 Привет, друзья! Сегодня я наконец-то готов представить вам свой новый софт для проверки и изучения индексации сайта. Взглянул на дату и оказалось, что с момент старта разработки прошло почти 3 месяца. А мне казалось, что про краудфандинг я писал совсем недавно. Планировал успеть все за месяц, но сначала увольнение с работы, организацией свой веб-студии, конференция и т.д. и т.п. Правда и с программой в этот раз я провозился долго, захотелось сразу все учесть вплоть до мелких подробностей, при том, что полностью рабочий образец был готов уже через 2 недели после старта.
Привет, друзья! Сегодня я наконец-то готов представить вам свой новый софт для проверки и изучения индексации сайта. Взглянул на дату и оказалось, что с момент старта разработки прошло почти 3 месяца. А мне казалось, что про краудфандинг я писал совсем недавно. Планировал успеть все за месяц, но сначала увольнение с работы, организацией свой веб-студии, конференция и т.д. и т.п. Правда и с программой в этот раз я провозился долго, захотелось сразу все учесть вплоть до мелких подробностей, при том, что полностью рабочий образец был готов уже через 2 недели после старта.
Ну да ладно, не об этом сейчас речь!
Итак, новая программа называется ComparseR! Это название получилось из слияния двух слов Comparison и Parser, т.е. сравнение и парсер. В этом и есть вся суть программы: мы парсим сайт, парсим его проиндексированные страницы в выдаче и сравниваем эти данные между собой.
Все просто, но получилось очень круто, даже сам не ожидал. Сейчас все расскажу и покажу.
Друзья, рекомендую прочитать все, что написано ниже, пусть много, но зато все по делу: что умеет программа, как это работает и мои рекомендации. Но для лентяев просто оставлю тут ссылку на промо-сайт, там есть вся основная инфа и короткое описание.
Описание и основные возможности ComparseR
Главное окно программы выглядит примерно вот так:
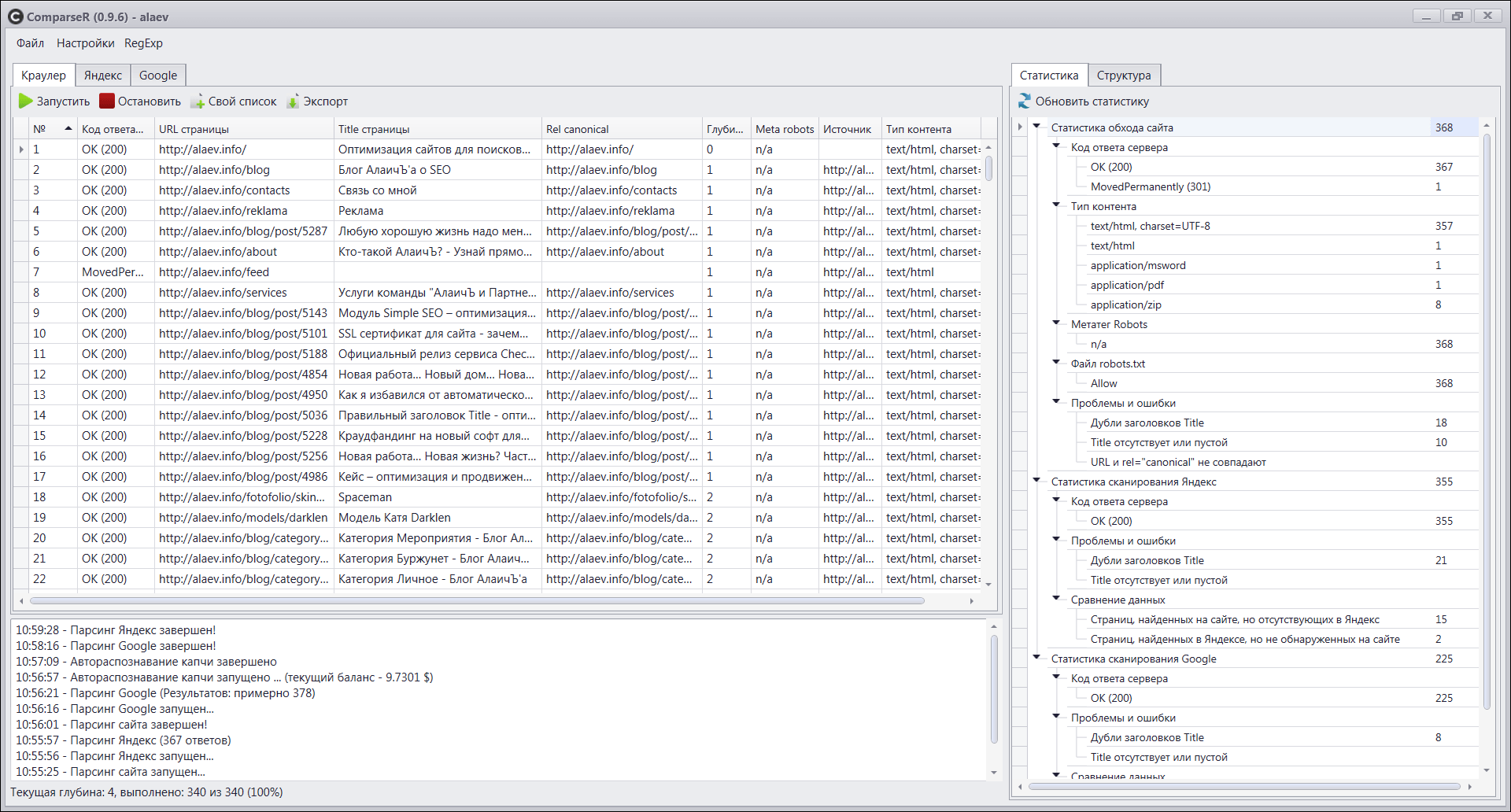
На данном скриншоте отображена основная рабочая область программы, где видны результаты обхода сайта краулером. Те, кто пользовался программами типа Xenu Sleuth, Netpeak Spider, Page-Weight, ScreamingFrog быстро разберутся, что к чему.
При обходе сайта, программа собирает следующие данные:
- Код ответа сервера – чтобы определить 404 ошибки, внутренние редиректы и другие ошибки.
- URL страницы – ну, тут все понятно.
- Title страницы – очень важный параметр, всегда можно будет посмотреть, например, где дубликаты, а где title и вообще отсутствует.
- Rel canonical – если на странице присутствует meta-тег canonical, программа сохранит его содержимое. Кстати, у меня есть большой пост про link rel=canonical, рекомендую прочитать.
- Глубина парсинга – так я условно назвал количество кликов от главной до исследуемой страницы. Чтобы добраться до определенной страницы необходимо совершить 3 перехода по ссылкам от главной страницы, это значит эта страница будет иметь глубину 3.
- Meta robots – если на странице будет найден метатег robots, программа сохранит его содержимое. Напомню, что и о мета роботсе я тоже писал большую полезную статью.
- Файл robots.txt – здесь может быть только 2 значения Allow и Disallow в зависимости от настроек вашего файла robots.txt. Полезно для изучения закрытых от индексации частей сайта.
- Источник – это адрес страницы, с которой был совершен переход (найдена активная ссылка) на исследуемую страницу.
- Тип контента – полезно для просмотра и поиска не html содержимого сайта (архивы, файлы и т.д.)
Я посчитал, что этой информации достаточно для изучения индексации сайта. Но в то же время нет никаких ограничений в том, чтобы добавить какой-то новый параметр или характеристику страницы. Я с радостью выслушаю предложения и пожелания от всех пользователей программы.
Благодаря тому, что при обходе сайта программа не хранит все ссылочные связи всех страниц, как это делают другие программы, а только связку «текущий url – url источник» удалось добиться высокой скорости парсинга, низкого потребления памяти и возможности парсить сайты размером в миллионы страниц. Последнее напрямую зависит от объема оперативной памяти на вашем компе, по моим прикидкам, стандартный компьютер с 8 GB RAM сможет потянуть проект размеров в 2-3 миллиона строк. А вам слабо? :) Ради эксперимента я максимум собирал 700к страниц, а потом надоело, и я решил не мучать комп и остановил парсинг.
Для желающих есть возможность отправить в программу свой список страниц для обхода или же указать для проверки sitemap.xml.
Ниже основной рабочей области расположен лог программы, где фиксируются все важные события и ошибки, если они возникают. Пользователи программы FastTrust с этой штукой уже знакомы.
Справа от рабочей области есть окно со статистикой. Пожалуй, это самая ценная вещь! Программа классифицирует и группирует собранные данные. Например, программа может показать только страницы 404, или страницы по определенному типу контента, только индексируемые или не индексируемые страницы, страницы с одинаковым title или где title отсутствует вообще. Подобные отчеты доступны и для страниц, собранных из выдачи поиска.
А вот то, ради чего вообще вся программа затевалась изначально! После парсинга сайта и выдачи поисковиков можно будет посмотреть отчеты: страницы, которые были найдены на сайте, но отсутствуют в поиске и наоборот, страницы, которые нашлись в выдаче, но не были найдены при обходе сайта. Такие отчеты доступны отдельно для Яндекса и Гугла.
Благодаря этим отчетам вы сможете узнать, какие страницы вашего сайта индексируются, а какие нет. Но это банально, да ведь? Гораздо интереснее узнать, что есть в индексе такого, чего нет на сайте! Интересно же? Например:
- Самый типичный случай – сменили структуру сайта или вообще создали новый сайт, а редиректы со старых адресов не прописали. Очень часто такое случается, когда в процессе не задействован оптимизатор, а разработчики и думать не знали про редиректы. Старые урлы сайта останутся в выдаче, и в лучшем случае будут выдавать 404 ошибку, а в худшем будут отдавать ответ 200 и создавать дубли!
- Ненужные адреса страниц могут попасть в выдачу, даже если на них нет ссылок внутри сайта. Есть масса способов поисковику узнать о наличии страницы на сайте – браузер (Яндекс.Браузер пингует адреса в Яндекс, Chrome пингует в Google), дополнение/расширение/плагин (Яндекс.Бар пингует адреса в Яндекс), счетчик (Яндекс.Метрика, если не отключить соответствующую опцию, будет отправлять адреса на индексацию). Помните же историю с индексацией SMS-сообщений абонентов Мегафона Яндексом http://www.rb.ru/article/yandeks-raskryl-lichnuyu-perepisku-abonentov-megafona/6737357.html. Может быть и у вас есть страницы, не предназначенные для индексации, но уже попавшие в индекс?
- Очень часто к адресам страниц «прилипают» параметры. Они могут генерироваться соцсетями, когда вы размещаете там ссылки на свой сайт. Для учета статистики рекламных кампаний ссылки стоит размечать при помощи UTM_ меток, это тоже параметры и они могут индексироваться. Если не использовать rel=canonical или не запретить в robots.txt индексацию параметров, то могут индексироваться полные дубли страниц, тем самым понижая основную страницу. Узнать это можно только изучив страницы в индексе.
На самом деле, подобных распространенных примеров можно привести еще штук 10, но это уже предмет отдельного разговора.
Давайте отдельно рассмотрим парсинг поисковых систем.
Парсинг выдачи поисковых систем Яндекс и Google
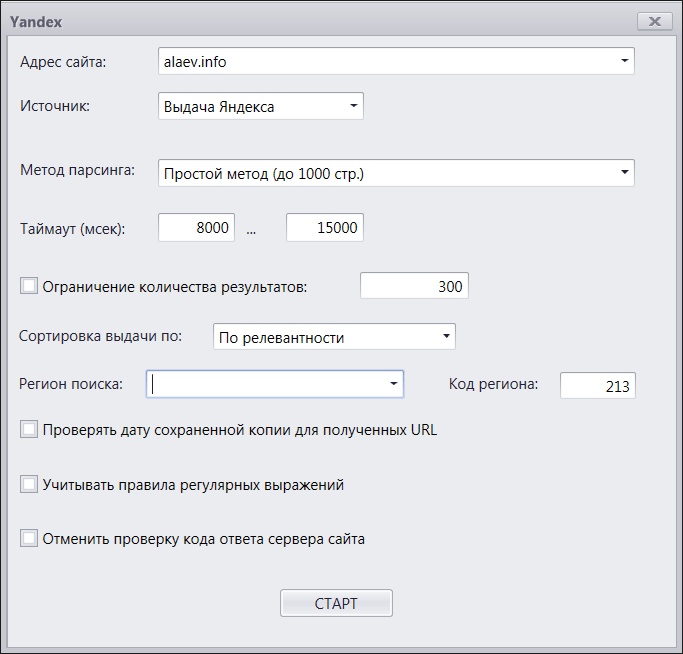
Когда вы переключитесь на вкладку «Яндекс» и нажмете кнопку «Запустить», перед вами появится окно с настройками парсинга:
Рассмотрим чуть подробнее:
- Адрес сайта – тут все понятно, можете указывать в любом виде, с www или без www, с http:// или без, это не важно. Программа сама все поймет и начнет сканировать сайт.
- Источник – крутая фишка! Для Яндекса можно получать данные из трех источинков. Поисковая выдача – обычный парсинг выдачи с запросом типа site:alaev.info, самый универсальный метод. Яндекс XML – парсинг выдачи через XML, быстро, эффективно, без капчи, нужен только доступ в xml.yandex.ru и наличие доступных лимитов. Яндекс Вебмастера – так же быстро и без капчи, но только парсить вы можете сайты, подтвержденные в вашем аккаунте, данные для доступа к которому вы можете указать в настройках.
- Метод парсинга – как вы знаете, из поисковой выдачи можно собрать не более 1000 результатов по любому запросу. Для сайтов у которых страниц мало, нет никакой головной боли, а вот для больших сайтов возникает вопрос – что же делать? Действовать методом перебора. Для этого сначала надо спарсить краулером сам сайт, построить его структуру (вкладка «Структура» — «Построить дерево») и опираясь на эту структуру парсить сайт по частям. Метод интересный и сложный, имеет много особенностей, но это тема отдельного разговора, я этому посвящу специальный раздел на промо-сайте. Главное, что метод перебора позволяет в большинстве случаев обойти ограничение в 1000 результатов и собрать из выдачи бОльшее количество страниц.
- Таймаут – задержка между запросами к поисковой выдаче. Для парсинга выдачи нужно ставить большие задержки, для парсинга XML можно ставить минимальные задержки, так же как и для парсинга Вебмастера, т.к. там нет капчи. Для облегчения участи, разумеется, предусмотрена поддержка сервисов антикапчи.
- Ограничение количества результатов – вдруг кому-то покажется, что парсить надо не все, а только часть, или кто-то решит оказывать услуги по парсингу выдачи за деньги с оплатой за результат :) …я не знаю.
- Сортировка выдачи – есть два варианта: по релевантности, когда показывается стандартная выдача, и по дате, когда свежепроиндексированные документы отображаются вначале. Кому-нибудь эта настройка будет полезной.
- Регион поиска (код региона) – если вы не знаете код региона, можете начать вводить, программа автоматом определит город и подставит код, а можете сразу указать код сами.
- Проверять дату сохраненной копии – да, программа может парсить дату сохраненки, что очень полезно, например, для того, чтобы понять, как часто переиндексируются страницы вашего сайта.
- Учитывать правила регулярных выражений – с вашего разрешения, про регулярки я расскажу чуть дальше.
- Проверка кода ответа сервера – при парсинге страниц из выдачи программа может одновременно пинговать эти адреса и смотреть, какой ответ отдает сервер. Очень полезно, чтобы узнать, нет ли несуществующих страниц в выдаче или каких-то проблем с сайтом.
Набор настроек зависит от выбранного источника данных (выдача, xml или вебмастер), где настройка неприменима, то она и не отображается, чтобы никого не вводить в заблуждение.
Схожими настройками обладает и парсер Google:
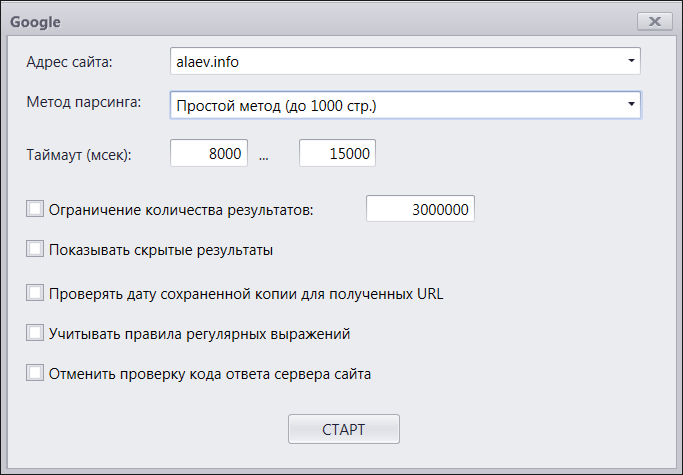
Основные отличия в том, что у Google только один источник данных – поисковая выдача. Так же в Гугле нет сортировки результатов по релевантности или дате, нет указания региона поиска (а нужна ли она?).
Зато в Google есть одна особенная настройка – «Показать скрытые результаты». Это supplemental index, в простонародье «сопли». Если эту галку установить, то в запрос добавится параметр &filter=0 и будут парситься не только страницы, находящиеся в основной выдаче, но вообще все известные Гуглу страницы сайта. Один из примеров использования данной опции: можно просканировать сайт, спарсить выдачу Гугла без показа скрытых результатов, а потом сравнить – сразу будет видно, какие страницы вашего сайта не попадают в выдачу и не ранжируются. При помощи отчета, показывающего страницы, найденные на сайте и отсутствующие в основной выдаче Google, станет понятно, над какими страницами на сайте надо поработать и придать им большей значимости. Если в этом списке окажутся важные страницы, значит это тревожный сигнал!
И есть еще одна, к сожалению, неприятная отличительная особенность Гугла от Яндекса – запрос к сохраненной копии для проверки даты кеша является равнозначным запросу к выдаче, то есть запрашивает капчу при любой подозрительной активности. Так что данную опцию стоит использовать с осторожностью, в отличие от Яндекса, где можно парсить «сохраненки» нонстопом.
Ну вот, программу вам показал, про парсинг поисковиков рассказал. Разве что до сих пор не показал настройки парсера сайта. Секундочку…
Возможности и настройки парсинга сайта
Вот так вот выглядит диалоговое окно настроек перед парсингом сайта:
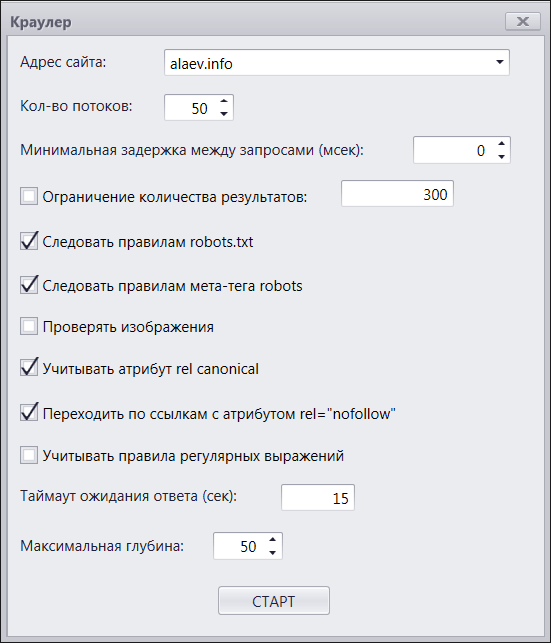
Все довольно стандартно, так что пробегусь по основным важным моментам:
- Адрес сайта – понятно, количество потоков – понятно… Максимальное количество потоков в программе – 50, это более чем достаточно. Мои эксперименты показали, что такое количество потоков адекватно держит только один сайт – это vk.com :) На контакте можно упражняться с настройками программы сколько угодно, ничего не блокируется и работает быстрее, чем вы глазом моргнете. Для обычного рядового сайта хватит 5 потоков за глаза, а то и уменьшить придется, ну, в общем, все в ваших руках.
- Следовать правилам мета robots и robots.txt – если галки установлены, то программа подобно поисковому роботу будет следовать правилам, и не будет индексировать страницы, запрещенные правилами. Если же данные галки сняты, то программа все страницы добавит в таблицу, но в соответствующих ячейках сделает соответствующие пометки о том, запрещена ли страница к индексации или нет.
- Проверка изображений – кому-то может понадобиться такая штуковина, но я ее обычно отключаю, чтобы не занимать зря поток и память. Чем эта штука может быть полена – например, поиск на сайте битых картинок.
- Учитывать атрибут rel=canonical – опять же об индексации, если галка стоит, то программа, заходя на страницу и видя там каноникал, отличный от адреса текущей страницы, не станет ее индексировать и заносить в таблицу, а перейдёт по каноническому адресу и проиндексирует только его.
- Настройка, которая показалась мне интересной, это переход по ссылкам с атрибутом rel=nofollow. Поговаривают, что поисковик не должен переходить по ссылкам с nofollow, вы согласны? Тогда и программе можно запретить это делать, просто сняв галку.
И снова мы подошли к разговору о регулярных выражениях, откладывать больше некуда, давайте и про них я, наконец, расскажу.
Использование регулярных выражений
Есть в главном верхнем меню такой пункт «RegExp» — это оно, сокращение от Regular Expressions или Регулярные Выражения. Опция для более продвинутых пользователей, хотя пользоваться ей до безобразия просто, справится и школьник. Но не суть.
Есть два вариант использования регулярок: можно прописать правила исключения или правила включения (уж не смог я подобрать другого понятного антонима к слову «исключение»). Если вы пропишете правила исключения, то все url’ы сайта, подпадающие под правила не будут заноситься в таблицу и будут исключены. Например, вам не нужно сканировать какую-то категорию или раздел сайта, или определенные служебные урлы мешаются, тогда исключения – это то, что вам надо!
Включения – это прямая противоположность, вы задаете правила и согласно этим правилам в таблицу попадают только удовлетворяющие адреса страниц.
Дотошный юзер спросит, «Ха-ха, а чё будет если одновременно использовать и то и другое? А?». Ну как че! Этот момент, конечно же, был рассмотрен нами при проектировании. Если вы укажете одинаковые правила для включения и исключения, то программа будет работать впустую, т.к. программа сначала будет искать и собирать только адреса согласно разрешающей маске, а потом сразу же отбрасывать их, потому что они попадают под исключение. То есть по шагам это работает так – сначала ищем разрешающие совпадения, потом смотрим на исключающие. Так что одновременно использовать правила имеет смысл, когда вы хотите разрешить для проверки какой-то конкретный раздел сайта, но уже внутри этого раздела исключить какие-то его части – вот так будет правильно!
Еще одна важная вещь, которая была учтена при написании алгоритмов исключения адресов – это обход краулером запрещенных страниц. Все известные мне программы для сканирования сайтов действуют так: если url попадает под запрещающую маску, то он даже не попадает в очередь, а просто отбрасывается. У нас иначе, исключающее правило лишь отменяет запись адреса в таблицу, но не отменяет сканирование самой страницы и проверку ссылок на ней. Таким образом, сайт при любом раскладе будет просканирован целиком и полностью, но просто не все адреса будут записаны. Это очень и очень важно, если вы понимаете, о чем я!
Вот вроде и все об основных функциях программы.
Хотя напоследок я припас один секретик – в программе есть функция пакетного удаления url-адресов из индекса Яндекса! Для этой цели в панели вебмастера Яндекса есть специальный инструмент. Им можно пользоваться и вручную, только поштучно вбивать пусть даже 50 урлов задача не для слабонервных. Зато с ComparseR – только составил список, ctrl+c, ctrl+v, ок – все готово за три клика для любого количества адресов!
А можно попробовать, сколько стоит, как купить?
Конечно, у программы есть промо-сайт — parser.alaev.info — да-да, выдерживаю единый стиль в цветах и оформлении!
Стоимость одной копии программы составляет 2000 р. Правила и процедура покупки подробно описана на специальной странице. В этот раз я решил продавать по одной лицензии для активации одного компьютера, но и стоимость так же снизил.
And one more thing...
Та самая крылатая фраза, которую говорил Стив Джобс, когда в финале своего выступления хотел преподнести аудитории сюрприз. У меня тоже есть для вас сюрприз – ЭТО ДЕМО-ВЕРСИЯ!
Ну все, друзья, более я вас не задерживаю. Спасибо вам за внимание!
Надеюсь, я вас порадовал моей новой разработкой. Жду от вас вопросов, интересных предложений и других комментариев.
До связи!

спасибо! аналогов нет я так понимаю.
Да, аналогов я не видел, не знаю таковых. Если найдете что-то подобное, дайте знать :)
Грац с релизом! :) Был бета тестером FastTrust и ComparseR — буду и еще других от АлачЪ'а и Ко ^_^
Спасибо! Уверен, это не последняя моя программа, так что еще обязательно что-нибудь потестим :)
Саша, добавь в парсер инфу по количеству на странице тегов h1-h6, а то ни в одном паблик парсере этого нет. В НетПике только h1, в лягушке h1-h2. Для проверки индексации оно не критично, ясное дело, но при проведении аудитов может быть ползено.
Просто количество тегов H1-H6 на страницах?
Раз уж софтина все равно получает контент [условно] всех страниц, то можно прикрутить некий "seo анализатор контента". Вроде автоматического определения фокус-слова для страницы, присутствия ее в title/description/keywords/h1-h6/тексте страницы; вывода некоего значения общего соответствия конента страницы фокус-слову, в процентах.
Это уже что-то из другой оперы. Иногда глазами-то сложно определить то, о чем вы говорите, а уж как-то автоматически — это еще менее точно, чем гадание на кофейной гуще :)
Для Гугла стоит добавить возможность выбора регионального домена: google.ru, google.com.ua и другие. В них выдача разная, для жителей всех стран кроме России — это очень нужно.
Да, это есть в планах, добавим обязательно. Так же как и добавим парсинг yandex.ua, например.
Не совсем понятно зачем платить 2000 рублей при бесплатных Xenu Sleuth и пр.
Если прочитать внимательно, то станет все совсем понятно.
Добрый день. Вопрос следующего типа. Находит ли программа поддомены. У меня проблемма, что в выдачу попадают не мусорные урл, а целые сайты-дубли на поддоменах...из-за кривых рук программиста. Возможно ли найти поддомены? Спасибо.
Пока целенаправленно домены исключаются. Но сделаем настройку парсинга при которой домены не будут исключаться из выдачи!
Спешу сообщить, что обновили и перезалили дистрибутив демо-версии! Теперь работает.
Еще раз прошу прощения за такой нелепый косяк!
Подскажи, как получить список страниц, которых нет в индексе яши или гугла? Какая должна быть последовательность действий?
Сначало crawl потом поисковоик, а потом в сайдбаре обновить данные и смотреть уже в строке не в индексе?
При crawl или парсинге поисковика, система спрашивает стереть ли данные — и соотвественно чистится везде, или я что-то не так понял7
Парсим сайт, парсим поиск — можно парсить одновременно параллельно сайт, Яндекс и Google. При первом запуске стереть данные не просит. Не забывай переключать вкладки "Краулер", "Яндекс", "Google".
После этого в сайдбаре обновляешь статистику и смотришь отчеты.
Супер, FastTrust очень экономит время и деньги. Надо будет и этой прогой обзавестись :)
Бро ну наконец-то! ))) Красивая иконка ура! )))
Поздравляю!
Очередная полезная программа.
Надеюсь это только начало и дальше перерастёт в сервис!
Саш, либо я что-то не понял, либо демка не имеет ограничений. я уже отметку в 2000+ страниц прошёл.
Спасибо!
Так же надеюсь на сервис в будущем :)
PS Для парсинга своего списка страниц или sitemap.xml ограничений нет, однако, скорее всего, они появятся в будущих релизах так же.
А для тех кто участвовал в краудфандинге? Когда будет разослан софт в обратном письме, после того как выслали свои HID?
Да, только не в письме а на форуме. Я два раза так-то рассылку делал :)
Можно поподробнее об отчёте "Страницы, найденные в Яндексе, но не обнаруженные на сайте"?
Не совсем понятно предназначение этой информации. Это просто лишние страницы в индексе, которые следует закрыть от индексации?
Кстати, в демке некоторые страницы анализируемого сайта из этого отчёта нормально открываются.
Это страницы, которые не удалось найти при обходе сайта. Вариантов такого поведения несколько:
1. Это страницы попавшие в индекс по ошибке или в результате какой-то ошибки, которая была поправлена, но ее последствия остались.
2. Страницы оставшиеся от какой-то старой структуры или старого сайта.
3. Вдруг у вас на домене кто-то дорвей замутил, а вы не в курсе? )
Вариантов вообще дофига!
Чаще всего найденные в отчете страницы подлежат удалению. Главное понять, почему они есть в выдаче, а на сайте не находятся.
Да, действительно. Спасибо.
Было бы замечательно, если на вкладке Структура было отмечено количество и/или доля проиндексированных страниц по каждому разделу.
Очень полезная прога. Респект!
И экспорт Структуры тоже бы не помешал :)
В каком виде это должно экспотироваться? Прям вот так же, как оно выглядит в программе, только перенести в таблицу Экселя?
В идеале, как в программе — с развёртыванием разделов. Но, не понятно пока, как это можно реализовать в экселе.
Я думаю в экселе будет геморно. Может сделать в таком случае, на базе HTML. Там легко и просто, можно сделать вывод информации в новом окне по нажатию на интересующую нам ссылку.
(На словах конечно просто, но я не программист, возможно сама реализацию будет сложно)
Но это всё моё мнение, вдруг послужит толчком к идее.
Записал, обсужу с разработчиками. Они точно скажут, как и что можно реализовать, а что нет.
Проверка индексации методом ввода урлов из списка в Яндекс по одному есть/планируется?
Можно точнее? Хочется видеть форму, куда указываешь URL'ы жмешь кнопку проверить и они начинают пинговаться, так? Или как-то иначе?
Примерно так, да.
Загружаешь список в программу и урлы проверяются по очереди простым вводом урла в Яндексе. Есть на первом месте — значит страница в индексе. Это более точный метод, чем site:, если верить сеошникам викимарта.
Поштучно то надо оператором url: проверять.
Ладно, сделаем такую возможность.
Привет!
А на Mac OS под VMWare заведется?
Возможна ли смена HDID? Дело в том, что иногда, VMWare меняет ID системы, что крайне неприятно. И если с кейколлектор эта проблема решается автозаменой HDID, то как быть с этой программой?
Заведется или нет, стоит поюзать демку. Но FastTrust под виртуалкой нормально идет, так что и эта программа пойдет.
Смотря какие ID система меняет. Если что, договоримся о замене. Автозамены у нас пока нет.
Такой вопрос, сейчас решил протестировать ДЕМО версию. На сайте где-то 500 новостей. Следовательно, должно быть 500 ссылок. Но так как я использую демо версию, 300 это потолок. А в чём тогда может быть причина, почему всего только 244 страницы в результате оказалось а не 300.
Это не претензия, а интерес.
Мне тоже интересно. Это парсинг сайта именно? Не выдачи? А можно адрес в студию?
Да, это именно парсинг самого сайта. Я вам в ВК урл скину.
Интересная особенность. Я выяснил, если включить в проверку изображения (галка "Проверять изображения"), то будет ровно 300.
Так а смысл с изображениями, когда должно быть 300 к примеру ссылок?)
Мне вот просто интересно, в полной версии в моём случае тоже будет 244 показывать)
В полной версии нет никаких ограничений, хоть 5 млн спарсит, хоть 10, если комп потянет!
Было бы круто, сделать мини поиск (по парсингу) в программе.
К примеру, чтобы не искать нужную страницу (в ручную, скролить), чтобы посмотреть её анализ, просто ввести часть или полностью её название, после чего выводится результат.
К примеру как в кейколлектре.
Да, сейчас это есть, но надо более очевидным сделать возможность. Пока что просто жми правой кнопкой на заголовок столбца любого, там пункт "Show search panel".
Добрый день. "После парсинга сайта и выдачи поисковиков можно будет посмотреть отчеты: страницы, которые были найдены на сайте, но отсутствуют в поиске и наоборот, страницы, которые нашлись в выдаче, но не были найдены при обходе сайта. Такие отчеты доступны отдельно для Яндекса и Гугла."
Я немного не понял, мне нужно самому определить, что есть на сайте, а чего нет в поиске? Или это как-то визуально видно. Для 1000 страниц проверять и сравнивать, это сильно.
Отвечу за создателя.
Сейчас проверил, да, пока нельзя создать отдельный отчёт — (к примеру, сохранить отчёт отсутствующих страниц в поиске) сохраняет весь проект...
Было бы славно чтобы можно было сохранять)
Программа показывает какие страницы есть в поиске, но нету на сайте и есть на сайте и нету в поиске. (Вы просто нажимаете на нужный раздел в статистике программы и получаете список.
Советую вам скачать демку и протестить — так сразу всё поймете =)
Да, Артем все правильно сказал. Но есть одно но :) В обновлении 1.0.2 есть возможность экспорта данных, отображенных прямо сейчас на экране, соответственно, вы можете экспортировать данные по любому фильтру или отчету!
Попробовал собрать страницы сайта методом Яндекс.Вебмастер — вернул 1000 штук.
Через XML.Яндекс (сначала минимум запросов, потом обычный) картина такая:
19:29:42 — Парсинг Яндекс завершен!
19:29:41 — Ошибка выдачи Яндекс: Запрошен слишком далекий документ.
19:29:41 — Парсинг Яндекс (*****.ru/*)
19:29:41 — Парсинг Яндекс запущен...
19:28:50 — Парсинг Яндекс завершен!
19:28:49 — Ошибка выдачи Яндекс: Запрошен слишком далекий документ.
19:28:41 — Парсинг Яндекс (Нашлось 8 тыс. ответов)
19:28:40 — Парсинг Яндекс (*****.ru/*)
19:28:40 — Парсинг Яндекс запущен...
18:59:22 — Парсинг Яндекс завершен!
Страниц на сайте — около 9 тысяч, собраных краулером. Я.Вебмастер показыват страниц в поиске: 8004.
А после попробовал простой метод (до 1000 страниц), ответ тот же:
19:35:15 — Парсинг Яндекс завершен!
19:35:14 — Ошибка выдачи Яндекс: Запрошен слишком далекий документ.
19:35:14 — Парсинг Яндекс запущен...
И под конец — парсинг выдачи Я. Ввел капчу руками раз 10:
20:14:21 — Парсинг Яндекс завершен!
20:09:22 — Парсинг Яндекс (8 тыс. ответов)
20:09:20 — Парсинг Яндекс (*****.ru/download*)
Но ничего не собрал.
Нужен адрес сайта, чтобы понять, в чем же дело!
А будет ли программа работать в линукс под wine?
Как на счет взять и проверить демку?
Вообще, думаю, что под вайном не заведется. Хотя, может, вайн с тех пор, когда я его юзал в последний раз (в 2009) сильно улучшился, но не уверен в этом.
А как часто планируете обновлять софт?
На первых порах, конечно, да. А так по мере выявления багов и предложения нововведений со стороны пользователей.
Запустил демку, потестил на своем сайте — вместо тайтлов знаки вопроса, наверное с кодировкой траблы, как ее указать?
Покажи сайт, посмотрим что к чему.
Сначала запускаю парсинг во вкладке краулер, потом яндекс.
На вкладке яндекс и гугл кол-во страниц одинаковое (хотя в пс страниц в разы больше, чем показывает программа)
Там по идеи должны показаться страницы, которые остались от старого сайта, но я их не вижу.
Может я просто логику работы не понял, прошу помощи.
Из описания ничего не понятно. Если пошагово распишете, что и как делали на конкретном примере, тогда я смогу объяснить что и почему происходит.
Сейчас просканировал alaev.info, сначала краулером — там собрал 300 страниц.
Потом пошел на вкладку яндекс, указал alaev.info — а мне добавляется туда страницы из моего первого проекта (создавал новый проект, я вообще хз как туда попали страницы)
Такую вот ошибку выдало :(
version 1.0.1
UnhandledException
Duplicated primary key.
...
Сейчас актуальная версия 1.0.3. А вообще мне надо знать обстоятельства, при которых ошибка случилась.
Бла бла бла! Тестируем!
Тестируем еще раз!
Вот вот! Два!
Вчера оплатил, отписал на почту. В ответ — тишина. Дайте обратную связь.
Отвечал, проверьте папку Спам, пожалуйста. Перевышлю.
Письма нет, в спаме тоже нет(
При сканировании сайта с указанием User Agent YandexBot, на выходе я должен получить количество загруженных страниц примерное равное количеству загруженных страниц по панели Вебмастера? Проверил на 2-х сайта, софт сканирует в разы меньше того, что я вижу по панели Вебмастера. Почему так?
Поясню. В панельке ЯВ есть данные: количество загруженных страниц( для примера возьмем 100), количество исключенных страниц(для примера 50), страниц в поиске — 20. Вычитая из загруженных страниц исключенные мы получим сколько страниц в идеале должно быть в индексе. В нашем примере, их должно быть 50, но в индексе 20 (почему 20, а не 50 вопрос другой). Разве ComparseR не должен на выходе показать мне все урлы, со статусом 200ок, равное количеству «идеальному» в индексе по панельке? На практике этого не увидел.
Ничего подобного. Это просто выбор User Agent, и это говорит программе о том, что надо следовать правилам в robots.txt, которые прописаны для Яндекса (User-Agent: Yandex). И не более того.
Я придумал, как можно экспортировать структуру сайта — есть 2 варианта, оба через Эксель:
1. По-умолчанию скрывать страницы с уровнем вложенности более одного. Эксель умеет скрывать строки и столбцы. При необходимости пользователь их можно раскрыть.
2. Распределять страницы по столбцам в зависимости от вложенности страниц сайта.
Мне кажется второй удобней. Буду признателен, если будет такая возможность.
Спасибо, увидел в новом релизе свои пожелания:)
Жду новых предложений и пожеланий! Всегда рад :)
Заценим сие чудо.
Подскажи, пожалуйста, есть ли возможность как-то это исправить? KIS2015 удалил экзешник, назвав его PDM:Trojan.Win32.Bazon.a
Переустановите программу из дистрибутива и все :)
Переустановил) KIS успешно еще раз завалил экзэшник в папке, куда он установился)
Удали идиотский антивирус, делов-то. В конце-концов, добавь в исключения.
Добрый время. Спасибо за софт.
Вопрос:
1. Сайт крупный (более 10 000) страниц. Прогнал краулером, хочу спарсить индекс гугла методом перебора (как я понимаю который работает по сформированной структуре). Начинает перебирать по разделам (работает антигейт). Происходит ошибка распознания капчи, парсинг останавливается и преходиться начинать все заново, в итоге из-за ошибки капчи не могу спарсить данным способом. Пробывал регулярками в "Совпадения" указывать определенные разделы (пример — http://site.ru/razdel/podrazel/.*), но парсер их игнорирует (в настройках галку включал). КАК БЫТЬ ? (если имеет значение сайт в зоне .by)
2. В чем отличия между "метод перебора", и "метод перебора минимум запросов" ??
3. Парсинг гугла по умолчанию как я понял идет на поиск в основном индексе? (/&)
4. Пересканирование отдельных урлов влечет за собой неожиданно повторный обход сайта по каждой глубине, что занимает уйму времени. Как быть?
5. Когда ждать подробной документации по настройкам?
А вы демо версию пробуете? Мы ее сегодня-завтра обновим, там ряд новых возможностей и исправления багов.
1. Возможно, как раз с обновлениями связано. Надо пробовать новую версию.
2. Это долгий вопрос, надо его описать на промо-сайте, комментария не хватит.
3. Нет, обычный индекс без /&, но запрос хитрый все равно, чтобы исключить поддомены. Вот такой:
https://www.google.ru/search?q=site:alaev.info+(inurl:http://alaev.info+|+inurl:https://alaev.info+|+inurl:http://www.alaev.info+|+inurl:https://www.alaev.info)&num=100
4. Да, по умолчанию так. Сделаем возможность обхода только обозначенных URL.
5. ХЗ :( Но я постараюсь родить ее. Извиняюсь за халатность...
1. Нет, платную версию (1.0.12) и вот такие неудобства(
2. Ждем тогда, а то методы представлены а специфика их работы подробна не описана(
3. спс
4. Оч нуна! а то для моего крупного сайта, иногда валятся ошибки с истекшим временем ожидания или 500 (понимаю что проблемы сервака), но все равно, их может набраться под 200 штук и когда программе нужно для каждой ссылки из 200 запускать заново обходить краулер по всему сайту где с несколько десятков тысяч документов — это может растянуться в десяток часов =(( (хотелось бы по этому вопросу что-то типа как в жабе и xenu )
5. :)
И еще есть вопрос, работает ли такая логика:
Запускаем парсинг сайта в одной ПС 1 метод
Запускаем парсинг сайта в одной ПС 2 метод (предлагает перезаписать данные — отвечаем нет)
Запускаем парсинг сайта в одной ПС 3 метод (предлагает перезаписать данные — отвечаем нет)
Будет ли в таком случае собираться наиболее полная информация о данных в индексе в исследуемой ПС и не будут ли данные каким-то образом теряться с прошлых проверок?
И осуществляется ли проверка дубли URL в списке при повторных запусках другими методами?
Совершенно верно. Я сам так делаю. Парсинг одной методикой, парсинг другой методикой, потом еще меняешь (для Яндекса) сортировку (по релевантности/по дате), потом еще парсишь из панели вебмастера. Ну, логика понятна. Это как раз и даст наиболее полную картину.
Зашел на ваш блог от Борисова. Отлично, что есть такие люди в интернете, как вы! Пройдусь, почитаю информацию, она не будет лишней.
Привет! А скидок не намечается, хотя бы для пользователей "Фаста"?
Привет! Может я не до конца разобрался с софтиной, но некорректно определяется наличие страницы в Яндексе и на сайте. Открываю вкладку "Найдено в Яндексе, но не обнаружено на сайте", а на деле оказывается что на сайте страница есть. Для Гугла такая же беда.
Предлагаю внедрить поддержку прокси, чтоб можно было парсить выдачу Гугла для больших сайтов (ну и Яндекса тоже).
Это значит, что при обходе сайта эти страницы не были найдены. На них просто нет нигде ссылок.
В этом и дело, что страницы на сайте может быть и есть, но найти их невозможно пользователю — и это проблема сайта.
Привет!
Сделайте генератор html карты сайта на основе собранных ссылок.
Т.е. просто на выходе собрать html документ, содержащий все ссылки на страницы, собранные при обходе сайта?
Да, именно так
Это очень интересный инструмент, но не хватает очень важно инструкции. Допустим мы собрали пачку URLов, которых нет в индексе Яндекса. А как узнать причину? Почему именно эти URLы не проиндексированы? Хотя ссылки на них стоят и времени прошло достаточно. Почему Яндекс посчитал их недостойными индекса? Без этого смысла в программе не вижу т.к. все остальное делают другие программы, которые были указаны вначале статьи + netpeak spider и прочее.
>> Почему Яндекс посчитал их недостойными индекса?
Подсказать, где ключи от квартиры, где деньги лежат? :)
А в чем тогда смысл программы? Вычленить непроиндексированные страницы и всё? Я так полагаю, это всего лишь этап на пути к улучшению сайта и его полной индексации.
Просто для сайтов с сотнями страниц такой инструмент не нужен. Можно все вручную легко проверить. Такой инструмент нужен для сайтов с десятками и сотнями тысяч страниц. Вот на примере своего форума могу показать подобный алгоритм. У него несколько сот тысяч страниц. Я собираю их список через Netpeak Spider. далее загоняю в плагин Wink'а для сапы (он работает автономно) и проверяю на проиндексированность. Далее списки отправляю в Excel и работаю уже там. Согласен, что программа упростит это, но опять же покупать ее только ради упрощения бессмысленно. Нужен инструмент (мануал и т.д.) который бы позволил дальше работать, вычленять причину непроиндексированности больших групп страниц и устранять эту причину. Либо я просто не понимаю философию программы и прошу ее прояснить.
Можно добавить возможность работы через несколько прокси, т.к. если Яндекс парсится вполне сносно, то Гугл после 300-500 пропарсенных страниц блокирует доступ.
Можно добавить инструмент для нахождения страниц в дополнительном индексе Гугла. В принципе он есть — но так нужно парсить Гугл два раза.
Недавно пробежался товарищу по сайту. Софт нашел много страниц которых якобы нет в Яндексе. При ручной проверке оказалось что в Яндексе они проиндексированы.
Почему то проверка страниц идёт не через XML а через обычный поиск
Александр, добрый вечер! Написал Вам по поводу смены HID. Ответьте, пожалуйста, на почту.
Здравствуйте!
Было бы неплохо включить сбор внешних ссылок.
Поддерживаю. информация по внешним ссылкам была бы очень кстати. Например, внешняя ссылка — страница источник.
Алаичъ, а собирать исходящие ссылки с сайта программа не может? Не нашел в функционале.
Нет, не было такого. Надо?
Поспрашивай у народа. Лично мне не помешало бы, толкового сервиса по проверке исходящих ссылок со всего сайта нет. Во всяком случае я не встречал.
А если вдруг хакеры повшивали ссылки, было бы не плохо их найти.
Думаю данная функция не помешает
Эта функция есть уже!
Проверка в при включенных настройках Я.Вебмастера идёт через сканирование выдачи? Почему так?
Так не может быть, что-то сделали не так значит.
http://joxi.ru/EA4pV5YhaBelAb
http://joxi.ru/Vm6bVWYh7PeMmZ
У меня вот уже недели две такое несовпадение. Раньше было всё в порядке. В чём может быть причина?
При парсинге из Вебмастера должно ли отображаться в строке состоянии вот такое: http://joxi.ru/1A59V6YTQ3qnAE?
Доступы в аккаунт Вебмастера в настройках программы верные.
Для парсинга через Вебмастер нужно заполнять все поля в этой форме?
http://parser.alaev.info/data/uploads/about/comparser_settings_1.png
В вебмастере у меня 5809 страниц:
при парсинге Вебмстера Простым методом (до 1000 стр) в строке состояния была указана цифра 5809, но в итоге было показано 890 стр;
при парсинге Методом структуры — показано 7683 стр;
при парсинге Методом перебора — показано 5094 стр.
Как мне получить 5809 страниц в программе? Я не понимаю)
Аккаунт Я.Вебмастера был заблокировал за парсинг сайта через компарсер. Настройки не менял, такое в первый раз. Александр, такого раньше не замечали?
У меня было однажды. За совсем бесчеловечный парсинг наказали :)
Надо писать Платонам с покаянием и обещанием более так не делать, в течение 2-3 дней разблокируют.
Как вариант — делегировать права на сайт на левый аккаунт и парсить там, если заблокируют — не жалко.
Здравствуйте.
В обновлении 1.0.48 была представлена следующая возможность:
"Добавлена возможность ручной проверки индексации страниц в Яндексе с использованием сервиса Яндекс.XML"
Не могли бы Вы мне объяснить, как пользоваться данным функционалом.
Например, могу ли я проверить любой список имеющихся страниц? Это должны быть страницы одного сайта или в списке могут быть любые страницы разных сайтов?
Или эта функция применяется для страниц сайта. которые получены в процессе парсинга?
Меню — Настройки — Яндекс — Использовать XML...
После этого выбираем нужные страницы, правой кнопкой тыкаем — Проверить индексацию...
Пробовал разные сайты на разных настройках (кроме xml). Парсит страницы в индексе Яндекса в кол-ве не более 900-1300 страниц. Как быть?
В программе есть строка в разделе ошибок "URL и rel="canonical" не совпадает". Почему это является ошибкой и почему они должны совпадать? Вроде как логично, что они должны быть разными, для этого их и указываем, чтобы вести на другую страницу, а не на эту же. Какой смысл вешать каноникал сам на себя?
Или я просто не понял как реализована функция проверки этой ошибки в программе. Объясните плиз.
Это не ошибка, а предупреждение. Вдруг там ошибка при настройке. Каноникал для страниц на всякий случай надо ставить сам на себя, чтобы разные непредвиденные обстоятельства (например, параметры) не наплодили дублей.
Так я так понял, что парсинг из yandex.ua и google.com.ua еще не возможен?
Планируете добавить или нет?
Все возможно, перед запуском парсинга можно выбрать.
Google не хочет парсить, антикапча не помогает —
Ошибка: The remote server returned an error: (403) Forbidden.
Трассировка: at System.Net.HttpWebRequest.GetResponse ()
at Project.MainWindow.EchYSu8HDHmUHtQmQh (Object )
at Project.MainWindow.vcYAE69D9 () in G:\Freelance\free-lance.ru\ComparseR\Project\Google.cs:line 588
Demo или Full версия?
демо
Пробую парсить сайт dveri-super.com краулером — ни в лоб, ни через sitemap, ни через задание списка страниц вручную — никак не удаётся получить список страниц сайта. В чём может быть проблема?
Очень странный сайт, там в верхнем меню ссылки не ссылки, сами посмотрите. Что-то с ним очень не то. А обращение к sitemap.xml блокируется сервером. Что это за движок или платформа?