трафику.
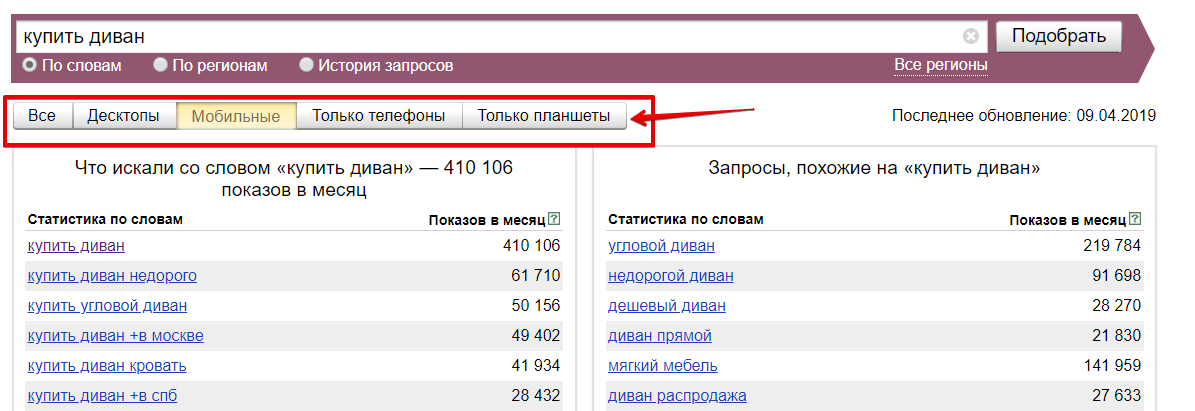
И в разрезе по регионам. Если у вас интернет-магазин с доставкой только по Москве, то можно оценивать спрос только по этому региону. Есть возможность выбора сразу нескольких значений, поэтому, если у вас несколько регионов присутствия, то по ним можно посмотреть общую статистику.

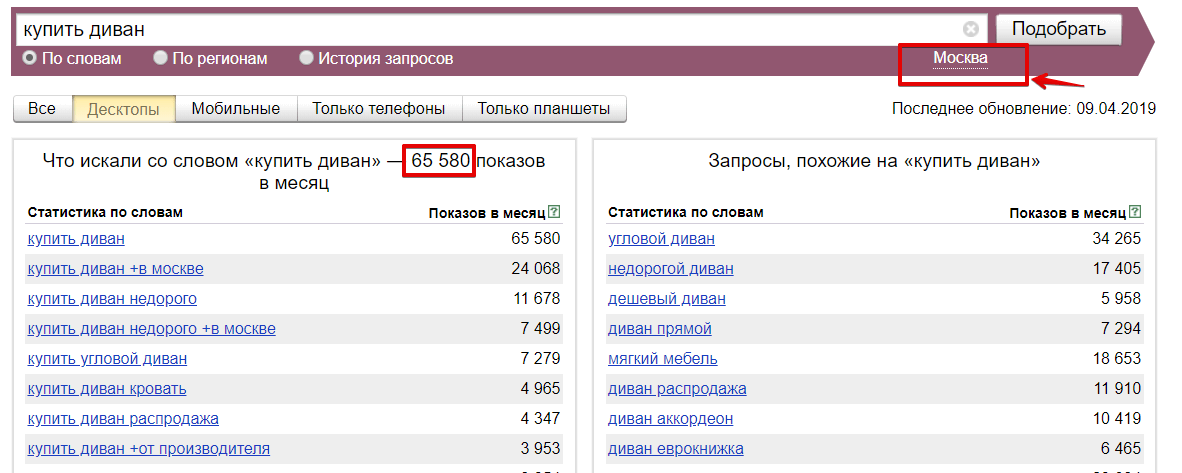
Кроме просмотра суммарной статистики можно еще оценивать спрос в разных регионах. Для этого необходимо переключиться на статистику «По регионам»:
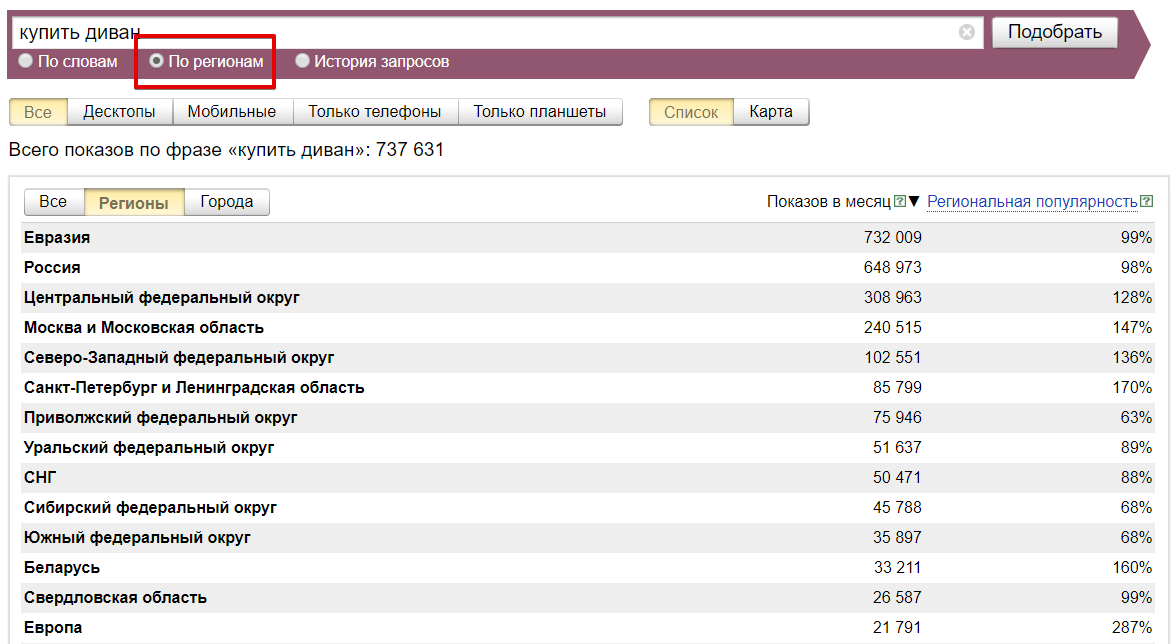
Вкладка по умолчанию открывается с представлением данных в режиме списка, где доступно переключение между статистикой по областям и городам. На странице можно увидеть два основных значения — «Показов в месяц» и «Региональная популярность».
С первым понятием мы уже разобрались — это суммарное количество запросов к Яндексу, в которых встречаются одновременно все слова из нашего запроса в Вордстат.
А «Региональная популярность» — это так называемый «affinity index» или индекс соответствия, он показывает отношение рейтинга по целевой аудитории к рейтингу базовой аудитории. Рассчитывается следующим образом: берется доля показов по этому слову в регионе и делится на долю вообще всех показов этого региона в поиске. Если кто-то что-то понял — вы молодцы, а теперь для простых смертных: в данном случае 100% — это базовый спрос, значение ниже 100% говорит о том, что спрос в этом регионе понижен, а если значение выше 100% то, соответственно, спрос повышен.
Если переключиться на представление данных в режиме карты, то можно увидеть эти данные в цвете на глобальной карте. Например, по фразе «купить диван» самый лютый спрос в Австралии (1808%).

Но не все так просто — важно помнить, что это статистика только по Яндексу, а Яндекс рулит только среди русскоязычной аудитории интернета и по большей части только в России, в других странах бОльшим спросом пользуется Google.
Довольно странно, что в Австралии кто-то пользуется Яндексом, задает запросы на русском языке и почему у них там ажиотаж с диванами =)
Скорее всего, эта статистика накручена различными ботами, которые используют австралийские IP для парсинга статистики Яндекса в какой-нибудь русскоязычный сервис.
К сожалению, в Вордстате учитываются все запросы к выдаче без фильтрации делал эти запросы бот или человек.
Оценка сезонности и история запросов
Напомню, что на вкладках «по словам» и «по регионам» данные представлены за последний месяц, но если мы переключимся на вкладку «История запросов», то сможем увидеть спрос на тот или иной запрос за последние 2 года.

Статистику на этой вкладке чаще всего используют для определения сезонности и оценки динамики спроса по запросу. В данном отчете нет возможности использовать операторы, поэтому статистика доступна только по широкому соответствию.
В верхней части данные представлены в виде графика, а в нижней части можно увидеть цифровые значения.
В этом представлении есть возможность посмотреть данные в абсолютном и относительном значениях.
Абсолютное — это фактическое число показов по запросу, а относительное — это число показов по запросу, нормированное на общее число запросов к Яндексу за это же время. Абсолютное значение можно использовать для оценки динамики спроса, пример мы видим, что за последние два года общее число запросов растет, т. е. все больше и больше людей интересуются в Яндексе покупкой диванов, кроме того видим, что в мае и июне спрос на диваны самый низкий, а в ноябре-декабре он достигает пикового значения.
Относительное значение показывает популярность того или иного запроса по отношению ко всем запросам в сети, если между графиками есть серьезные расхождения и резкие перепады, то это может говорить об искусственных накрутках запроса.
Технические ограничения Wordstat
В Yandex Wordstat есть ряд ограничений, о которых необходимо знать:
- сервис показывает статистику максимум по семисловным запросам, фразы с большим числом слов получить, увы, не получится,
- ограничение на число выводимых результатов. Оно составляет 50 результатов на одну страницу и 40 страниц, т.е. за раз можно собрать не более 2000 запросов. Обычно, чтобы обойти это ограничение достаточно включить в запрос уточняющие слова, собрать семантику, а затем отминусовать их из статистики.
Пример: нам нужно собрать всю семантику по фразе «купить диван», но мы не можем, потому что фраз больше 2000, и мы не видим их все.
Для начала нам нужно добавить к запросу дополнительное слово, пусть это будет слово «недорого»:
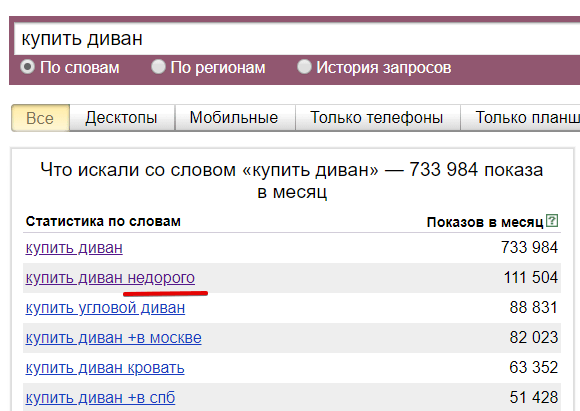
Мы увидели всю статистику по фразам, где есть слово недорого.

Посмотрели? Отлично, теперь уберем это слово из статистики:

Теперь мы не видим в общем списке фразы со словом недорого, то есть итоговый список фраз уменьшился. Теперь проверяем 40 страницу, если она заполнена, то нужно повторить итерацию еще раз, но уже с другим словом (предыдущее слово из минусовки не убираем). Таким образом можно отсеивать фразы до тех пор, пока их не останется меньше 2000 по основному запросу.
Капча в Wordstat
Для тех, кто не в курсе капча (от слова capture) — это специальное проверочное изображение с текстом, который нужно ввести в специальное поле. Яндекс показывает его, чтобы проверить кто пользуется сервисом — человек или робот, человек введет капу, а робот нет.
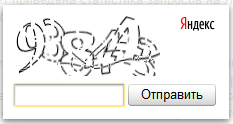
Как убрать капчу в Вордстате
Если вордстат постоянно требует капчу, то полностью избавиться от нее все равно не получится, но сократить ее появление — вполне, вот несколько советов:
- отключите ненужные плагины и расширения — какие-то из них могут блокировать получение файлов cookie, это могут быть плагины типа Adblock (в 90% случаев причина именно в этом);
- сам Яндекс советует также сократить число обращений к Вордстату. Если есть возможность разбить работу на некоторые отрезки времени, то сделайте это;
- в разделе помощи Яндекс рекомендует проверить компьютер на наличие вирусов, хоть и не говорит прямо, как наличие вирусов может быть связано с появлением капчи.
Также вы можете обойти капчу, если зайдете через Яндекс.Директ на вкладку «Прогноз бюджета» и далее по ссылке в блоке «Подберите ключевые фразы»:
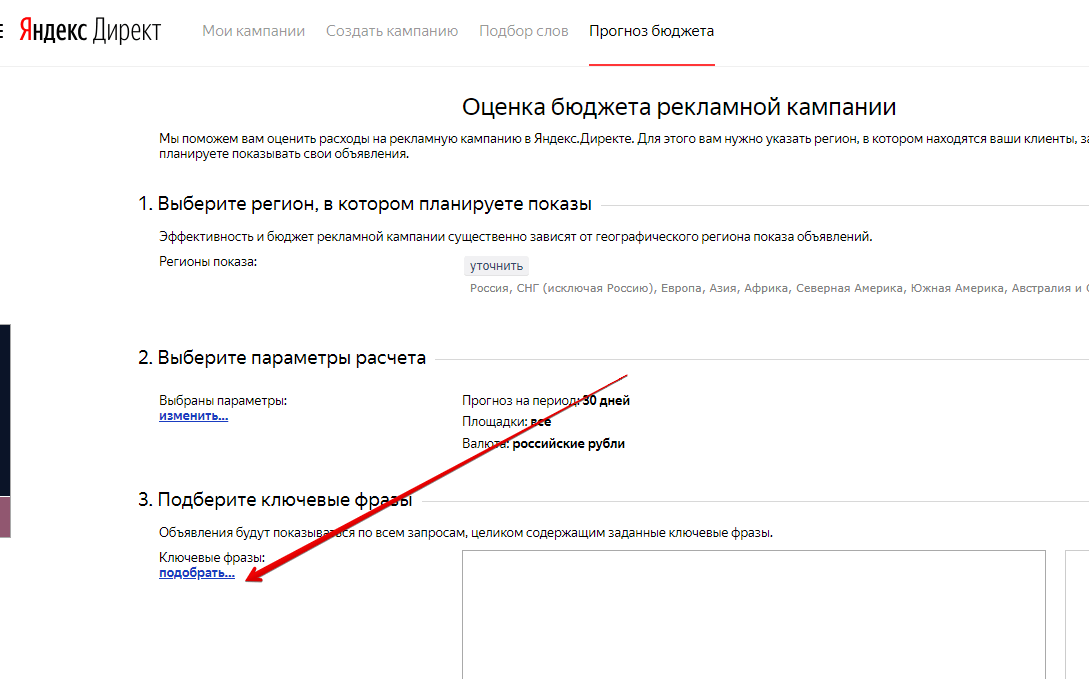
Это тот же Вордстат, только без капчи.
Как автоматически собрать данные из Yandex Wordstat
Из автоматических решений есть:
- программа Key Collector (платная),
- программа Словоеб (бесплатный аналог Key Collector с урезанным функционалом),
- сервис Букварикс (есть бесплатный и платные тарифы).
Key Collector ориентирован больше на профессионалов, эту программу напичкали полезными инструментами на все случаи жизни, кроме сбора запросов из Вордстата в нем полно других полезных функций от сбора позиций сайтов по запросам, до оценки рентабельности той или иной фразы для продвижения.
Словоеб подойдет новичкам, в нем нет некоторых полезных функций, а для профессионального использования он уже не подойдет.
Букварикс является готовой базой запросов из Wordstat, плюсы и минусы, как и в любой другой базе, — получить данные можно быстрее, чем при использовании программ, нет капчи при работе, сама база неполная, но для сбора основных поисковых запросов вполне сгодится.
Я и все мои коллеги пользуемся программой Key Collector, которая ежедневно облегчает нашу жизнь. Но так как пока я не планирую писать отдельный пост про КК, то прямо в этом посте порекомендую вам несколько обучающих видео от моего друга Игоря Бакалова (нажимайте на ссылки, откроется блок с видео):
Умный парсинг Яндекс Вордстат в KeyCollector
Cоставление основы для парсинга ключевых запросов в KeyCollector
Простая фильтрация навигационных запросов в KeyCollector
Как проверить геозависимость запросов в Google в KeyCollector
Фильтрация стоп слов в KeyCollector
Фильтрация стоп-слов: поиск по сниппетам в KeyCollector
Подбор сезонных запросов в KeyCollector
Правильный сбор сезонности Яндекс.Вордстат в программе KeyCollector
Анализ неявных дублей в KeyCollector
В полуавтоматическом режиме можно собрать данные с помощью расширений для браузера, например:
- Yandex Wordstat Helper,
- Yandex Wordstat Assistant.
Эти плагины изменяют интерфейс страницы сервиса и добавляют дополнительный функционал, облегчающий сбор данных. Например, появляется возможность скопировать в буфер сразу несколько интересующих запросов, а не копировать их поштучно.
Напоминаю про пост про плагины и расширения для работы с Yandex Wordstat: Assistant, Helper, Keywords Add и WordStater.
На этом можно и закончить, все что можно мы разобрали, надеюсь, каждый из вас нашел для себя что-то новое и полезное!
Спасибо за внимание, друзья.
До связи.

Спасибо!
Давно дружите с Бакаловым?
Ну как дружим. Виртуально скорее. Но лично знакомы. Познакомились как-то на SeoConf 2016 в Казани. Набухались в драбадан в клубе Legend и синие пытались найти дорогу до отеля IT-Park ночью. Нашли :) Было весело!
Александр, спасибо! Неожиданно обнаружила для себя несколько полезных функций, о которых раньше не знала, хотя с Вордстатом работаю давно и плотно.
Я знаю. Потому и написали данный пост. Мало кто знает обо всех возможностях, не смотря на то, что их не так-то и много!
Спасибо! Очень интересно тересная и информативная статья) много фишек и полезностей подчерпнула
Вопрос!
Есть запросы "туры в самару из москвы" и "туры в москву из самары". Вордстат выдает одинаковые данные.
При этом мы понимаем, что запросы совершенно различные и эти различия для коммерческой организации очень критичны. Поиск Яндекса тоже это понимает и выдача совершенно разная.
Как определить реальную частоту и популярность каждого запроса?
А как на счет внимательно прочитать пост и посмотреть, что значит оператор квадратные скобки []?
Читаю и внимательно: "Позволяет задать нужный порядок слов в запросе. Оператор не ограничивает запрос указанными словами и не фиксирует словоформу."
А мне нужно не фиксировать порядок слов, а именно зафиксировать словоформу.
И по запросам [туры в самару из москвы] и [туры в москву из самары] вордстат выдает ахинею: порядок слов и словоформы разные, а частотность одинаковая. Это нерелевантные данные.
Так что как насчет вникнуть в вопрос и предложить решение данной ситуации, если оно, конечно, существует для вордстата. Не настаиваю, но раз подняли такую тему в посте, было бы интересно копнуть чуть глубже.
Почему одинаковая частотность-то?
Разная, вот, пожалуйста:
Что искали со словом «[туры в самару из москвы]» — 17 показов в месяц
https://wordstat.yandex.ru/#!/?words=%5B%D1%82%D1%83%D1%80%D1%8B%20%D0%B2%20%D1%81%D0%B0%D0%BC%D0%B0%D1%80%D1%83%20%D0%B8%D0%B7%20%D0%BC%D0%BE%D1%81%D0%BA%D0%B2%D1%8B%5D
Скрин http://prntscr.com/nlwh6l
Что искали со словом «[туры в москву из самары]» — 118 показов в месяц
https://wordstat.yandex.ru/#!/?words=%5B%D1%82%D1%83%D1%80%D1%8B%20%D0%B2%20%D0%BC%D0%BE%D1%81%D0%BA%D0%B2%D1%83%20%D0%B8%D0%B7%20%D1%81%D0%B0%D0%BC%D0%B0%D1%80%D1%8B%5D
Скрин http://prntscr.com/nlwhui
Спасибо! Я смотрел не на эту строчку, а на табличку ниже.
Буду пользоваться.
Круто конечно, Яндекс рулит. Для новичков самое оно, азы закрепить и понять. А потом нужно идти в гугл и делать то же самое. Затем вычислять среднеарифметическое по частотникам. Нелегко скажу вам и времени уйма уходит. Но для поддержания навыков использовать сервисы можно. А можно использовать кластеризатор. Есть и бесплатные аналоги.
Можно и не делать для Гугла, не думаю, что разнообразие ключевиков, частотность которых хотя бы не менее 5 в мес. сильно разнится между Яндексом и Гуглом. По крайней мере, в России точно.