 Привет, друзья. Сегодня я хочу поделиться еще одной наработкой из большого списка регламентов и инструкций нашей студии «АлаичЪ и Ко». Среди моих коллег есть фанат работы с Гугл Таблицами – это Алексей Степанов, совместно с которым мы готовили для вас прошлую публикацию про написание seo-текстов и подготовки ТЗ для копирайтеров. Уверен, что и среди читателей блога много тех, кто использует Гугл Таблицы вместо Экселя. Сегодняшняя публикация для вас, ее Алексей подготовил без моей помощи, поэтому без долгих вступлений я сразу передаю слово ему.
Привет, друзья. Сегодня я хочу поделиться еще одной наработкой из большого списка регламентов и инструкций нашей студии «АлаичЪ и Ко». Среди моих коллег есть фанат работы с Гугл Таблицами – это Алексей Степанов, совместно с которым мы готовили для вас прошлую публикацию про написание seo-текстов и подготовки ТЗ для копирайтеров. Уверен, что и среди читателей блога много тех, кто использует Гугл Таблицы вместо Экселя. Сегодняшняя публикация для вас, ее Алексей подготовил без моей помощи, поэтому без долгих вступлений я сразу передаю слово ему.
В этой статье мы рассмотрим на примерах, как парсить содержимое сайтов с помощью Google Таблиц. В частности, рассмотрим функции importHTML и importXML. Первую функцию очень удобно использовать если данные находятся в какой-то таблице или списке, а вторая функция является универсальной и практически не имеет ограничений.
Функция importHTML
С помощью функции importHTML можно настроить импорт данных из таблицы или списка на странице сайта.
Синтаксис
=IMPORTHTML(ссылка; запрос; индекс)
- ссылка — ссылка на веб-страницу, включая протокол (http:// или https://),
- запрос — значения «table» или «list», смотря, что нужно парсить (таблицу или список),
- индекс – порядковый номер списка или таблицы (отсчет начинается с 1).
Пример:
IMPORTHTML("http://ru.wikipedia.org/wiki/Население_Индии"; "table"; 4)
Переменные можно разместить в ячейках, тогда формула изменится так:
IMPORTHTML(A2; B2; C2)
Примеры использования importHTML
Выгрузка любых табличных данных
Однажды мне понадобилось собрать список минус-слов по городам России в существительном падеже. Первые пару нагугленных файлов с минус-словами были неполными, а в других меня не устроила словоформа. Поэтому я просто решил спарсить страницу Википедии, что заняло около двух минут, включая время на открытие Гугл Таблицы, поиск нужной страницы Википедии и настройку формулы. С этого примера я и начну.
Задача: выгрузить список всех городов России со страницы https://ru.wikipedia.org/wiki/Список_городов_России

Чтобы выгрузить данные из этой таблицы нам нужно указать в формуле ее порядковый номер в коде страницы. Чтобы этот номер узнать, нужно открыть код сайта (в нормальных браузерах это сочетание Ctrl+U, либо клавиша F12, открывающая панель разработчика). А дальше поиском по коду определить порядковый номер:

В данном случае целевая таблица является первой в коде.
Составляем формулу:
=IMPORTHTML("https://ru.wikipedia.org/wiki/Список_городов_России";"table";1)
Результат:

Выгрузка данных из списка
Как-то я работал с интернет-магазином у которого была обширная структура и очень неудобное меню. Надо было бегло оценить текущую структуру сайта, чтобы понять ассортимент и возможные очевидные проблемы, типа дублирования пунктов меню. Меню было реализовано в виде списка, чем я и воспользовался. Меньше чем через минуту полная иерархия сайта отображалась у меня в Гугл Табличке.
Задача: выгрузить все пункты меню, оформленного тегами <ul>...</ul>.

Как и в первом примере для формулы понадобится определить порядковый номер списка в коде сайта. В данном случае — четвертый.
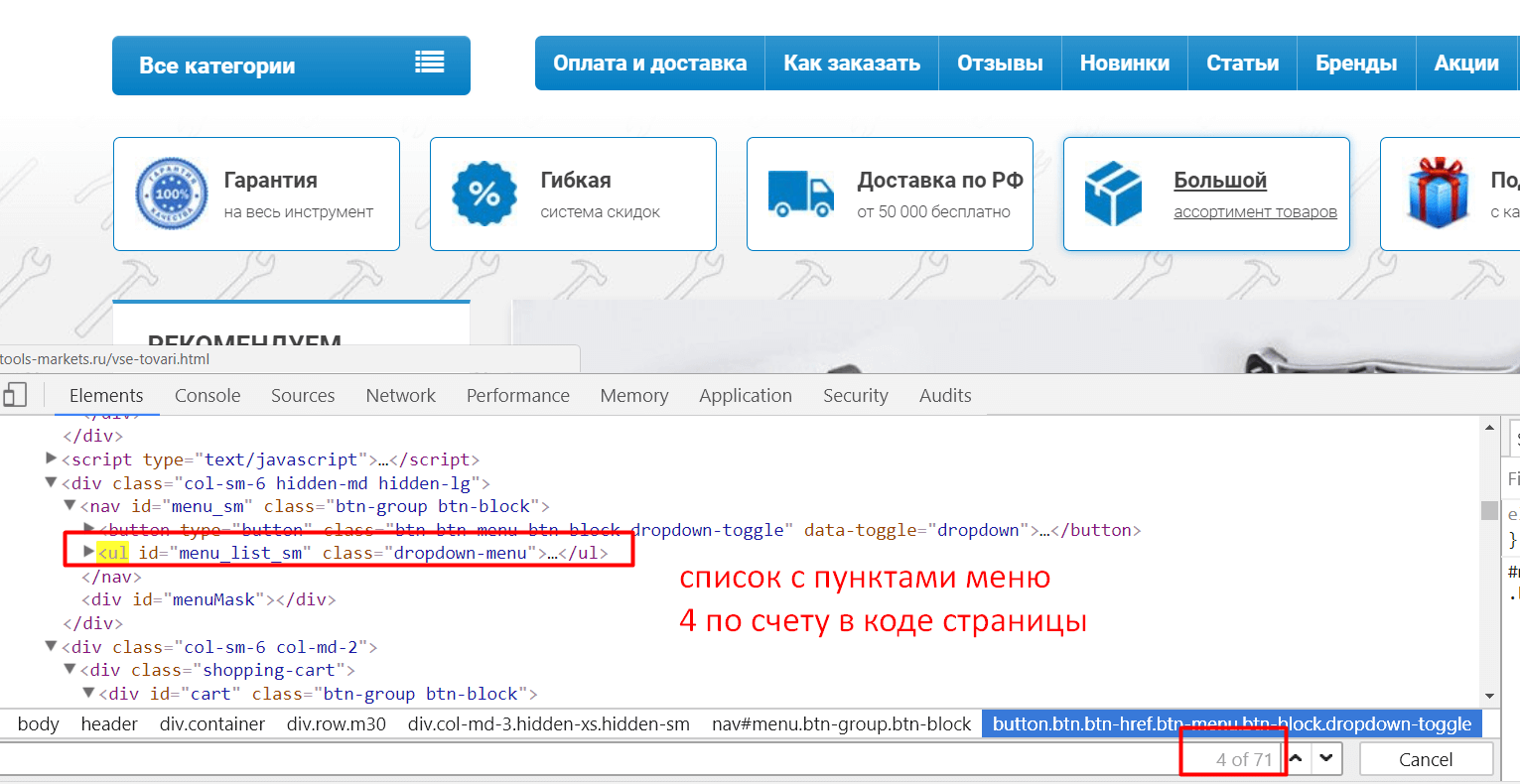
Составляем формулу:
=IMPORTHTML("https://tools-markets.ru/";"list";3)
Результат:

Списки и таблицы — это хорошо, но чаще всего необходимо выдернуть с сайта информацию, оформленную другими тегами. Например, тексты, цены, заголовки и так дальше. Эти данные можно спарсить, используя формулу importXML, разберем ее подробнее.
Функция importXML
С помощью функции importXML можно настроить импорт данных из источников в формате XML, HTML, CSV, TSV, а также RSS и ATOM XML.
По сравнению с importHTML у данной функции гораздо более широкое применение. Она позволяет собирать практически любую информацию со страницы/документа, от частичных фрагментов до полного ее содержания. Ниже будут описаны примеры парсинга HTML-страниц сайта. Парсинг по файлам рассматривать не стану, т.к. такая задача возникает редко и большинство из вас с этим не столкнется никогда. Но если что, принцип работы везде одинаковый, главное понять суть.
Синтаксис
IMPORTXML(ссылка; "//XPath запрос")
- ссылка – адрес веб-страницы с указанием протокола (http:// или https://). Значение этого параметра должно быть заключено в кавычки или представлять собой ссылку на ячейку, содержащую URL страницы.
- //XPath запрос – то, что будем импортировать. Ниже мы разберем основные примеры запросов (а тут подробнее про XPath).
Пример:
IMPORTXML("https://en.wikipedia.org/wiki/Moon_landing"; "//a/@href")
Значения переменных можно хранить в ячейках, тогда формула будет такой:
IMPORTXML(A2; B2)
Примеры использования importХML
Пример 1. Импорт мета-тегов и заголовков со страниц
Самая простая и распространенная ситуация, которая может быть — узнать мета-теги или заголовки продвигаемых страниц. Для этих целей лучше подходит парсинг сайта специализированным софтом типа Comparser'a. Но бывают и исключения, например, если сайт очень большой и это сделать затруднительно, либо у вас нет под рукой программы. Или если вы собираетесь дальше использовать полученные данные в таблицах для мониторинга изменений мета-тегов и сверки целевых и фактических мета-тегов на страницах.
Формулы простые.
Получаем title страницы:
=importxml(A3;"//title")
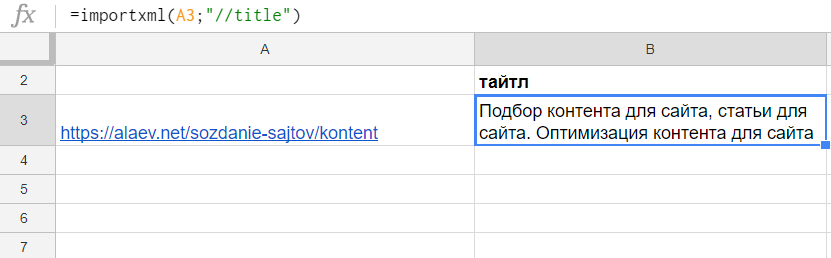
Получаем заголовки h1:
=importxml(A3;"//h1")

Получаем description:
=importxml(A3;"//meta[@name='description']/@content")
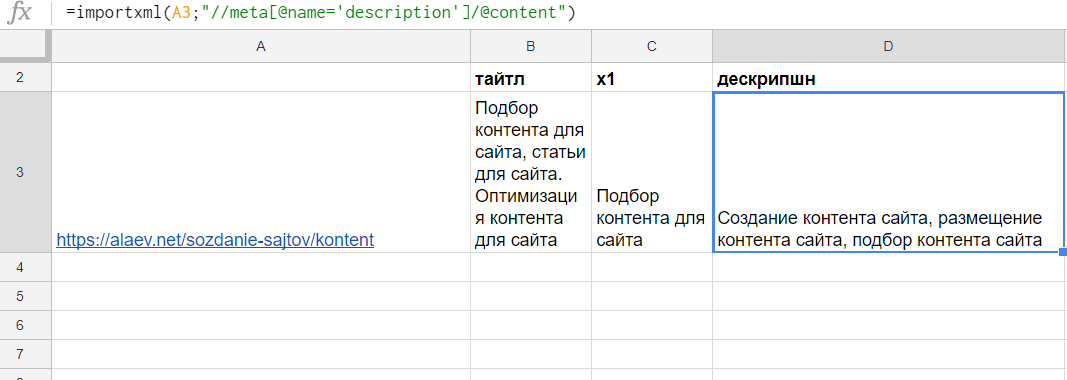
Последняя формула получилась сложнее т.к. нас интересует значение не самого тега, а его атрибута:
- ищем тег meta //meta
- у которого есть атрибут name='description' [@name='description']
- и парсим содержимое второго атрибута content /@content
Пример 2. Определяем наличие текста на странице и его длину в символах
Этот пример мне помог при работе с проектом, тексты для которого писал и размещал сам клиент, и ему было чрезвычайно лень сообщать мне о ходе процесса. Небольшой лайфхак с Гугл таблицами позволил мне мониторить динамику его работы, а ему с чистой совестью и дальше продолжать лениться и не сообщать мне ничего.
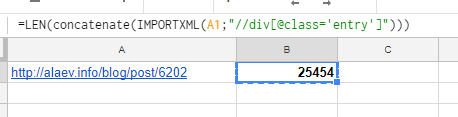
Рассмотрим ситуацию на примере нашего блога http://alaev.info, а конкретно на странице https://alaev.info/blog/post/6202. Если заглянуть в код, то мы увидим, что контент страницы расположен в теге <div> с классом entry.
Формула:
=LEN(concatenate(IMPORTXML(A1;"//div[@class='entry']")))
В ячейке А1 у нас ссылка на статью, в запросе XPath мы получаем содержимое тега div, у которого есть класс entry, то есть парсим весь текст страницы: =IMPORTXML(A1;"//div[@class='entry']")
Функция CONCATENATE (в русском варианте СЦЕПИТЬ) нужна, чтобы объединить все абзацы в один кусок контента. Без нее мы посчитаем только объем первого абзаца.
Функция LEN (в русском варианте ДЛСТР) считает количество символов.
Пример 3. Выгружаем актуальные цены
Однажды потребовалось не только заниматься оптимизацией сайта, но и следить за ценами конкурентов по схожим товарным позициям. Использование специализированного софта и сервисов я практически сразу отмел, т.к. специальные сервисы по мониторингу не укладывались в бюджет, а вручную сканировать сайты конкурентов несколько раз в неделю не комильфо.
К счастью, вариант с Гугл доками оказался подходящим и уже к концу дня я все настроил так, что данные подтягивались автоматически. От меня ничего не требовалось, кроме как отправить ссылку на документ клиенту и спокойно заниматься своими делами.
Я решил рассмотреть похожую ситуацию на случайном сайте. Итак, допустим, мы хотим мониторить цены на автомобили и, скажем, выгружать актуальные цены с сайта http://centrmotors.lada.ru/. Вот пример товарной карточки http://centrmotors.lada.ru/ds/cars/granta/sedan/.
Чтобы настроить формулу снова идем в код сайта и смотрим в каких тегах располагается цена. Примеры должны быть простыми, поэтому я буду выгружать только минимальную цену.

На данном сайте нам надо парсить содержимое тега <span> с id textspan7.
Формула:
=importxml(A2;"//span[@id='textspan7']")
В таблице ссылки на товары укажем в столбце А, а формулу вставим в столбец В.
Результат:
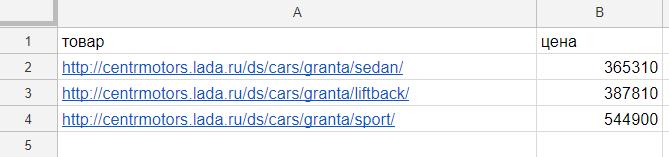
Поясню:
- A2 — номер ячейки из которой берется адрес страницы,
- //span[@id='textspan7'] — блок из которого будем выводить информацию.
- Если бы у нас вместо span был div, а вместо id был бы class, то вторая часть формулы была такой:
//div[@class='textspan7']
Автоматизируем дальше.
Приведенное выше решение не идеальное, ведь нам надо предварительно собрать адреса товарных страниц, а это довольно муторно. Если на сайт добавят новые модели авто, то информация по ним не будет подгружаться в таблицу т.к. адреса страниц будут отсутствовать в документе.
Подключив логику и другие формулы, можно хакнуть рутину. Ссылки на все модели присутствуют в главном меню. А если есть ссылки, то скорее всего их тоже можно спарсить.

И действительно, заглянув в код, мы увидим, что ссылки на товарные страницы располагаются в теге <p> c классом CMtext4:

Формула:
=IMPORTXML(A8;"//p[@class='CMtext4']/a/@href")
- A8 – в этой ячейке ссылка на сайт,
- p[@class='CMtext4'] – тут мы ищем содержимое тега <p> с классом CMtext4,
- /a/@href – а в этой части формулы мы уточняем, что из содержимого <p> хотим достать содержимое вложенного тега <a>, а если еще точнее, то ту часть, которая прописана в href="".
После применения формулы в документе получится такой список:
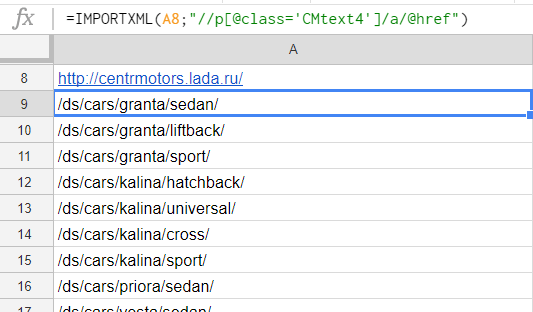
Мы получили ссылки на все товары, которые нас интересуют. Осталось настроить парсинг цен по этим адресам. Но ссылки на страницы относительные, а нам обязательно нужны абсолютные ссылки, включающие имя домена. Чтобы подставить в ссылку домен используем функцию CONCATENATE.
Формула:
=IMPORTXML(concatenate("http://centermotors.lada.ru";A9);"//span[@id='textspan7']")
Либо при условии, что у нас в ячейке А8 находится адрес домена:
=IMPORTXML(concatenate(A$8;A9);"//span[@id='textspan7']")
Размещаем мы ее справа от первой ссылки на товарную страницу и протягиваем вниз для всех ссылок или до конца листа на случай, если в будущем будет больше товаров.

Результат:
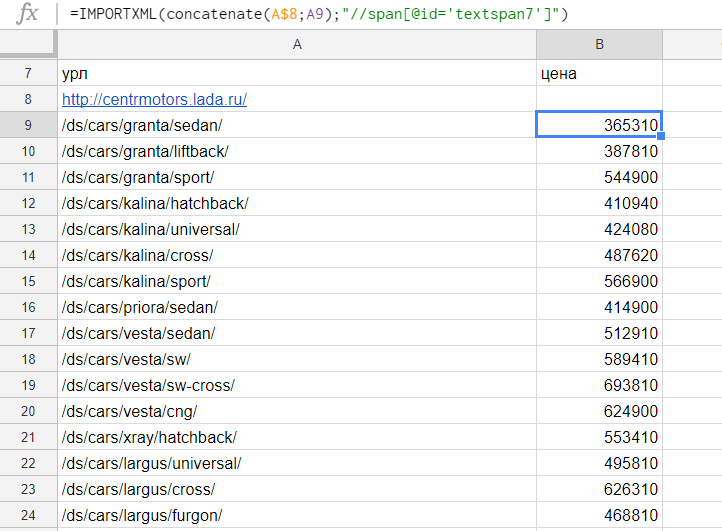
Поясню, если кто-то еще не разобрался:
- A$8 — ячейка, в которой указан домен сайта. Знаком $ фиксируем строку, чтобы это значение не изменилось, когда мы начнем протягивать формулу вниз.
- A9 — это первый URL товарной страницы, при перетаскивании формулы значение автоматически меняется, т.е. в 10 строке у нас вместо A9 будет A10, в 11 строке A11 и т.д.
Теперь если на сайте будут добавлены или удалены товары, то в нашем файле ссылки на них автоматически обновятся, и мы будем всегда видеть только актуальную информацию.
Пример универсальный и имеет применение не только в рабочих целях. Например, можно мониторить цены на товары в ожидании скидок. А если еще немного потрудиться, то и настроить оповещение на почту при изменении цены (или любого другого значения) ниже/выше определенного значения.
Пример 4. Узнать количество товаров в категориях
Очень полезный прием для тех, кто хоть раз продвигал интернет-магазины без товаров. Нет, это не шутка! Мне доводилось пару раз, как бы это смешно ни звучало.
Например, движок сайта не отображает те товары, которых нет на складе (или сам клиент может удалять их вручную). В этом случае есть риск возникновения ситуации, когда на складе вообще не окажется определенного типа товаров и категории будут висеть пустые, в лучшем случае на странице будет текстовое описание.
Но с помощью парсинга легко узнать на каких страницах есть беда с ассортиментом.
Для примера возьмем сайт http://bz2.ru. Категории с товарами выглядят вот так http://bz2.ru/katalog/generatory-dizelnye/dizelnye-generatory-100-kvt/.
Чтобы посчитать количество товаров идем в код сайта и смотрим какими тегами оформлены товары.
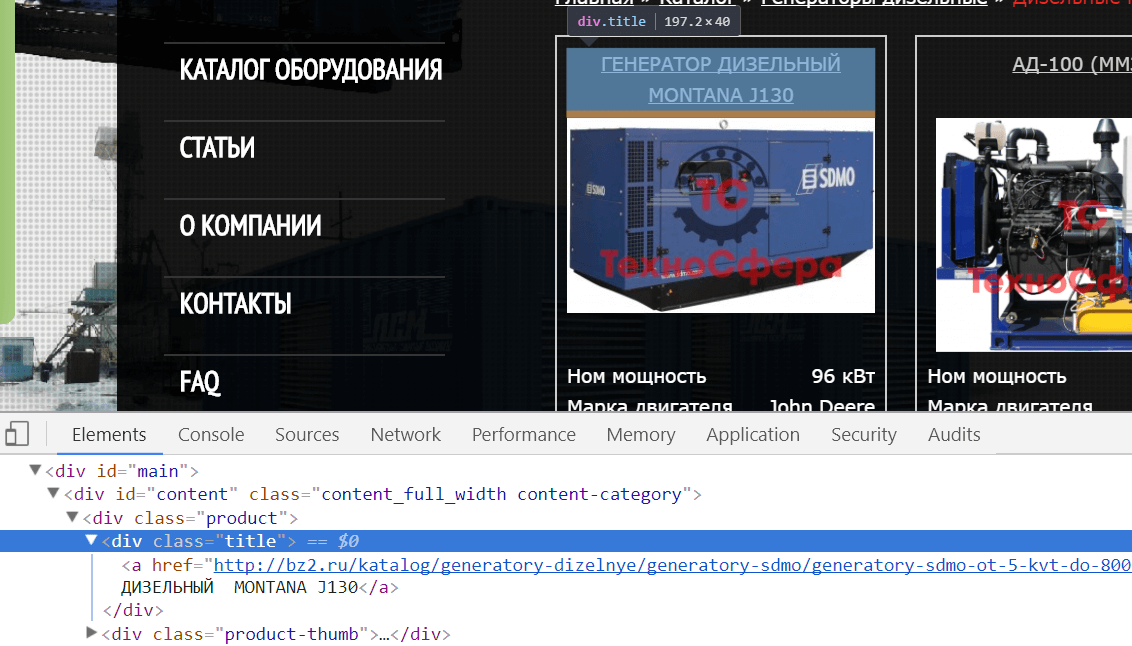
Товар оформлен в теге <div> с классом product, заголовок товара оформлен в теге <div> с классом title. Я решил посчитать заголовки:
Формула:
=COUNTA(IMPORTXML(A3;"//div[@class='title']"))
Результат:
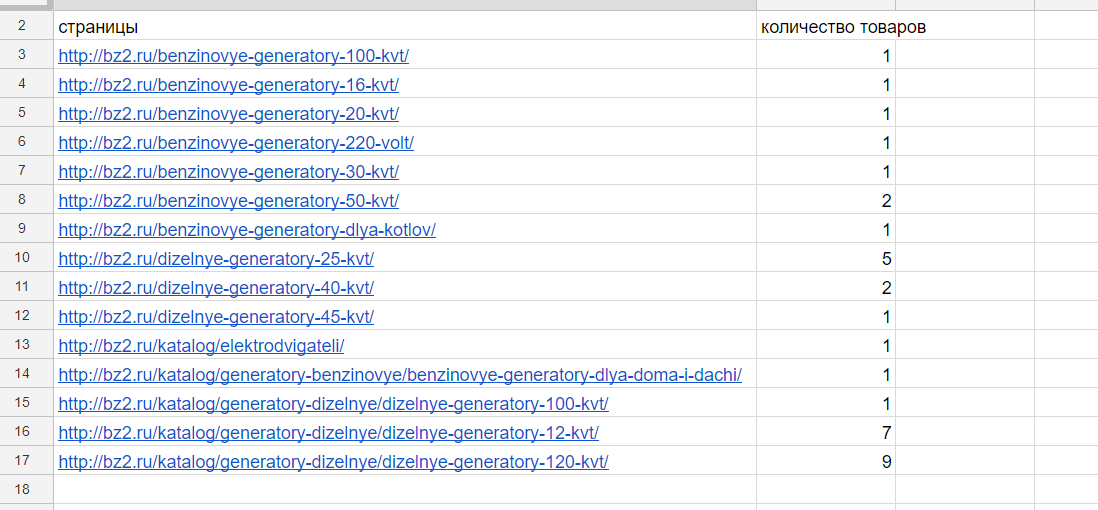
COUNTA нужна, чтобы подсчитать число значений, если бы мы не использовали эту функцию, то результат был бы таким:
Как и в примере выше, можно автоматизировать процесс, чтобы ссылки на все категории парсились автоматически и их не приходилось добавлять вручную.
Пример 5. Парсим код ответа сервера
Я очень редко встречаю сайты, где что-то постоянно отваливается, но все же бывает. В случае необходимости можно быстро проверить все продвигаемые страницы на доступность и корректный ответ сервера.
Обычно я такие вещи мониторю с помощью скриптов без использования формул, но с помощью рассматриваемой функции это можно реализовать. Данный способ, пожалуй, единственное исключение из общего списка примеров, потому что я к нему не прибегал ни разу, но уверен, что кому-то из вас он пригодится.
В сети много сервисов, которые проверяют страницы на код ответа сервера. Суть идеи в том, чтобы парсить данные с такого сервиса. Для примера я решил взять самый популярный — http://www.bertal.ru/ — если мы проверим в нем страницу, то он отобразит результат по URL вида https://bertal.ru/index.php?a4789763/alaev.info/blog/post/6202#h.
Я не знаю, что означают символы a4789763, но на результат они не влияют. Смотрим:

Формула:
=importxml(concatenate(A$4;A6);"//div[@id='otv']/b")
Результат:
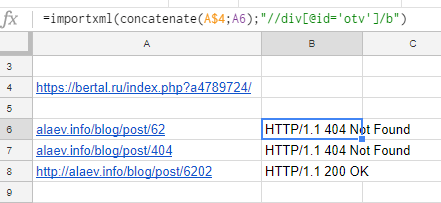
- A$4 — адрес ячейки с неизменяемой частью URL,
- A6 — ячейка с адресом страницы, код ответа, которой хотим проверить.
Функцией CONCATENATE склеиваем наши куски в один URL с которого и парсим данные.
Пример 6. Узнаем количество страниц в индексе ПС
Если мы введем в поисковик запрос типа [site:http://alaev.info], то узнаем сколько всего страниц данного сайта находится в выдаче.

Результаты будут выведены на странице типа https://yandex.ru/search/?text=site%3Ahttp%3A%2F%2Falaev.info&lr=213, где после [https://yandex.ru/search/?text=site%3A] следует адрес сайта и необязательный параметр региона поиска [&lr=213].
Все, что нам нужно — это сформировать URL, по которому поисковик отдаст нам ответ, и определить из каких тегов парсить эту инфу.
В данном случае данные лежат в теге <div> с классом serp-adv__found.
Если мы поместим ссылку на сайт в ячейку A15, то формула будет такая:
=importxml(CONCATENATE("<a href="https://yandex.ru/search/?text=site%3A%22;A15">https://yandex.ru/search/?text=site%3A";</a>A15);"//div[@class='serp-adv__found']")
Результат:

В таком виде результат не особо ценен, т.к. желательно не только узнать количество страниц, но и провести какие-то дальнейшие вычисления или сравнения. Для этого модернизируем формулу и приведем текстовое значение в числовое.
Для этих целей будем использовать функцию SUBSTITUTE (в русском варианте ПОДСТАВИТЬ). Суть идеи в том, чтобы убрать слово [Нашлось: ] и заменить надпись [тыс. результатов] на [000], чтобы в итоге надпись выглядела как просто число 2000.
Но есть нюанс. Окончание меняется в зависимости от результата, например, может выглядеть как [Нашёлся 1 результат], поэтому такие вариации тоже надо будет заменить.
Не буду вас утомлять, поэтому ближе к делу: сначала заменим надпись [Нашлось: ] на пустоту вот так:
=SUBSTITUTE(ссылка;"Нашлось ";"")
Дальше заменим [тыс. результатов] на [000] для этого добавим еще одну аналогичную функцию, и формула будет выглядеть так:
=SUBSTITUTE(SUBSTITUTE(ссылка;"Нашлось ";"");"тыс.";"000")
Проделаем тоже самое для остальных вариантов и вместо слова [ссылка] пропишем функцию импорта. Конечная формула будет следующей:
=SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(importxml(CONCATENATE("https://yandex.ru/search/?text=site%3A";A10);"//div[@class='serp-adv__found']");"Нашлось ";"");" результатов";"");" результата";"");" ";"");"Нашлась";"");"результат";"");"Нашёлся";"");"тыс.";"000")
Немного пугающе, правда? Возможно, есть более элегантные решения, но так как данный вариант универсальный и полностью рабочий, то я остановился на нем. Если вы найдете более красивое решение, то поделитесь в комментариях, мне будет интересно увидеть другие возможные построения формулы.
Ограничения
Минусом использования данных функций является то, что большие объемы данных обработать не получится. Существуют ограничение на число исходящих запросов, и если вам нужно, например, послать 1000 запросов, то вы столкнетесь с ситуацией, когда в большинстве ячеек у вас будет находиться надпись «Loading». Точных цифр Google не приводит, но по личному наблюдению — за один раз можно отправить около 100 запросов, после чего происходит таймаут примерно на 1 час до отправки следующей партии запросов. Поэтому вам подойдет этот функционал только в том случае, если не планируется обработка больших объемов данных.
На этом я закончу с примерами, на которых, конечно, возможности рассматриваемых функций не кончаются, однако, смысл статьи в том, чтобы познакомить вас с базовыми приемами и общими принципами работы.
Для меня возможности данных функций незаменимы для выполнения простых задач. Надеюсь, что и для вас эта информация оказалась полезной и позволит победить рутину в повседневных задачах.
Если у вас есть на заметке интересные примеры, обязательно делитесь в комментариях!
Спасибо за внимание. И до связи!

Парсинг тайтлов и дескриптион полезно.
Лаборатория «АлаичЪ и Ко» еще не придумала как выгружать базу миралинкс и ggl а то прошлый способ прикрыли
База GGL тут лежит https://checktrust.ru/cabinet/market-control-center.html или при создании нового проекта есть проверка всей базы https://checktrust.ru/cabinet/projects/create.html
А Миралинкса нет и не планируется.
А почему Миралинкс и не планируете? Тоже интересует...
Потому что изначально не сложилась дружба с ними, а после общения так и вообще. Я же не раз подкатывал к ним с различными предложениями, но все время сталкивался с безразличием или даже негативом. В то время как со всеми остальными биржами у нас дружба, любовь и взаимопонимание.
Добрый день!Попробывал ввести скрипт из примера выдаёт N/A. В чем может быть дело?
Кажется это то из чего можно запилить полезную фичу для контекста)
Хорошая тема, google docs ускоряют работу в n% если подойти к ним с умом.
А получилось разобраться по срокам обновления информации тегом importxml?
И упомянуть бы в статье, что ограничения все же есть — но парсить большое кол-во урлов не выйдет, повиснут на loading
Как раз Алексей попросил меня добавить про ограничения. Добавил, в конце поста появился соответствующий подзаголовок.
"Поэтому вам подойдет этот функционал только в том случае, если не планируется обработка больших объемов данных."
В свое время отказался от Google Docs именно по этой причине. Собирает быстро, но данных так собрать можно немного (((
Также в свое время была отдельная таблица, которая проверяла не поменялись ли значения в title, description. Вот тут есть шаблон https://www.ranktank.org/title-tag-and-meta-description-auto-verify-tool/.
Сейчас изменения в оптимизации удобнее отслеживать в Радаре (в Топвизоре) или даже проще написать свой скрипт, чтобы работал так как удобно.
По ссылке у ребят кстати полно других ништяков.
Полезный ресурс, спасибо
Такой вопрос: а так можно парсить только исходный код страницы? А если догружается в процессе — его как-то можно собрать или это уже сложнее ГуглДоков?
Конкретно вышеописанными функциями спарсить код нельзя, но это можно сделать с помощью другой функции IMPORTDATA, формула предельно простая и выглядит вот так =IMPORTDATA ("https://alaev.info/blog/post/6256")
Если будет потребность, то наверное как-нибудь могу сделать небольшой обзор и ее возможностей тоже.
Что касается динамических данных: при отправке запроса бот может получить только те данные, которые доступны на момент формирования страницы. Все, что подгружается в процессе бот просто не увидит, так что ответ на этот вопрос — нет, такие данные собрать не получится.
Еще один тупой вопрос: а если код не размечен как теги (в данном примере представляет собой JSON-ответ) типа такого:
{"count":0,"ages":[]},"stars":{"from":1,"to":5},"options":{"flex_dates":false,"from_price":0}}}
— можно как-то средствами XPath вытянуть произвольные данные? Или он умеет работать только с тем, что заключено в <...> ?
Пришлите, пожалуйста, ссылку на страницу-пример и какие данные хотите парсить — посмотрю можно ли что-то сделать.
Хороший способ. Я пользуюсь библиотекой Jsoup, написанной специально для парсинга html.
Никаких ограничений, если, конечно, сам исследуемый сайт не запрещает парсинг.
Вот Вы привели пример с парсингом цен на авто. А можно как-то отслеживать изменения цены? Чтобы если цена поменялась, записалась бы дата изменения и новое значение в новом столбце. Чтобы можно было видеть в какую дату и на какую цену цены менялись? Чтобы видеть историю изменения цен на товар, например за год. Заранее благодарен за ответ
Такая реализация без использования скриптов уже невозможна. Это выходит за рамки простых формул.
День добрый!
Задача забрать весь plain-text со страницы не прописывая class =ЕСЛИОШИБКА(ДЛСТР(СЦЕПИТЬ(IMPORTXML (A2;»//div[@class=’typo’]»)));»НЕ ВЕРНЫЙ CLASS»)
Значем что текст стоит в основном в часть данных структурируются в таблицу ... какую тут формулу можно сконструировать? или как допились эту =ДЛСТР(СЦЕПИТЬ(IMPORTXML (A5;»//p))) что бы в данные вытягивало колличество слов из
Спасибо.
"Задача забрать весь plain-text со страницы не прописывая class" — Честно сказать, не понял что вы хотите
"Значем что текст стоит в основном в часть данных структурируются в таблицу" — тоже не совсем понятно.
Предоставьте пример страницы и скажете что нужно достать — с удовольствием подскажу.
Прямой формулы для подсчета слов нету, придется исхитряться. Суть: если текст без ошибок, то по идее все слова должны быть разделены пробелами, при этом слов больше на 1. То есть можно узнать количество слов, если подсчитать число пробелов и прибавить 1, у меня получилась вот такая формула
=LEN (concatenate (IMPORTXML (A2;"//div[@class='entry']"))) -LEN (SUBSTITUTE (concatenate (IMPORTXML (A2;"//div[@class='entry']"));" ";""))+1
скриншот http://prntscr.com/ik4vtg
на всякий случай объясню формулу: до знака "-" у нас ровным счетом ничего не поменялось из примера в статье — мы посчитали знаки. После знака "-" та же самая формула, только дополнительно мы заменяем пробелы на пустоту т.е. вычитаем из общей длины текста длину текста без пробелов — получаем число пробелов и в конце прибавляем 1 (последнее слово в тексте)
День добрый!
Смысл забрать весь текст со станицы не использовав class или XPath
Страница пример http://www.dochkisinochki.ru/icatalog/categories/zheleznaya-doroga/type_games-parovoziki/
Текст http://prntscr.com/ilxlxt
Хочу настроить документ на быстрый анализ конкурентов по нужным запросам. Вот осталось реализовать как быстро смотреть seo текст...
Добрый день, а что за странное условие такое "не использовав class или XPath"?
Функцией ImportHTML тот текст не достать т.к. он лежит не в таблице и не в списке, а синтаксис ImportXML позволяет функции работать ТОЛЬКО с использованием XPath, по другому никак.
Поэтому я вас разочарую, но с таким требованием вам придется искать какие-то другие способы парсинга.
Но на всякий случай — вот формула, которая выгружает текст с указанной страницы в ячейку гуглтаблицы
=concatenate (IMPORTXML ("http://www.dochkisinochki.ru/icatalog/categories/zheleznaya-doroga/type_games-parovoziki/";"//div[@class='b-conclusions']"))
Круто, дальше можно на базе такой таблички собрать сайт на моем старом MFA движке
http://zloyblog.ru/mfa/
Что вы ерундой занимаетесь, для этого давно уже есть соф content downloader. Это настоящий монстр, который освоит любой без языков программирования.
Ну пользуйтесь на здоровье.
Здравствуйте. Очень понравилась информация, спасибо! Пробую спарсить карту сайта xml. Что-то не выходит. Вроде, всё логично делаю. И Гугл в справке пишет, что xml формат тоже должен парситься. Если не сложно, не могли бы глянуть, что не так в такой строчке?
=importxml ("https://legion-expert.ru/index.php?option=com_jmap&view=sitemap&format=xml";"//loc")
В качестве результата пишет: Ошибка. Нет данных для импорта...
Очень интересный вопрос, проблема заключается в специфике формата xml, подробнее об этом можно почитать тут http://infoxml.ru/page/1-rasshirennie-imena.shtml
Для решения вашего вопроса нужно дополнительно использовать функцию xPath local-name, подробнее о ней можно почитать тут https://msdn.microsoft.com/ru-ru/library/ms256070 (v=vs.120).aspx
Подозреваю, что для 99% пользователей — это будет лишней информацией, поэтому к сути: итоговая формула будет такой
=importxml ("https://legion-expert.ru/index.php?option=com_jmap&view=sitemap&format=xml";"//*[local-name()='url']/*[local-name()='loc']")
Здравствуйте. Подобных статьей как у Вас нету! Очень понравилась информация, спасибо!
Пробую тоже парсить прайс но yml.
Что-то не выходит. Вроде, всё делаю как написано. Если не сложно, не могли бы глянуть, что не так в такой строчке?
=IMPORTHTML ("http://itsellopt.com.ua/price_lists/prom_price_oHbo2B.yml";"//category")
В качестве результата пишет: Ошибка. Объем импортируемых данных превышает максимальный.
Прочитав выше попробовал переменить на своем примере но ничего не вышло...
Добрый день, в комментарии выше я советовал использовать функцию xPath local-name, вы ее не использовали — это первое "что не так" в вашей формуле. Правильное написание вот такое.
=IMPORTXML ("http://itsellopt.com.ua/price_lists/prom_price_oHbo2B.yml";"//*[local-name()='shop']/*[local-name()='categories']/*[local-name()='category']")
Но это все не имеет смысла, потому что данных слишком много, поэтому выгрузить их данным способом все равно не получится. Лимит на выгрузку данных составляет порядка 1000 строк.
Добрый день. А что если объект парсинга это url в кирилице, есть какой-то способ получить такие урлы?
Вместо искомого получаю кракозябры вида "http://%441%43F%430%439%441%43E%432%430%44F-%437%430%432%438%441%438%43C%43E%441%442%44C-%43B%435%447%435%43D%438%435.%440%444".
Первое, что приходит в голову — найти сервис-декодер к которому можно обратиться по урл и спарсить декодированный результат (принцип аналогичен парсингу кода ответа сервера, который описан в статье).
Например, можно использовать сервис https://2ip.ru/punycode/
пример урл для обращения https://2ip.ru/punycode/?domain=http://xn-----6kcb0araadnnat0cgs3f.xn--p1ai/ (свой урл подставляйте после "?domain="), парсить надо содержимое этого поля http://prntscr.com/jzxt1b
Допускаю, что может быть как-то можно декодировать урлы на лету с помощью формул, но в данный момент я о таком способе не знаю.
Разумно, но до первой капчи.
Добрый день!
Формулой =importxml ("https://norgau.com/тн113432.html";"//div[@class='stock availabler']") хочу достать информацию о главном товаре на странице — наличие или доставка...
Проблема в том что кроме главного товара, на странице отображается еще несколько товарных карточек со своим собственным значением class='stock availabler'.
Можно ли как то настроить формулу что бы она не собирала все значения class='stock availabler' со страницы, а только с конкретной строки?
Добрый день. Если вы посмотрите в код, то увидите, что данный div обернут в другой с уникальным классом 'product-info-stock-sku' настраивайте формулу по этому классу и все будет ок, вот формула.
=IMPORTXML ("https://norgau.com/тн113432.html";"//div[@class='product-info-stock-sku']")
Спасибо!
Из этой же темы, нужно подтянуть url адрес главной карточки товара, единственное место где я его нашла в коде <meta property="og:image" но опять же таких значение два. Формула =importxml ("https://norgau.com/тн113432.html";"//meta[@property='og:image']/@content")
Привет! Спасибо за статью! Очень доступно написано ;)
Подскажи, как парсить (возможно ли забрать цену?) вот такое: <span class="dxeBase_ZzapAqua" id="ctl00_BodyPlace_SearchGridView_ctl29_SearchInfoAllPanel_PriceMinInstockLabel">410р.</span>
Пример страницы вы не дали и в чем заключается проблема непонятно.
Чем стандартный вариант выдергивания класса или id не устраивает?
=imortxml ("ссылка";"//span[@class='dxeBase_ZzapAqua']")
Вот здесь мои попытки (выделено оранжевым):
https://docs.google.com/spreadsheets/d/1necr6fN5GvdMDjHb1eird2anG1MF1PT5YCP8o5Ytjl8/edit?usp=sharing
Пытаюсь получить минимальную или среднюю цену.
=imortxml ("ссылка";"//span[@class='dxeBase_ZzapAqua']") но там в коде еще встречается id, и как его сюда прикрутить — не могу понять(
Спасибо за пример. Огорчу вас, на этих страницах вы не сможете ничего спарсить — на zzap.ru информация подтягивается динамически т.е. уже после того как бот посетил страницу, а на elcats.ru доступ к указанной странице вообще запаролен — бот дальше пароля пройти не сможет.
Благодарю, что посмотрели пример и ответили развернуто ;)
Как понять изначально — возможен парсинг или нет?
Вы описали "Путь бота", но как Вы это поняли (софт, код, опыт)?
"Вы описали "Путь бота", но как Вы это поняли (софт, код, опыт)?" — нет, это просто факт: бот не видит данные под паролем.
"Как понять изначально — возможен парсинг или нет?" — обычно это только в процессе можно понять, исключение — сайты типа zzap, где сразу понятно, что данные подсасываются динамически по надписи "Загрузка".
есть ли возможность парсить таким образом сайт morningstar .com
например раздел "Movers"--"Stock Name" (таблица)?
//div[@class='main-content']//div[@class='table-wrapper']//span[@class='no-wrap']
не получается, спасибо за совет
Нельзя парсить данные, которые подгружаются динамически.
Здравствуйте! Спасибо за статью.
У меня есть такая задача, необходимо с этого сайтаhttp://www.probankrot.ru собирать информацию по определённым лотам, и заносить в таблицу, для примера возмём вот эту страницу http://www.probankrot.ru/node/2527098, с неё мне нужно (наименование, цена, регион и т.п.)
Испытав различные способы я так и не смог добиться результата, в гугол таблице выдаётся ошибка n/a.
Удалось каким-то образом наименование скопировать, по этой формуле =ImportXML ("http://www.probankrot.ru/node/2527098";"//title"), но как я понимаю это не верная формула, т.к. она берет данные из названия страницы.
=importxml ("http://www.probankrot.ru/node/2527098";"//div[@class='s_start_price']").
перепробовал уйму вариантов так и не смог добиться результатов. Помогите пожалуйста :)
Ссылка на скриншоты https://yadi.sk/i/gWJxACN2TMKgqA, https://yadi.sk/i/ShkpOq8z5LyNZg, https://yadi.sk/i/iegW67bNEuNPBw
В заранее спасибо! :)
Здравствуйте. На этом сайте название лота автоматически попадает в тег keyword (скриншот http://prntscr.com/lq66jr) — это самый простой вариант его вытащить =importxml ("http://www.probankrot.ru/node/2527098";"//meta[@name='keywords']/@content").
Но любые данные после блока <head> спарсить формулой не получается, причину сходу не увидел, нужно искать другой способ — эта формула тут, к сожалению, не поможет.
Спасибо за ответ.
Подскажите, а какие ещё варианты есть спарсить ?
Какие способы рассмотреть можно чтобы данные после блока <head> спарсить.
Не получается запарсить курс доллара со страницы https://kurs2015.ru/
Возможно ли создать такой скрипт чтобы на гуглодокс табличку в ячейке отображался всегда актуальный курс доллара?
Вы не сможете спарсить курс доллара с той страницы т.к. он загружается на страницу скриптами, а формула парсит только статичные данные.
Создать скрипт возможно, в гуглдоксах есть подобный функционал
Доброго времени суток! Спасибо за статью! Попробовав применить её, столкнулся с проблемой. Необходимо со страницы https://www.moex.com/ru/issue.aspx?board=TQBR&code=LSRG парсить актуальную цену акции. Возможно ли это?
Добрый день, спарсить данные с динамической страницы не получится, формула может извлечь только статичные данные.
Привет. Только начинаю разбираться в таблицах и столкнулся с проблемой. Подскажите как решить ее. В общем:
Пробую мониторить цену с сайта. Все отлично, категории выгружаются без проблем. Одно но: на сайте 4 города, а товар подтягивается всегда из первого в списке. Т.е. при выборе например Новороссийска, цена подтягивается из калининграда в любом случае.
Ссылка на таблицу: https://docs.google.com/spreadsheets/d/1jE4F-i4u1WEwDGf3bXeyl9ZsR550qUd_sE71Y91S11k/edit?usp=sharing
В данном случае спарсить цену из другого города не получится. На уровне идеи — можно разве что попробовать каким-то образом заходить на сайт через прокси нужного города, чтобы на сайте сразу же подставлялись необходимые значения для этого горда. Но как это все адекватно обыграть я не могу прямо сейчас придумать.
благодарю за предложенный способ. почти всё получилось. названия, линки и всё такое парсится ))
но не могу разобраться как получить из <a href > електронку. на последней старнице необходимо взять имя и почту, так вот имя вытягивает, а почту нет ((
фрагмент к которому идет запрос:
<a href="mailto:30minvask@gmail.com" data-toggle="tooltip" title="" class="btn btn-sm rgba-bluegrey-strong fa fa-envelope ph_ma_icon" rel="nofollow" data-original-title="E-post"> </a>
Конечно, без конкретной ссылки конкретный пример я не дам, но пример покажу.
Для того, чтобы вытащить содержимое ссылки надо использовать такую конструкцию =importxml ("link";"//a/@href"), где вместо "link" должна стоять ссылка на страницу откуда парсим.
В итоге у вас должно спарситься это содержимое "mailto:30minvask@gmail.com" без кавычек
второй шаг — обрезаем ненужное "mailto:", для этого оборачиваем нашу формулу в другую формулу, вот так =concatenate (importxml ("link";"//a/@href");"mailto:";"")
На выходе в ячейку должен падать адрес почты.
По идее все должно работать, но если не будет — присылайте ссылку на страницу, посмотрю детальнее
Добрый день! Подскажите пожалуйста, возможно ли спарсить данные фильтров со страницы https://www.digikey.com/products/en/capacitors/ceramic-capacitors/60 ? Перепробовал уже много вариантов но не получается.(
Формула
=importxml ("https://www.digikey.com/products/en/capacitors/ceramic-capacitors/60";//select[@name='v'])
name — это название блока фильтров, в данном случае я выгружаю значения фильтра Manufacturer
Выгружаемые данные получились такими:
AVX Corporation
KEMET
Taiyo Yuden
Walsin Technology Corporation
Чтобы спарсить значения других фильтров надо подставлять соответствующие значения name.
Это то, что вам было нужно?
Подскажите пожалуйста, как спарсить количество подписчиков группы вконтакте?
Делаю так =importxml (A1;"//span[@class='header_count fl_l']")
A1 это ссылка на группу https://vk.com/kudago
В итоге выдает: #Н/Д
У меня тоже не получилось спарсить, пишет "JavaScript and Cookies need to be supported in order to use the site.".
То есть ВК не отдает контент, если не включены скрипты и стили, а у бота таблиц они не включены. Я с таким еще не сталкивался и в данный момент не знаю возможно ли обойти это ограничение в рамках рассматриваемых функций гуглдоков
Добрый день! Как спарсить больше 1000 значений? Мне пишет «Объем импортируемых данных превышает лимит»
Добрый день, насколько я знаю это ограничение нельзя обойти, по крайней мере мне о таком неизвестно.
Добрый день, как расположить данные не в столбик а в строчку?
К примеру, есть список товаров, а у каждого товара есть цвета (и, соответственно, есть своя цена).
Здравствуйте.
Без конкретного примера я не знаю правильно ли я вас понял, но попробуйте обернуть функцией transponse ().
Пример: =transponse (importxml ("link";"//xpath"))
где "link" — ссылка откуда парсим, а "//xpath" — запрос xpath
Все значения будут выгружаться не в столбик, а в строку с разбивкой по ячейкам
Пытался импортировать таблицу с товарами из Seller Hub на Ebay с помощью importhtml. В коде страницы тег <table> встречается 4 раза. Ни один из них не дает желаемого результата. Вместо него каждый раз получаю N/A. В чем может быть проблема?
Я с ебэем не работал, не знаю даже о чем речь. Возможно вы пытаетесь спарсить данные со страницы, требующей авторизацию. Бот авторизовываться не умеет, соответственно не видит данные. Если данные доступны без авторизации, то проверьте есть ли они в коде. Если есть, то пришлите ссылку и чёткое описание того, что нужно.
Подскажите, как с помощью Google Doc выгрузить все URL сайта
Добрый день. Никак. Вам нужны программы типа Comparser, Screaming Frog, Majento SiteAnalayzer и т.д. Последняя, кстати, полностью бесплатная
К сожалению не было примера — как снять табличку амортизации например из такой странички
https://www.rusbonds.ru/ftam.asp?tool=132578
Каким образом нужно написать формулу Xpath в таких случаях?
Никак не снять т.к. для получения данных нужна авторизация, бот этого делать не умеет.
Подскажите пожалуйста, как спарсить количество страниц в индексе гугла?
Использую функцию: =importXML
''А1'' у меня домены в таблице
Но почему-то ничего не работает — одни ошибки...хелп((
Я тоже раньше пробовал решить подобную задачу, но с помощью данных функций это сделать нельзя.
Здравствуйте!
Подскажите пожалуйста, допустим с сайта картотеки арбитражных дел (не требующим авторизаций), на примере допустим вот такой карточки дела (https://kad.arbitr.ru/Card/29b30b57-a8a1-4a57-ac12-2d01a36b8f8b). Как получить информацию о дата следующего заседания с помощью Importxml ? Все попытки заканчивались получением N\A в таблице.
Как только уже не пробывал...
=IMPORTXML ("https://kad.arbitr.ru/Card/29b30b57-a8a1-4a57-ac12-2d01a36b8f8b";"/html/body/div[1]/div[1]/dl/dd/div[3]/div/div[2]/div[2]/div[1]/div/div[1]/div[2]/div/text ()")
=IMPORTXML ("https://kad.arbitr.ru/Card/29b30b57-a8a1-4a57-ac12-2d01a36b8f8b";"//div[@class='b-instanceAdditional']")
=IMPORTXML ("https://kad.arbitr.ru/Card/29b30b57-a8a1-4a57-ac12-2d01a36b8f8b";"//*[@id='chrono_list_content']/div[1]/div/div[1]/div[2]/div/text ()")
И масса других похожих вариантов — результат N\A.
ДД!
подскажите как из
/html/body[@class='a-show-page']/main[@class='container']/div[@class='layout__container main-col a-item']/div[@class='layout__content']/div[@class='offer__container']/div[@class='offer__sidebar']/div[@class='offer__advert-info']/div[@class='offer__short-description']/div[@class='offer__info-item'][5]/div[@class='offer__advert-short-info']
получить результат —
Ну так вроде, если я правильно понял то, что вы скинули =importxml ("URL";"//div[@class='offer__advert-short-info']")
но это не точно, если на странице дублируется класс, то этот вариант не подойдет
Всем привет. Подскажите, а есть ли все таки метод как обойти логин пароль? Нужно выдергивать данные из админки...
В рамках этих функций — нет
Я не могу собрать данные. Помогите разобраться. Я думаю, что дело в знаке # в адресе ссылки... формулу делаю так IMPORTXML (ссылка; запрос_xpath) моя ссылка https://navigator.new.sk.ru/navigator/#/orn/1122464 мой xpath //div[contains(text(),'9731020344')]
В принципе ничего со страницы не собирает, хоть какой xpath ставить
Контент страницы генерируется скриптом, бот его не видит, поэтому и достать ничего нельзя
Пара вопросов:
1. Есть ли аналог функции IMPORTXML в Экселе? Мне нужно пропарсить тысяч 10 страничек, подобных этой [= MID(IMPORTXML("https://youcontrol.com.ua/ru/catalog/company_details/32944836"; "//tbody/tr[2]/td[2]/a[contains(@href, 'mailTo:') or contains(@href, 'mailto:')]/@href");8;100)] на предмет получения e-mail, но уж больно много на это уходит времени — видимо есть какой-то суточный лимит. Возможно, подскажете, как можно оптимизировать\ускорить задачу.
2. Как оформить формулу из п 1. для того, чтобы при отсутствии данных для отображения я получал бы сообщение к примеру "адрес почты отсутствует". Сейчас в случае отсутствия данных равно как и в случае обработки запроса (который может длиться сутки) получаю n/a, а мне такой ответ не подходит — нужно понимать стадию.
1. Аналога нет. Лимиты на аккаунт не обойти, но можно использовать разные аккаунты
2. Если формула еще не отработала, то в ячейке будет написано loading, а #N/A вы получаете только в одном случае — если по вашему запросу не найдено данных.
В вашем случае #N/A будет выдавать всегда т.к. формула кривая (ошибки в синтаксисе).
Я вытащил почту такой формулой =IMPORTXML ("https://youcontrol.com.ua/ru/catalog/company_details/32944836/";"//table[@class='seo-table-item']/tbody/tr[2]/td[2]/a")
Здравствуйте, подскажите пожалуйста как считать цену — вот мой запрос =IMPORTXML ("https://www.220city.ru/product/136306"; "//font[@itemprop='price']") но ответ занимает 3и ячейки место одной. Можно ли как то уточнить запрос чтобы ответ был одной ячейкой ?
Ответ выходит на несколько ячеек, потому что в коде дублируется тот блок, который вы хотите спарсить.
Попробуйте так =IMPORTXML ("https://www.220city.ru/product/136306";"//div[@class='info-block buyer-block ms']/div/div/font[@itemprop='price']")
Добрый день, подскажите пожалуйста, как выгрузить страницы сайта на которых содержится определенный запрос, к примеру неправильное написание названия компании?
Добрый день. Данной формулой — никак.
можно использовать программы Screaming Frog SEO Spider или Comparser — они парсят все страницы сайта, в их функционале есть возможность задать поиск любых вхождений в коде страницы.
В Screaming Frog SEO Spider перед парсингом пропишите условия в этих настройках "configuration->custom->search"
В Comparser в верхнем меню "Поиск кода"
Доброго времени . Помогите исправить результат выдачи на:
=IMPORTXML ("https://butikobuff.com.ua/g43755078-obuv-muzhskaya?csbss6=47748739&csbss4=47748735"; "//img [@class='b-product-gallery__image'] /@src")
Я получаю всего 3 фото из 24. В чем моя ошибка? Зарание Спасибо.
Решено. Взял фото со страниц товаров.
Добрый вечер! Помогите вывести данный с сайта. Делаю всё по инструкции, но выдаёт ошибку.
=IMPORTXML ("https://www.amazon.com/dp/B07MVJNXL9";"//*[@id='priceblock_ourprice']/span/text ()")
Если я правильно понял, и вы хотите вытянуть цену, то
=IMPORTXML ("https://www.amazon.com/dp/B07MVJNXL9";"//span[@id='priceblock_ourprice']").
Доброго времени суток!
у вас все очень качественно написано, но очень прошу помочь разобраться
согласно Пример 3. Выгружаем актуальные цены //div[@class=
попытка получить значение - стоимость в долларах
=importxml("https://coinmarketcap.com/currencies/digibyte/";"//div[@class='cmc-details-panel-price__price']")
выдает ошибку #Н/Д
Доброго! На сайте цена находится в контейнере span, а в формуле вы указали div, поэтому результат и не ищется.
Поменяйте формулу вот так
=importxml ("https://coinmarketcap.com/currencies/digibyte/";"//span[@class='cmc-details-panel-price__price']")
Подскажите пожалуйста, возможно ли имея все ссылки сайта на товары выгрузить наличие товара и отсутствие товара, использую формула (думаю она есть, а вот какая подскажите???).
Добрый день, если информация есть на страницах, то скорее всего её можно вытянуть, принцип будет полностью аналогичен описанным примерам в статье.
Здравствуйте, Алексей.
Прочел вашу статью и она мне очень помогла, но не полностью. Возник вопрос, на который я не могу ответить. Я начинающий в этой сфере.
Мне необходимо импортировать данные с сайтов отзовмков для мониторинга рейтингов некоторых компаний. У меня получилось ипортировать рейтинг с площадки Яндекс.Карты. К примеру, вот карточка организации:
https://yandex.ru/maps/2/saint-petersburg/?clid=22698...
В коде элемента там где обозначается значение рейтинга (слева сектор, который передвигается только вертикально), я вижу данную формулу: <span class="business-rating-badge-view__rating-text _size_l">5.0</span> . Пользуясь информацией с вашей статьи я смог синтезировтаь формулу, которая позволит импортировать данный рейтинг. Получается: //span[@class='business-rating-badge-view__rating-text _size_l']
Дальше, мне потребовалось провернуть такую же процедуру и с другой площадкой — Google Карты:
https://www.google.ru/maps/place/Государственный+Эрми...
В данном случае, при переходе на карточку организации и просмотре кода рейтинга, я вижу там уже не простую формулу, как на Яндекс.Картах, а более сложную, состоящую из большого количества частей:
<span aria-hidden="true" jstcache="742" class="section-star-display" jsan="7.section-star-display,0.aria-hidden">4,8</span>
Кроме "class", здесь присутствует еще несколько равных значений, чего не было на Яндекс.картах.
Не могли бы вы подскачать, как сентезировать конечную формулу для получения рейтинга в данном случае?
Буду признательно благодарен за любую помощь с Вашей стороны.
Приветствую. В данном примере абсолютно ничего не меняется. Разбейте вашу задачу на шаги, так будет легче понять, что делать. Для начала надо найти тег-контейнер с информацией. Это тег span. Дальше вам нужно выбрать атрибут, по которому пойдет поиск, удобнее всего выбрать class="section-star-display" т.к. этот класс больше нигде не встречается на странице. Итоговая формула будет такой
=importxml ("https://www.google.ru/maps/place/ссылка";"//span[@class='section-star-display']")
Желаю успехов в начинаниях!)
Алексей, здравствуйте
Подскажите, можно ли с помощью xml лимитов (xml.yandex или xmlriver) получить в ответе частотность запроса. В идеале в кавычках и без. На данный момент не нашел ни одной темы об этом. Но ведь программы-парсеры используют лимиты для получения этих данных. Предполагаю, что и в ручном режиме это должно быть... Можете подсказать ссылку?
Алексей, здравствуйте
Пробовал спарсить данные с помощью =importxml с сайта http://www.proagro.com.ua/reference/vedua/uktzed/
текстовое содержание таблиц Кодов УКТЗЭД в каждой подгруппе таблица, ни как не могу в коде выдернуть , все время пишет нет данных, помогите пожалуйста.
Здравствуйте!
Как быть когда на сайте постраничная навигация? Парсит только первую страницу. Пример:
Сайт https://www.airlines-inform.ru/west_europe/3.html
Формула: =IMPORTXML (C1;"//dl[@class='airlist']")
Всем добрый день!
А подскажите, пожалуйста, как можно вытянуть данные с данного сайта (https://www.ford.com.tr/fiyat-listesi/ford-transit-minibus-fiyat-listesi)
Дана таблица с ценами, как бы их вытащить наиболее грамотно?
Добрый день!
Прочитал Вашу статью. Очень информативно, спасибо за Ваш труд. Буду очень благодарен, если Вы поможете мне выгрузить данные с указанной ниже страницы:
https://www.glencoreagro.ru/ru/price-list/pages/rostov-on-don.aspx
Пробовал вот так: =IMPORTHTML ("https://www.glencoreagro.ru/ru/price-list/pages/rostov-on-don.aspx";"table";1)
Ответ: нет данных для импорта.
Меня смущает приставка aspx в конце адреса сайта. С него вообще можно получить информацию?
Хочу получать актуальные цены с сайта в гугл таблицу.
Заранее Вас благодарю!
Здравствуйте
Не могу сделать importxml «Получить даные в XML — формате» с сайта https://www.moex.com/ru/derivatives/go_futures.aspx
Подскажите, по поводу ограничений importxml — если страница браузера закрыта, а комп выключен — парсинг/скрапинг продолжается? :) нигде не могу про это найти инфо. Если у кого есть ссылка — поделитесь. Заранее благодарю.
Добрый день
Как ни хотелось разобраться самостоятельно, но не получается.
Требуется спарсить только вес товара, а получается собрать все атрибуты. К сожалению у них у всех одинаковые div.
Как решить этот вопрос?
Использую:
=IMPORTXML (A42;"//div[@class='S34I2']")
Где A42:
https://sima-land.ru/4021447/kartonnaya-kniga-angliyskiy-yazyk-moi-pervye-slova-10-str/
Заранее спасибо
В продолжение к предыдущему вопросу
Использовала команду индекс, но к сожалению, в каждом товаре количество параметры меняется, поэтому а если к одному товару данный вариант подходит, то к другому нет.
Нужно искать «Вес брутто» и брать значение после этих слов.
Но как именно это оформить я не смогла найти.
Зрдавстуйте
А как парсить инфо с сайтов, где требуется авторизация ?
Здравствуйте. А такое <td data-v-d8b0497c> 9.99 </td> можно вытащить с сайта https://www.gurufocus.com/stock/GILD/summary?
Подскажите почему с данного сайта ничего не получается забрать? https://catalog.onliner.by/milkfrother/ikea/ikeaprodact
Всегда получается ошибка Объем импортируемых данных превышает максимальный. Нужно по ссылке забрать название товара
Здравствуйте, подскажите как мне забрать из таблицы данных на сайте только 1 интересующую меня ячейку? например на сайте https://finviz.com/quote.ashx?t=ABB меня интересуют ячейки с дивидендами, не пойму как мне определить эту ячейку, так как tbody у всех элементов одинаковые названия?
через XPath нужно искать уникальное значение, не обязательно у самого элемента, уникальным должен быть именно путь. Как например на компьютере у вас есть разные папки в которых лежит много одинаковых файлов, если просто в поиске вбить имя файла, то выдаст кучу одинаковых копий, а если вы в строке проводника пропишите конкретный путь к конкретному файлу, то он будет уникальным и система найдет только этот файл. Аналогично нужно делать и при поиске по XPath
ДД. Пытаюсь спарсить цены с Яндекс Маркета, цены отображаются, все хорошо. Но после того как цену меняют, она не меняется в таблице. Памагити)))
Возможно вы превысили лимиты, обновление происходит раз в час. Чаще нельзя
Здравствуйте, а можно как нибудь опубликовать на сайте Гугл таблицу или Эксель таблицу, так что бы в эту таблицу можно было бы вносить изменения через сайт и эта таблица автоматически сохранялась на сайте
Можно попробовать через iframe, наверное, но я не пробовал, так что не знаю. Но видел подобные решения и, если там нет каких-то технических хитростей, все должно работать.
Здравствуйте! Отличная статья, очень помогла в работе, спасибо!
Не могу спарсить цену с этой страницы: https://www.grandline.ru/profnastil-s8a-0-35-zn-17671.html
Вроде в коде все просто <strong class="product-buy-fixed-panel__price">356 ₽/м<sup>2</sup></strong>
Делаю так: //strong[@class='product-buy-fixed-panel__price']
Однако вместо цены в ячейке появляется #Н/Д
"Ошибка
Объем импортируемых данных превышает максимальный."
То же самое, если парсить через XPath
Не подскажете, в чем может быть загвоздка?
Здравствуйте, всем у кого есть проблемы с настройкой и поиском элементов по XPath. Платно помогу, настрою и научу парсить. Также если стандартными методами задача не решается, то разработаю отдельные алгоритмы.
Цитата:
"Здравствуйте, всем у кого есть проблемы с настройкой и поиском элементов по XPath. Платно помогу, настрою и научу парсить. Также если стандартными методами задача не решается, то разработаю отдельные алгоритмы."
Ser — прошу связаться со мной по e-mail: azzzimutсобакамэилточкару
Думаю многих мамам будет интересно почитать статью https://lella12finance.com/kak-schitat-zp-nyane-i-vesti-uchyot-v-gugl-tablicze/
Очень помогает, а если объединить знания с данной статьей, так вообще будет в разы проще
Здравствуйте, можно ли прописать функцию, по аналоги с подсчетом количества страниц в индексе, что б ответом был наличие в индексе конкретного урла?
Добрый день. Подскажите по поводу вытягивания ссылок на , заглянув в код, не увидил, что ссылки на товарные страницы располагаются в теге <p> c классом CMtext4. У меня как то всё по другому, тег <p> вообще не вижу. Идея вообще парсить весь список подшипников с сайта https://abs-shar.ru/catalog/podshipniki/
Здравствуйте, пытаюсь выгрузить данные из yml-фида в гугл таблицу с помощью importxml. Ошибка N/D "Объем импортируемых данных превышает максимальный." Этот способ вообще пригоден для парсинга yml?